双11手淘首页几个重要推荐场景截图如下:
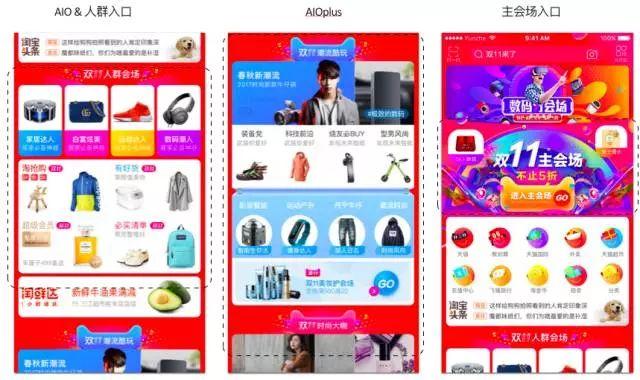
如上图所示,左边的场景是AIO综合会场,包括AIO日常场景(抢购、有货、列表等。)、双11人群聚集地、行业聚集地;中间是AIOplus场景卡综合会场,包含5个会场卡,每个会场卡都集成了行业的主要分会场和标签会场。这项业务涉及20多个日常业务以及标签和行业会议场所的分配。第三部分是你在主会场门口看到的,是双11用两个物资转盘引流主会场的。当天,在整体点击UV引流效果方面,首页依然达到了良好的对各个会场的分发效果,数据达到了数千万UV以上。
同时,今年双十一在去重和发现的推荐上做了大量的深度优化。以往多是在相似度推荐这一单一数据指标上进行优化。今年,它在匹配和排名技术中更多地采用了多步走和发现的嵌入技术,并努力增加多样性、匹配潜在兴趣、深度用户偏好等用户体验的推荐。具有一定的ctr效果保证。
举个简单的例子,之前的推荐系统在捕捉到用户对产品茶杯的兴趣后,很可能会推出更多类似的茶杯。新的推荐系统将在多阶段召回技术的基础上,通过对用户兴趣的深度学习挖掘,推荐“弱相似”但有一定概率符合用户潜在兴趣的茶叶、茶具等产品。
阿里如何利用AI搭建淘宝首页?今天就一起来揭秘吧。
一、业务技术介绍
首页个性化主要涉及图嵌入召回模型、深度交叉&网实时网络排名模型,在搜索工程Porsche &:Blink、排名服务、基础引擎等系统基础上,结合业务应用需求,沉淀图嵌入召回框架和XTensorflow排序模型平台,用于推荐其他场景,推广效果在两位数以上。
二。主页个性化推荐框架(包括匹配召回和排名)
1.一切都是嵌入深度回忆框架的矢量图
在推荐系统的开发过程中,有两个核心问题,即用户的长尾覆盖和新产品的冷启动。这两个维度的数据扩展瓶颈一直是广大推荐算法工程师面临的一大挑战。我们提出的相关创新框架基于图嵌入的理论知识,在召回阶段利用用户的连载点击行为构建全网行为图,并结合深度速度随机行走技术对用户行为进行“虚拟采样”,拟合出多层次(一般在5个以上)的潜在兴趣信息,从而扩展用户的长尾兴趣宝贝召回。同时利用基于边信息的深度网络进行知识泛化学习,在一定程度上解决了新产品面临的用户覆盖和冷启动问题。同时,虚拟样本的采样技术结合深度模型的泛化学习,大大扩展了召回率,提高了产品的多样性和发现度。
图嵌入是一种机器学习算法,将复杂的网络投影到低维空。典型的方法是将网络中的节点用矢量量化的方式表示,使节点间的矢量相似度在网络结构、邻居关系、元信息等维度上接近原节点的相似度。淘宝个性化推荐场景所面对的数十亿用户、商品、交互数据以及各种属性,构成了一张巨大的异构网络。如果网络中的各种信息能够在同一个维度空上统一建模,用向量表示,其简明性和灵活性将会有很大的应用空,比如扩展I2I计算,解决商品冷启动以及作为中间结果输出到据我们所知,业界还没有针对如此大规模复杂网络的嵌入建模的成熟应用。
