机器心脏释放
机器之心编辑部
在今年的国际音乐信息检索学会(ISMIR 2021)上,字节跳动的海外技术团队评选出了7篇论文,涵盖了音乐分类、音乐标签、音源分离、音乐结构分析等多个技术方向。
如今,Tik Tok已经成为一个重要的音乐发布渠道。一首音乐首先在Tik Tok以短视频BGM走红,随后传播到各大音乐平台。Tik Tok神曲甚至成为许多音乐平台的重要类别。
有人说神曲能火是因为歌词和旋律简单,听多了就印在脑子里。然而,对于一个用户数量庞大、内容场景复杂多样的短视频平台来说,如何将音乐与短视频创作、互动更好地融合,绝不是一件简单的事情。

包括Tik Tok在内,字节跳动旗下的很多短视频/音乐应用已经拥有上亿的曲库,音乐片段高达数十亿。让大众音乐和大众用户更好的相互理解的是一整套语音、音频、音乐的智能创作能力,即Sami(语音、音频、音乐智能)。
在今年的国际音乐信息检索学会(ISMIR 2021)上,字节跳动的海外技术团队评选出了7篇论文,涵盖了音乐分类、音乐标签、音源分离、音乐结构分析等多个技术方向。团队成员分布在美国、英国等国家和地区,支持基于字节的产品音乐的搜索、推荐、内容创作等场景。这些技术恰恰揭示了神曲是如何炼成的。
音乐和视觉联动技术让创作变得更容易
播放几千万的变装视频,人人都可以拍。音乐与视觉效果的联动,不断激发创作者发挥无限想象力。甚至只是上传照片,不需要任何剪切编辑,就可以成为自己的“视觉大片”。这个操作简单的功能逐渐成为抖音用户的创作神器,大大降低了视频拍摄的门槛,充分展示了用户的创意。
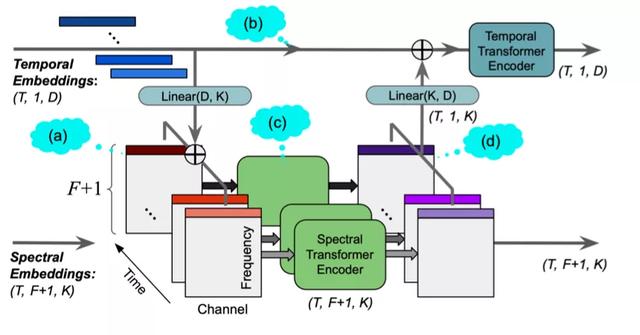
这些视频创作效果都是基于Tik Tok音频算法技术对音频内容的深度分析,结合视觉等算法。SpectTNT是专门为音乐频谱提取设计的新型深度学习模型。该技术可用于视频编辑中的声乐旋律提取和音乐结构分析,以达到更好的音图匹配效果。随着技术的不断完善,这项技术还将应用在音乐标记、和弦识别、节拍追踪等方面,各种电子游戏也将不断衍生。
ISMIR 2021论文:SpecTNT:音乐音频的时频转换器
SpectTNT模型的原理是对音频信号进行短时傅立叶变换,得到声谱图。然后,通过时域和频域的变换模型从声谱图中提取高层特征。模型本身包含残差结构,这使得底层信息能够完全流入顶层。
用算法理解音乐,让曲库不再“庞大”
当我们面对庞大的曲库时,哪首歌能唤醒此刻的心情?算法可以客观地分析和展示音乐的抽象“听觉艺术”,大大提高用户发现音乐的效率。
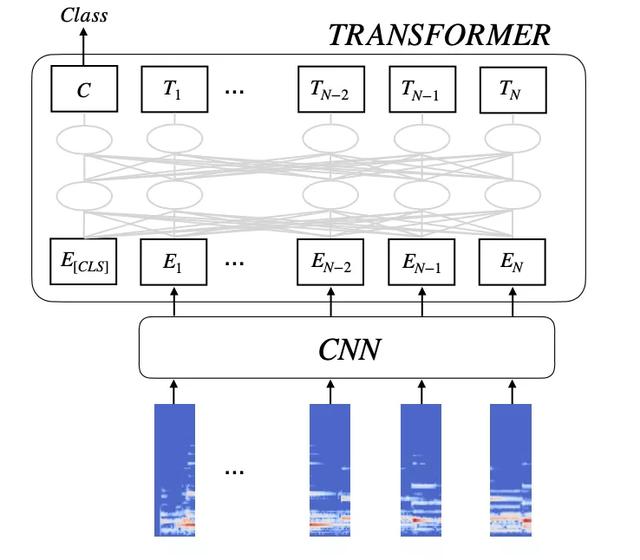
用户想要给视频找一个合适的配乐,往往会通过标签分类进行搜索。例如,体裁是最常见的分类。目前,Byte提出了一种半监督的Transformer music模型,实现音乐的标注以及海量音乐数据的流派和相似度的分类。音乐标签已经广泛应用于Resso、Tik Tok、切割和筛选产品等音乐推荐系统中。
Tik Tok音乐的标签搜索
ismir 2021论文: <半监督音乐标记转换器& gt
