
最近测试了一个近似最近邻搜索工具SPTAG,打算先测试点东西练练手,于是想到可以建立一个以前美图的索引,看看能不能找到想要的美图。
所需的环境如下:
参见代码:github.com/nladuo/MMFi…
首先准备好美女的图片。下面是我很久以前爬的一些图,总共有近万张。
如果没有,这里是谷歌驱动的下载链接:drive.google.com/file/d/1shZ.
解压密码:nladuo。
接下来,对图片做一些预处理。我这里主要打算做的不是全图搜索,会比较麻烦。我这里只做人脸搜索。
这里通过face_recognition的库,保存只有一张脸的图片,提取人脸,然后放到mongodb中。
CD mm finder/data _ preprocess
python 3 filter _ images . py
这里筛选出9477张图片。


下一步就是把图片转换成矢量,这就是特征工程。因为我自己不做图像,所以不太清楚具体的方法。我大概查过了。传统的方法是SIFT,现在是神经网络。
如果是一般的图,就用ImageNet训练的最后一层的向量作为特征即可。在这里我找到了一个专门做人脸识别的预训练模型:sefiks.com/2018/08/06/…,准确率应该更高。

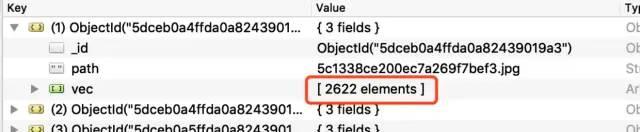
模型是VGG,最后一层是维数为2622的矢量。通过处理,将所有人脸转换成长度为2622的向量,然后保存到mongodb中。
CD mm finder/data _ preprocess
python 3 feature _ extraction . py

下一步是构建最近邻索引,也称为密集索引。在文本搜索引擎中,我们通常使用TF-IDF,它属于稀疏索引,即倒排索引。而密集索引通常是图结构的索引。
为什么要建立索引?
其实是为了加快搜索速度。如果我们在正常情况下搜索一张图片,实际上需要计算与数据库中9477个向量的相似度,才能得到准确的相似度排名。这个时间复杂度是O(N),看起来不高,但是每次搜索都是O(N)。如果有一亿张图片,不知道要用哪一年。
有了索引,搜索结果可以在固定的时间O(C)内返回。如果还是慢,就加个机。
至于索引的选取,我这里用的是SPTAG,因为它是一个高效的、可扩展的最近邻搜索系统。类似的系统是facebook的faiss。其实装这个比较麻烦。如果你想跑着玩,也可以看看KDTree,LSH等。学习做近似最近邻搜索。
在Docker下安装SPTAG后,将所有图像数据导出为SPTAG指定的输入格式。
cm finder/index _ construction
python 3 export _ sptag _ index builder _ input . py
docker cpmm _ index _ input . txt(您的容器ID):/app/Release/
然后,将导出的数据放入SPTAG-Docker容器,通过indexbuilder建立索引。
Docker attach(你的集装箱ID)
。/index builder-d 2622-v float-I ./mm _ index _ input . txt-odata/mm _ index-abkt-T2
索引建立后,启动搜索的rpc服务。
python 3 sp tag _ RPC _ search _ service . py

接下来可以进入查询测试了,如果是mac用户可以安装imgcat工具,在命令行就能查看图片。接下来,您可以进入查询测试。如果你是mac用户,可以安装imgcat工具,在命令行查看图片。
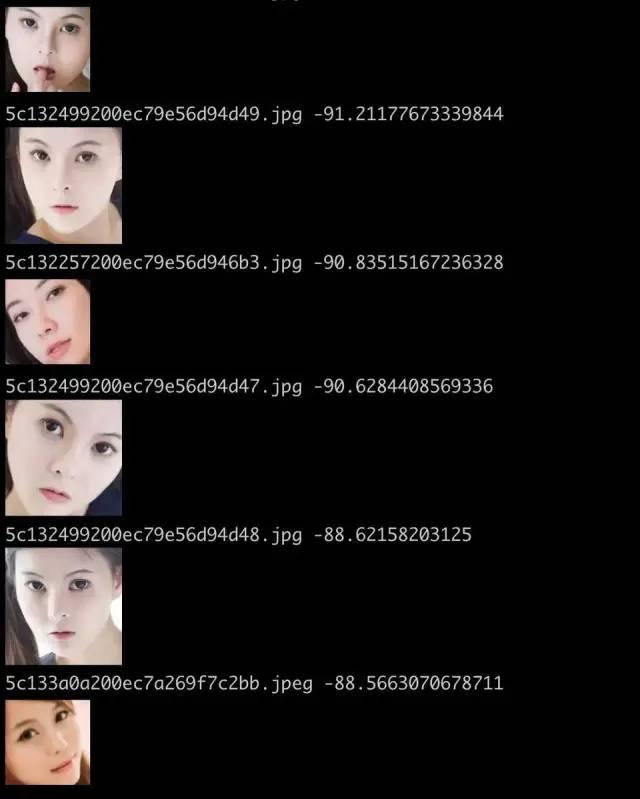
python3 search_test.py

效果如下,感觉还可以。
最后整合各个模块,编写上传和搜索接口,形成完整的应用Demo。
CD web _ demo
python 3 main . py
效果如下:


(美图容易被遮挡,这里用另一个图片集代替。)