本文主要介绍了我们近期在这个方向上的一些探索:针对推荐场景,基于图嵌入,提出了一种新的S图嵌入模型来嵌入数亿个商品,并将嵌入结果应用于商品的逐项计算,作为一种全新的匹配召回方法应用于手淘第一张图的个性化场景。从在线BTS的结果来看,我们改进的图嵌入I2I取得了很好的效果,在覆盖长尾用户和新生儿冷启动方面有效地扩大了匹配召回候选。
1.1.图嵌入-深度行走算法
图嵌入是最近的一个热门话题。14年,KDD的《深度行走:社会表征的在线学习》开启了这个方向的热潮。本文借鉴深度学习在语言模型中的应用,以全新的方式学习网络节点的潜在向量表示,在社交网络多标签网络分类任务中取得了良好的效果。
DeepWalk是一个两阶段算法:
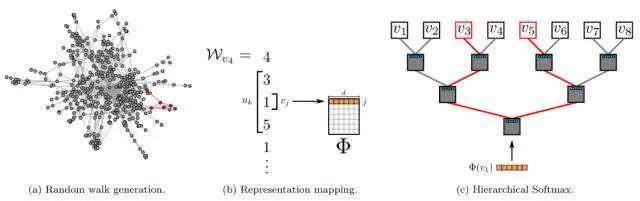
(1)构建同构网络,从网络中的每个节点开始,分别采样随机游走,获得局部关联的训练数据;②对采样数据进行SkipGram训练,将离散网络节点表示为向量化,最大化节点同现,使用层次化Softmax作为分类器进行超大规模分类;

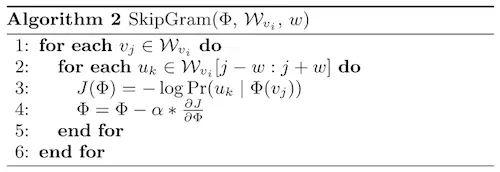
首先,从网络中抽取训练数据,每个训练数据是一个由局部相邻节点组成的序列。DeepWalk将这个序列看作语言模型中的一个短句或短语,将短句中的每个词转化为隐式表达,同时在给出短句的某个中心词时,最大化上下文词的概率,具体可以表示为以下公式:
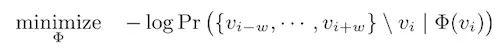
其中v_i是首字(对应于网络中的目标节点),v _ (I-w),...,v _ (I+w)是上下文词(对应网络中n阶邻居的节点)。在独立分布的假设下,可以简化为:
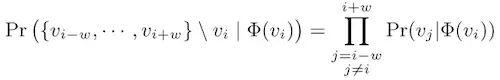
1.2、S图嵌入模型
针对推荐的场景,我们对原有的图嵌入进行了多方向的创新,通过几个版本逐步进化出了S图嵌入模型,其中S主要体现在三个方面:
我们将演进过程介绍如下:
(1)天真版
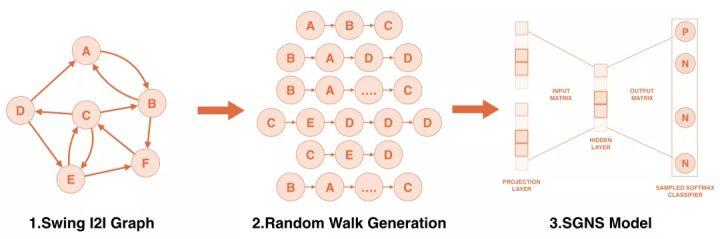
可以看出,与swing的一阶扩展相比,图嵌入的相似度计算也包含了高阶信息。
(2)序列+边信息版本

通过人工查看案例和统计得出的初步结论是,基于已有挥杆图的图形嵌入召回结果与原召回方法有较高的重复度,这在一定程度上给了我们信心,说明嵌入方法是可靠的。为了在丰富多样性和提高准确性方面有所突破,我们做了三点尝试:
