很多人对IF功能一见钟情。
如果有很高的判断力并煞费苦心(重复嵌套),
但是面对情敌,自卑是必然的。
01、萝莉MIN和御姐MAX面对极值问题时,IF既没有MIN那样娇小,也没有MAX那样霸气。萝莉敏和御姐MAX是IF生活的敌人。
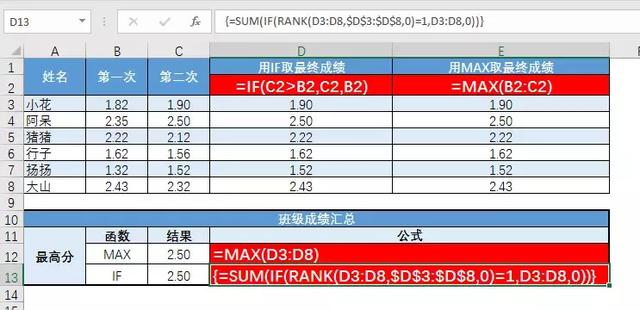
以MAX为例:立定跳远考试有两次获得最高分的机会。
不屑如果:简单,我有个判断要解:=如果(C2 >;B2、C2、B2)
MAX傲娇:哼,完全不用评判丧族:=MAX(B2:C2)
如果可以的话,试着在班上取得最高分::=MAX(D3:D8)
如果有困难;我会找人去,你等着:
{=SUM(IF(RANK(D3:D8,$D:$D,0)=1,D3:D8,0))}
面对绝对值或者偏差,ABS这种正能量女神也来抢镜!
如果:我善于判断,能拨乱反正;
ABS:在我眼里没有负面价值。
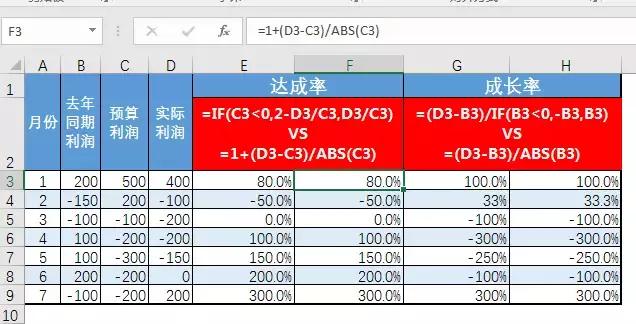
例:计算利润达成率和增长率。当分母为负时,如何求解?
在区间判断方面,“大眼睛”的VLOOKUP也会卖可爱(模糊搜索)与IF竞争。在这方面,IF只能由反复的判断来支持。
举例:一个商场促销,如何根据消费金额找到对应的折扣力度!
VLOOKUP:我闭着眼睛都能解决这个问题:=VLOOKUP(A11,$A:$B,2,1)
如果:嘿,我的化妆隐形眼镜呢?
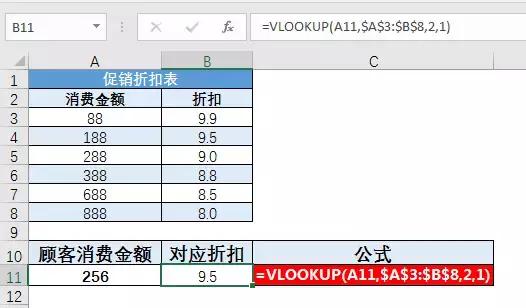
如果说如果用{1,0}来构建区域,函数会有更多的变化(比如反向查找),那么选择{1,2,3,...}将无愧于百变魔女的称号,因为它可以建造更复杂的区域!
示例:通过反向查找案例,比较IF{1,0}和CHOOSE{1,2,3}在结构区域中的区别。显然,CHOOSE可以结合更多的领域。
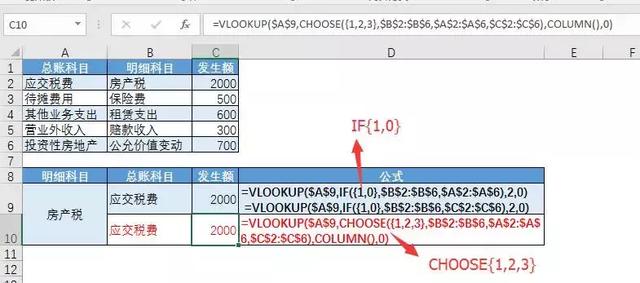
例:在折扣率随采购金额快速增加的促销情况下,如何计算供应商获得的折扣率?
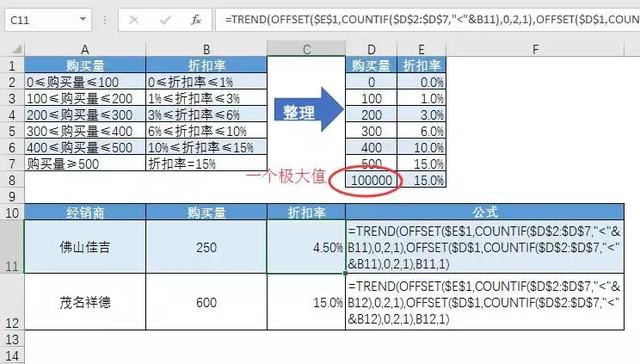
趋势是用于线性求解的统计函数。根据两组或多组已知的X值和Y值,找出新的X值对应的Y值。
在这种情况下,我们只需要让TREND知道供应商的采购金额在哪个区间(即供应商的采购金额在哪个细分函数中)。
这时候我们用OFFSET函数来实现。根据D2小于B11的数个数:D7,我们取D1和E1为向下偏移的行,分别取一个两行一列的区域,为分段函数的两个端点。
在这种情况下,D2: D7中有0,100,200,3个小于B11的数字,那么第一个偏移量从E1下移3行到E4,E4: E5从两行一列中删除。类似地,第二个偏移量返回D4: D5。(D4,E4)和(D5,E5)确定B11所在的分段直线。
最后,TREND返回已知x值B11对应的y值的4.5%。
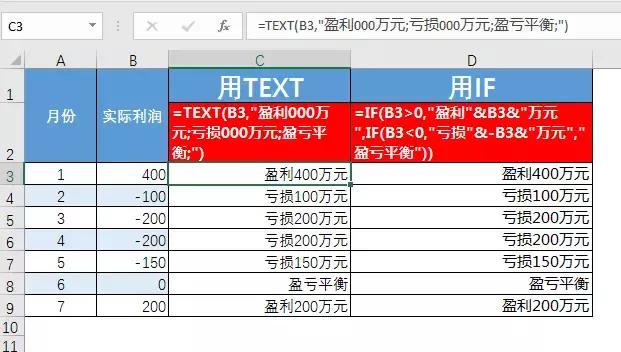
例子:把数字变成文字描述,文字比IF简单多了。
=正文(B3,“盈利0万元;亏损0万元;不赔不赚;”)
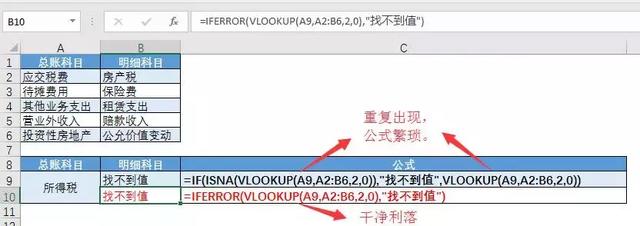
IFERROR作为职场中的“白顾靖”,做事总是简单利落!
示例:当VLOOKUP找不到对应的值时,IFERROR比IF更简单,用于容错。