本文提出的半监督Transformer music模型可以突破传统卷积神经网络的一些性能,进一步提出了基于噪声学习和半监督学习的方法,充分利用了有标记数据和无标记数据,大大减少了人工标注数据的工作量。该模型已经超越了现在广泛使用的深度残差网络的性能。
语言识别技术改善了多地区和多语言用户体验
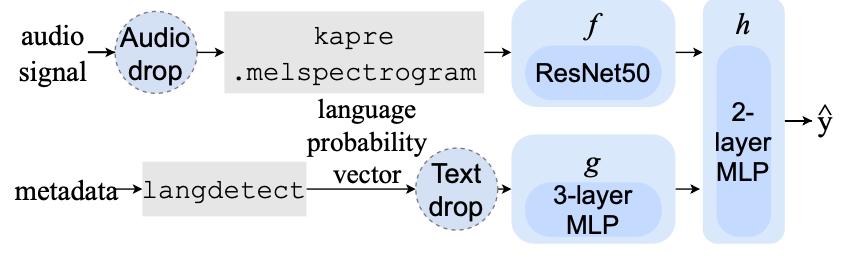
除了诸如流派和相似性的标签之外,语言类型的识别对于全球环境中的音乐应用也是非常重要的。基于字节的音乐语言识别系统,可以快速区分一首歌中中文、英文、印地语等几十个类别的构成和比例。这项技术正在为Resso的音乐库提供语言识别服务。将合适语言的音乐精准推送给用户,已被证明能有效提升多个地区、多种语言的用户留存率。
ismir 2021论文: <听、读、识别:音乐的多模态歌唱语言识别& gt
提出了支持多模态作为系统输入的字节音乐语言识别。基于音频的log Mel声谱图,通过50层深度残差网络提取嵌入特征,支持音乐的一些结构化文本数据如专辑名称作为输入。通过语言识别模型输出嵌入的特征。最后结合音频和元数据的多模态特征,通过全连接层输出预测的语言结果。
自动和弦识别帮助AI成为创意专家
基于字节的音乐理解算法除了最常见的“标签”理解模式外,还注重音乐本身的内容结构分析,这也是其音频算法的一大法宝。这项技术使产品能够更多地理解和使用音乐。
通过分析海量音乐MIDI的和弦,找出编曲的奥秘,进而输出快速、大规模、高质量的和弦片段。这项技术也为AI自动作曲系统提供了前提条件,帮助AI音乐创作出更符合大多数人喜爱的音乐作品。艾创作的音乐已广泛应用于、等产品。
ismir 2021论文: <自动和弦识别中增强连贯性的深度学习方法& gt
这项技术提出了一种可以识别音乐和弦的方法,可以识别非常丰富的和弦类型。这是一种基于神经网络的自回归蒸馏估计方法NADE。经过详细的数据测量,该方案在一些经典数据集上的和弦识别效果优于许多同类研究。
音乐表现的基本技巧:通过比较学习降低数据成本
除了理解音乐和弦,分析其他音乐结构的能力也是必不可少的。Bytes对音乐结构的理解,大大提高了UGC和PUGC视频场景中音乐的使用效率,也促使Tik Tok成为“神曲创作者”。
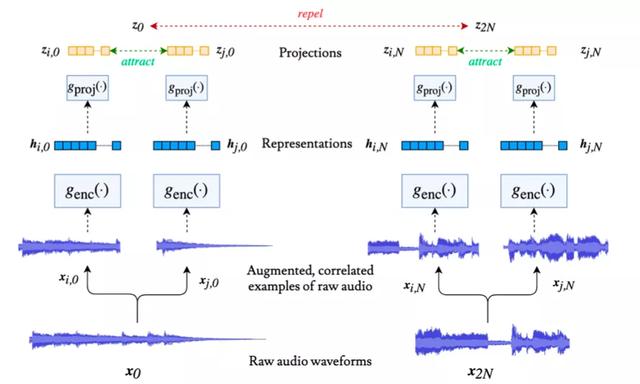
只有了解音乐是如何“表达”的,才能对音乐有更好的“结构化”分析,这可以大大降低理解音乐内容的门槛。Bytes,提出了一种新的音乐表示模型CLMR,它只需要很少的数据标注,具有很强的通用性。该模型已经应用于庞大的音乐数据集,作为音乐标注和节奏提取的重要前端,大大降低了成本。
ismir 2021论文: <音乐表征的对比学习& gt
CLMR只需要很少的数据标签,避免了监督学习中需要大量标签的情况,大大降低了数据成本。通过对音频数据进行各种增强处理,并采用比较学习的方法,训练出音乐的普适表示。CLMR表示在音频分类的许多迁移学习任务中取得了很好的效果。
一种新的音乐结构分析方法,帮助你开发你的创作潜力
人们很容易分辨音乐中的高潮,可以自己自然地把一首3分钟的歌哼到五六分钟。机器能做出这样自然的过渡吗?