(1)通过用户会话中的行为序列直接嵌入建模;
(2)在会话行为中构建整体网络图后,引入类似tf-idf的转移概率连接边,克服哈利波特的热点问题,并在此基础上进行概率抽样,构建用户行为的“虚拟样本”,以扩大后期输入深度模型的宝贝的覆盖面和准确性,使多层次扩展信息更加完善;
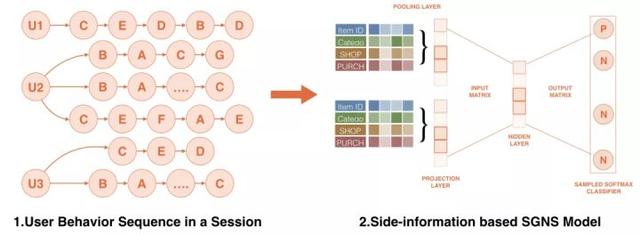
(3)多维边信息(如一级品类、叶类、店铺、品牌、材质、购买力等级等。)被引入,通过共享嵌入加池的结构嵌入到项目语义中。模型结构如图所示:
(3)最终版本
引入边信息和序列行为序列后,模型的精度有了很大的提高,但仍然面临着整个网络的嵌入参数空过大,训练样本过多(都在千亿量级以上)的问题。针对这一问题,我们根据行为序列的自然转移概率重构整个网络宝贝的加权有向图,然后将整个网络分成若干个子图,在每个子图内部进行图嵌入训练,在不同子图之间进行并行训练,以缩短训练迭代周期。网络结构如下图所示:
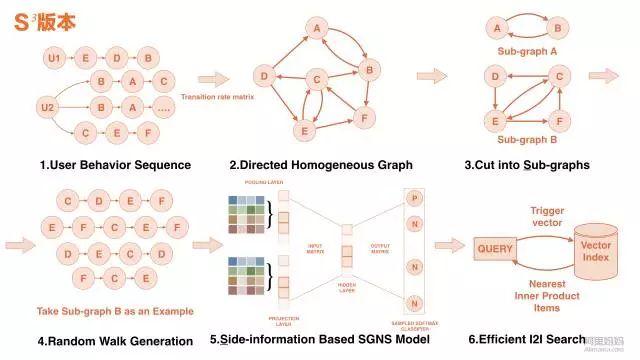
在i2i召回率的最终计算中,构建嵌入结果的查询索引,基于GPU集群批量进行高效的最近内积搜索最近邻检索。同时将整个框架放入搜索工程团队的be引擎中,实现用户从触发到嵌入宝贝的结果实时召回。
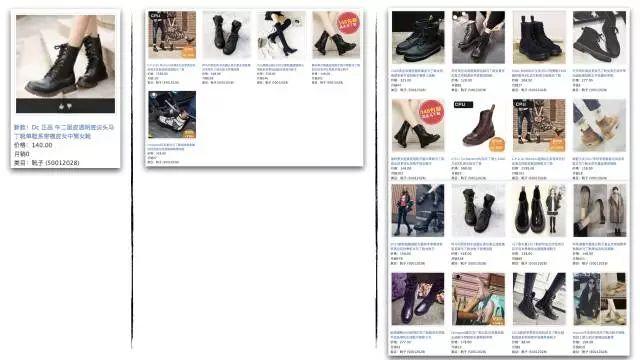
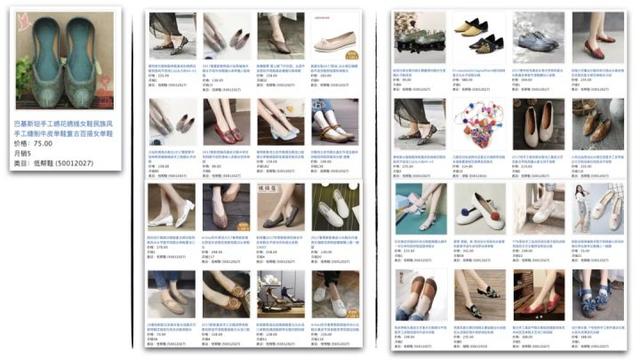
与经典的基于共现的i2i算法相比,最终版本的召回率更高,坏例更少。第一张图商品池全网召回的案例如下。图中三栏分别是原宝贝、挥杆召回和图形嵌入召回:

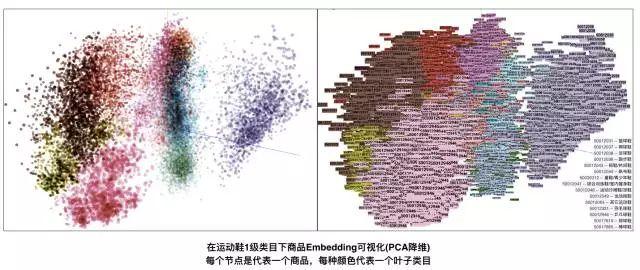
下面的酷图对我们嵌入高维向量有了更直观的解释。我们随机选取了运动鞋一等品类下的宝贝嵌入向量的降维。不同的颜色代表不同的叶类,每个点代表一个产品降维后的坐标。我们可以清楚地看到,同一类别下的宝贝嵌入向量是“有意识地”聚类在一起的,这说明这种意识的本质是图嵌入的向量是可靠的。
1.3.在推荐场景中着陆和调谐
在算法的深度模型训练部分,我们依托搜索工程团队的Porsche blink系统,在XTensorflow上开发模型的TF版本,构建全网序列行为图并完成采样,样本量级达到1000亿,基于并行GPU集群训练。整个召回框架中子图的拆卸结构也是加快迭代效率的关键点。同时,当PS的参数大规模增加时,样本的遍历和样本的训练覆盖率对整个模型的收敛效果也非常重要。
