编辑导语:决策引擎是一个工具,可以用来支持企业在客户管理(CRM)中的各种决策,可以在决策引擎上开发不同的解决方案。运营要精细化,根据产品、用户、市场的具体情况制定具体的运营措施。本文主要分享决策引擎在用户分层和精细化运营领域的应用方法,希望对你有用。

个人不太喜欢“道术”的描述。所谓强国战略,没有什么魔术,一直是我坚信的战略和指导。但不得不说,上述短文只是简单描述了精细化运营的“道术”,即为什么要做,最后怎么做以及如何控制不偏离总体目标。抛开这些,智能商业决策引擎被认为是改变了重人力职场运营模式的最重要的“设备”。
在前雇主,有一段时间,由于项目和工作的调整,我负责更新部门的决策引擎,或者救死扶伤。最近依稀记得刚接手项目的时候,被前任留下的屎山码限制,没有解释,没有PRD。作为一个接手了一家企业,习惯性地知道事情全貌的铁头宝宝,有一段时间真的是天天挠头。可以说无从下手,不明白从什么角度切入。
根据后来的了解,大部分的决策引擎,或者市面上有的,大多是基于Drools的二次封装,基于JAVA语言。或许理解太浅,但据我理解,做到了两点:①(理论上)业务和策略人员可以不用代码;②显著提高了作业效率;
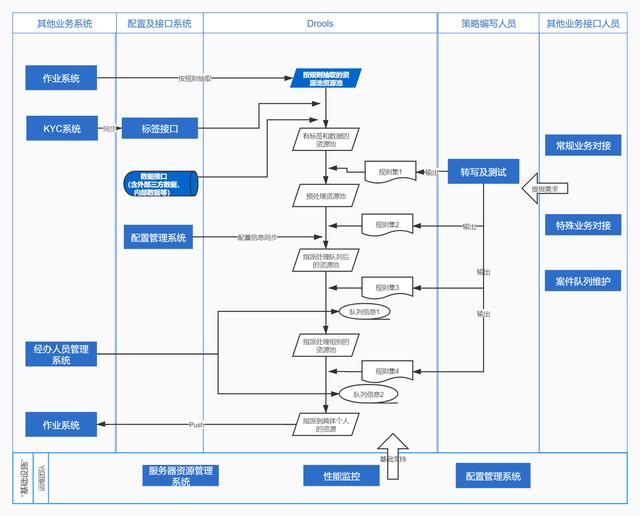
一个成熟可用的[决策引擎] 与其说是一个独立的系统,不如把我们的视野稍微拓展一下。应该包括Drools,包括KYC用户画像,KYE管理者画像,一个好的配置中心,一个好的展示页面(比如稳定的售电系统/电商推广系统),一个稳定健壮的策略/运营团队等。
在后续的业务需求中,任何一个环节和问题都会造成最终结果的偏差。
依稀记得当时在找合适的教程。要么流于形式,明明是我不知道从哪里捡来的鳞爪齿智,要么就是高明却不解决实际问题的PPT,要么就是容易把目光局限在一小片。不符合一个战略部门决策引擎产品经理的需求。
本文基于DroolsWorkBench6.2/6.4版本6.2/6.4。只知道SQL/IMPALA/HIVE/PYTHON,完全不知道决策引擎和Drools。希望由于各种原因,在政策执行阶段,仍然需要通过WorkBench写伪代码的战略家/数据产品人员,能提供一个丢失的帮助,天天做好事。如果有人看到后能掉几根头发,我希望掉的头发能长在我头上。
在CSDN,“风中的意志”救了我很多头发。远方的谢谢。
一、什么是决策引擎及使用范围决策引擎(Decision engine),对于业务人员来说,在大多数上下文和语义中,指的是能够根据复杂的决策规则路由案例/客户,支持复杂的决策流和决策树规则的工具。
最常见的用法是:
至少在我浅薄的知识里,决策引擎主要扮演自动分配核心资源[客户]的角色。
通用决策引擎,不管它是否支持“拖拽”花式方法做决策树/决策流,也不管你在广告语里支持多少业务场景。大部分决策引擎都是基于Drools(基于Java的BRMS解决方案)打包的,经过优化、迭代,结合了自己的一些业务经验。
相比一些同行,案件还是手工分配。不清楚需要多少客户才能实现收入平衡。对于无法及时登录新APP查询购买产品意向的客户来说,决策引擎已经是一个比较高科技的工具了。
更何况。决策引擎,个人感觉通过常规业务管理难以挖掘业务潜力后,自然是精细化运营后需要的一个产品,主要用于频繁修改政策和禁止客户资源,而不是常规管理手段管理不好的阿布。通过引入决策引擎,您可以扭转局面。
一个好的决策引擎意味着所需的KYC客户画像水平和KYE员工管理水平。坦白说,两个长处中有一个已经可以算是优秀了,另外两个长处也算是最好的了。
KPI要靠分解、分层、分类、分级,实施的时候要靠定价、分级、量化、问责。只有这样,这些决策引擎才能发挥最大的作用。当然,这超出了本文的范围。
二、决策引擎的组成传统的决策引擎包括:
不管是看不懂产品还是看不懂策略。没事的。我还是不能理解。这部分问题还是留给技术人员去考虑。
技术相关和组件相关,这里我只想强调几点我的个人经验:

删除DRL文件、测试类、标签和赋值语句。我认为,对于战略部门决策引擎的产品经理来说,以下内容应该花更多的时间去考虑:
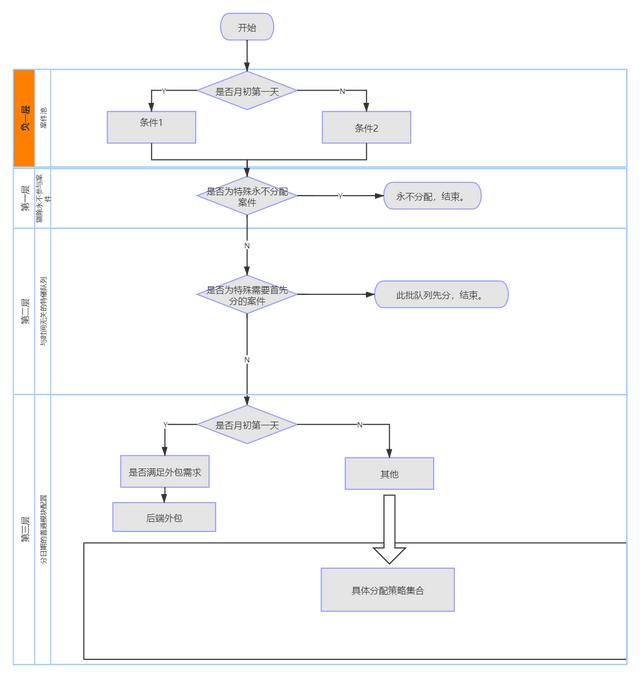
1.清晰、流畅、平衡的决策流,具有高内聚和低耦合。
作为一个BRMS工具,从某种意义上说,整个系统是为了更好地实现业务决策流程而设计的。但常规的问题是,对于业务来说,每个部门、每个小组对于客户资源的分配都有自己的考量,任何系统性的偏差几乎必然会成为业务和产品冲突的原因。
其次,在XIMND上绘制的决策树,由于技术提供的Drools的性能、规则编辑方式、其他组件不全甚至是旧版,在DroolsWorkBench上很难实现。甚至需要人肉分两个流程和决策表来处理同一个问题。这个操作违背了奥卡姆剃刀原理。每增加一个环节,出错的可能性就会更大。
因此,在写DRL文件之前,战略部决策引擎的产品经理最重要的是了解和排查当前决策流程中的问题。大概率,当增加或更换一个决策引擎时,当前的日常决策过程中存在各种各样的问题。梳理过程中发现的群体间客户冲突,要直接暴露给决策层,避免后续问题。
在具体梳理决策流程的时候,请注意不同层级之间的衔接,不同层级之间的耦合,虽然产品经理没有具体写实现代码(其实除了决策引擎的初期开发,DRL文件修改主要是产品运营写的。),但是这个原理以后肯定会方便重复,修改等等。
我们应该尊重现有的工作流程,努力改变不合理的工作流程,而不是盲目服从:在编制DRL文件或者调整决策引擎的时候,决策引擎的产品经理比任何人都更能发现现有决策流程和工作流程的问题。可能是重复判断,队列交叉,两个判断流之间的空间隙等。
可以尊重现有的工作流程,但有空余时间请进一步明确决策流程;否则,石山码的积累就变成了一个传递包裹的游戏,问题永远在一个人手里爆炸,你无法知道自己不是那个倒霉的。
2.注意与其他系统的交互和协作。
看制度,工作没有机械化;我深感任何一个战略家、数据分析师、产品经理都应该真正理解一个问题,任何一个业务,尤其是一线运营人员比较多的业务,系统之间的衔接和补充,甚至是比有多少个系统更重要的问题。重复一遍,造轮子,拓展自己的边界,算了吧。
根据经验,将与决策引擎交互的系统有:
前端展示的是操作系统、标签市场或数据管理系统、配置管理系统、(可能的)大数据平台、(可能的)智能出站机器人等。当然还有最重要的制度,人。
因此,为了解决生产问题,将有以下问题需要考虑:
决策引擎的日志应该保存到什么程度,或者日常作业的数据只能保存在操作系统的数据库中;如何减少代码的使用,以可扩展的方式与标签市场互动;当计算资源不足时,如何适当分解决策流,更高效地使用计算资源,等等。甚至,我们需要考虑如何写出完美的文档,当一线操作人员对自己的案例有疑问时,能够妥善处理。
3.成本和效率
当使用的数据是从外部导入的,或者整个系统需要收费的外部服务时,肯定会涉及到成本控制的问题。即使是为了自己的安全,也要注意每次通话的费用带来了什么。成本是否可控,是否有足够的性价比。
四、我所建议的学习路径基于之前的痛苦经历,如果你是战略部的新决策引擎管理员,建议学习和熟悉以下流程(仅针对非可视化和非商业产品):
不得不说,决策引擎的产品运营,相对于其他系统来说,是一个非常考验人的耐心和细心的系统,考虑到它对生产的巨大影响,与其他很多系统的交互,产品经理与很多群体的交互。另外,无论是运维的问题,系统的宕机,策略的重复,甚至是前人留下的代码,都会造成可能的生产事故。不了解情况的人会觉得都是你的问题。因此,建议在有选择的情况下,谨慎选择决策引擎的产品运营角色。
另外不得不说,决策引擎运行了很久,整个思路确实更相信控制论,这可能是管理决策引擎带来的思维变化。
祝所有管理决策引擎的倒霉蛋少发。
本文最初由@柴扉周刊发表。每个人都是产品经理。未经许可,禁止转载。
图片来自Unsplash,基于CC0协议。