该技术已经在西瓜的音频剪辑场景中使用。通过使用音乐结构分析算法批量识别音乐中的亮点和循环片段,可以让智能延伸的效果更加自然,帮助用户随意延长或缩短音乐长度,方便创作者演奏。
西瓜音乐的智能延伸
ismir 2021论文: <音乐结构特征的监督度量学习& gt
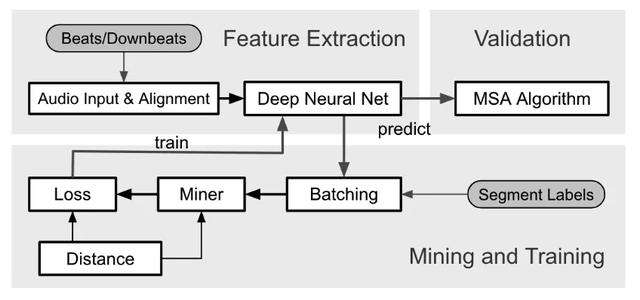
基于字节的音乐亮点检测和其他技术利用了尖端的音乐结构分析方法。音频特征由深度神经网络提出,提取的特征将被发送到数据挖掘模块进行进一步分析。本文提出的方法已应用于HarmonixSet、SALAMI、RWC等数据集。
除了上述的音乐理解技术,技术团队还提供了音乐素材制作的能力支持,增强了音乐在各种业务场景下的灵活性。
比如音源分离技术,可以把一段音乐分离成人声和伴奏。在音视频编辑场景中,支持创作者将人声换成更好的背景音乐,或者提取背景音乐换成更好的人声。声源分离是音乐信号处理中的关键技术。这种新模式的效果超过了大多数声音分离系统,并已在抖音和其他场景中使用。
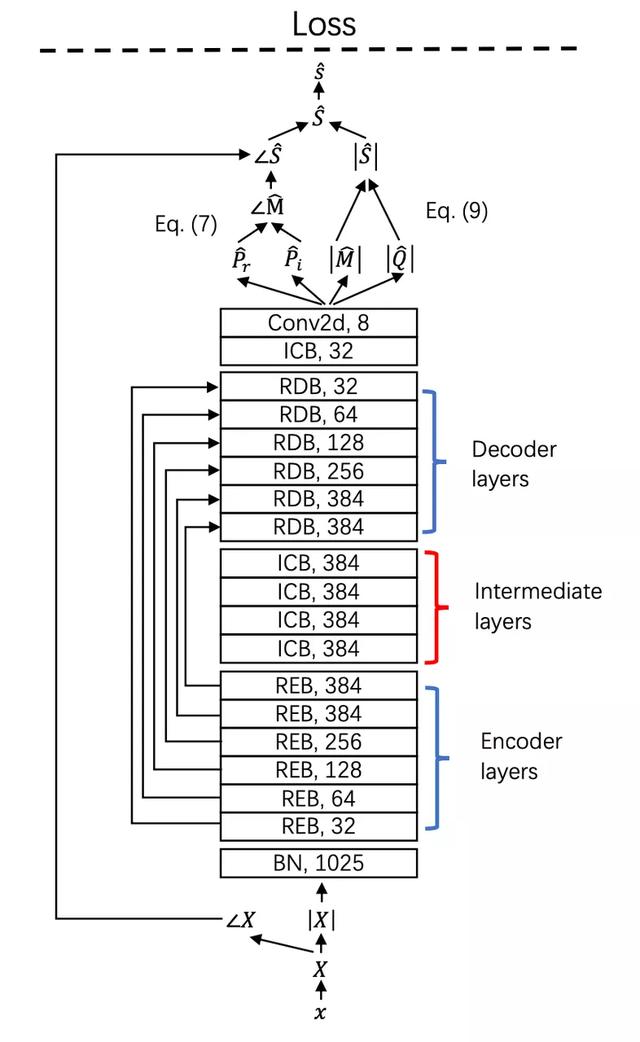
ismir 2021论文: <用于Music源分离的深度解耦幅度和相位估计>
该技术的创新之处在于作者提出了同时估计振幅谱和相位谱的方法,提高了理想掩模法的上限,并进一步提出了143层深度残差网络。实验表明,该系统的人声分离度达到了8.98 dB。