在线召回阶段,首页个性化推荐框架主要应用搜索工程团队基础引擎的在线召回引擎。我们通过最近邻检索的方式将图嵌入训练的模型的数据加载到引擎中,原有的离线、在线结合方式全部在线,增强了推荐系统的灵活性、实时性和召回能力。总体框架如下图所示。
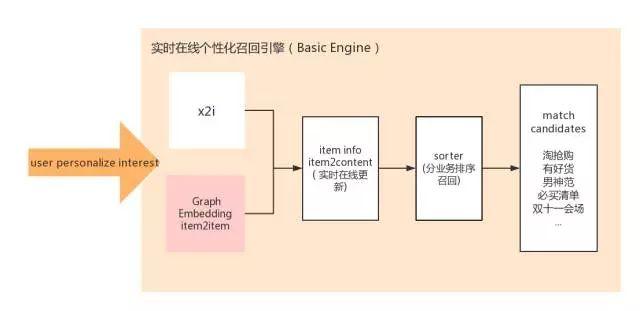
在双11之前,我们这方面工作的迭代调优过程持续了近两个月。在此期间,我们尝试了多种不同的网络模型结构、样本选择和过滤方法,引入了序列行为信息、转移概率边的新构造方法、边信息等方面,并采用了多角度调优方法。在日常首页个性化(AIO)的日常场景中,uctr相比swing版本i2i有了显著提升,双11完全取代了该场景中的最优召回方式。
2.基于XTF的深度排序模型
2.1.XTensorflow简介
2017双十一,我们承接了淘首页流量分布最大的几个首页场景。这些场景的特点是流量大,业务规则限制多,业务变化频繁。我们需要一个稳定的机器学习平台,能够支持快速迭代和实时计算,以支持我们的训练模型和在线评分。为此,我们参与了工程团队的共建工作,这是基于保时捷blink的分布式Tensorflow训练和在线评分平台。基于该平台,home算法的学生开发了多个Rank模型,并在相应的业务场景中取得了良好的效果。我们称这个平台为XTensorflow,简称XTF。
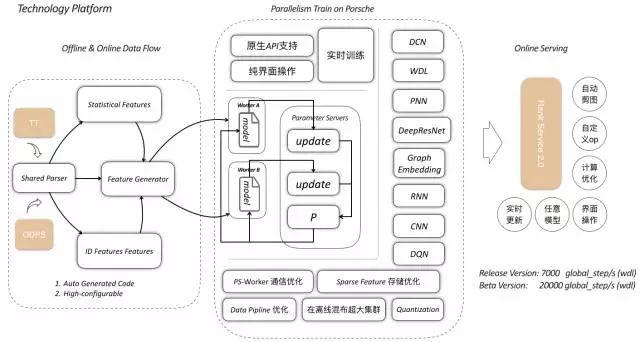
在这个深度学习平台上,我们在双十一推出了包括DCN、DeepResNet在内的深度高阶特征学习模型,并推广成熟了WDL深度模型。与WDL模型相比,更复杂的深度模型的尝试也取得了显著的成果。
2.2.DeepResNet在AIOplus场景中的应用
在深度学习的推荐领域,当用户的珍贵数据和相应参数扩展到一定规模时,加深网络的深度增强模型的学习泛化能力是众所周知的方法。但是,网络的盲目深化也会导致参数爆炸、梯度消失甚至过拟合等问题。参考Resnet网络技术在图像领域的成功,要解决的根本问题是当网络深度继续加深时,渐变消失越来越明显,效果越来越差。在这方面,我们以前在WDL的深边做过相应的尝试。随着网络导数和隐节点数的增加,普通NN网络的训练效果会越来越差,甚至导致效果更明显的下降。基于这些实验现象,我们把WDL推广到了深Resnet。基本示意图如下:
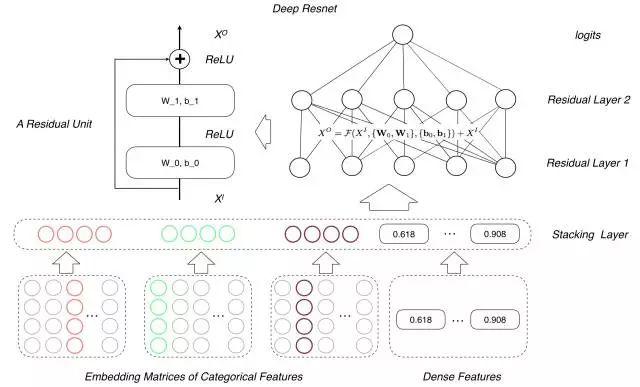
原始输入层包含实值特征和id类特征的嵌入向量,它连接到10层的Resnet层。最后用logloss定义最终损失。同时,基于场景“双十一”中用户行为的快速变化和AIOplus区块中活动素材的多变性(运营会根据BI数据等实时调整素材。),对实时深度Resnet模型进行了训练,并在预期热度和双11当天上线了场景卡牌场馆业务,取得了成效。
2.3、DCN(深& amp跨网络)在主会场入口的个性化应用
通过用多层全连接Relu层嵌入稀疏特征,DNN可以自动交叉特征,学习高阶非线性特征。但这种交叉是隐性的,交叉顺序无法显示和控制,容易“过度泛化”。为了弥补这一点,WDL模型引入了宽面,显示和记忆一些可解释的特征交叉信息,以保证模型的准确性。但是宽边的引入带来了特征工程的大量工作,同时也只能学习二阶(跨积)浅层的交叉。DCN引入交叉网络,通过网络层数控制特征交叉的顺序,实现高阶特征交叉所需参数远少于DNN;。跨层的定义相对简单:
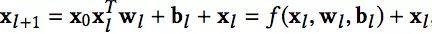
这个设计类似于ResNet,l+1层的映射函数F其实就是拟合残差。
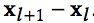
;跨网最终会加入深网学习。完整的网络结构如下:
由于双十一主会场入口场景的展位召回率相对较低,top n的准确率非常高。因此,我们选择DCN模型,利用交叉网络的高阶特性来交叉提高ctr估计的精度。同时,由于主会场受理模块从入口点进入后变化频繁,必须选择项目粒度(而不是素材内容粒度)来建模,对模型的泛化能力要求较高,所以我们使用深度DNN网络来提高模型的泛化能力。作为主要引流场景之一,我们有足够的数据来学习模型。在最终的网络版中,我们设置了3层跨层和10层深层(Resnet结构)。为了适应场景的变化,我们做了大量的日志清理工作。相比纯实时的样品流,每小时的样品流更方便做复杂的样品清洗。所以在调优阶段,我们选择增量每小时训练,然后切换到实时模型。
2.4、联合深度模型
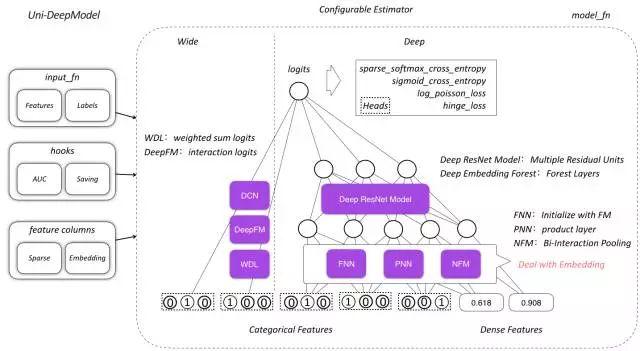
提出Google Wide & After模型后,这个框架基于深侧用于高维特征提取(泛化),宽侧用于显示特征交叉(记忆),最后用于联合学习已经以各种方式升级。我们整理并实现了几个有趣的经典模型,包括WDL、PNN、DeepFM、NeuralFM、DCN、DeepResNet等。这些模型都是基于TF Estimator框架实现的,封装为model_fn,特征处理和模型训练过程高度可配置。同时,基于这种在深度模型上的长期积累,提出了Union结构的DeepModel,以满足各种业务场景对深度模型的需求。
你需要了解获取最新的Python、人工智能、自动化运维技术,可以关注我的微信官方账号。另外,最近我整理了一个基于Python的系统教学视频,免费分享给大家。可以关注我微头条的更新。