
前段时间介绍了如何使用C#语言抓取“【JD。COM-计算机和互联网图书销售排行榜]”。通过这种方法,我们可以得到“JD。COM”。
但是,读书相当于喂饱了我们的大脑。只有我们输入了精华,才能有更好的输出。因此,只有“JD。COM”不够,还是片面的。我们需要拓展数据来源,说到购书,自然会想到当当网。今天我就带大家去爬“当当网-计算机及互联网图书销售排行榜”的数据。
在爬取数据之前,我们先分析一下原始网页。网站地址如下:
http://bang . Dangdang . com/books/best sellers/01 . 54 . 00 . 00 . 00 . 00-recent 7-0-0-1-1
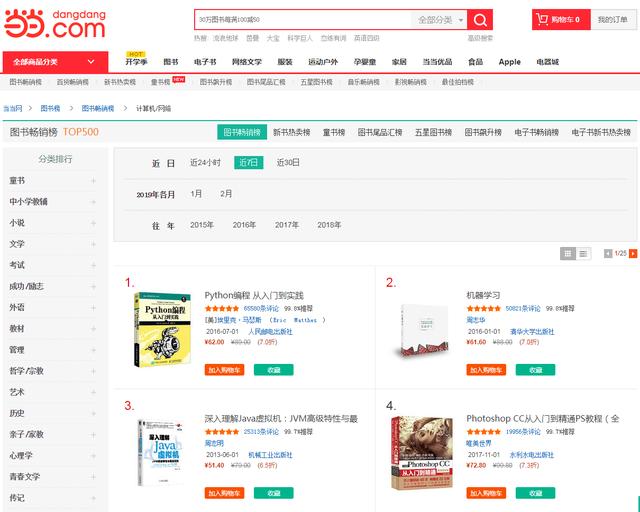
当当网网页
当我们点击“第2页”时,网站会变为:
http://bang . Dangdang . com/books/best sellers/01 . 54 . 00 . 00 . 00 . 00-recent 7-0-0-1-2
对比两个请求的URL,发现只有最后一位数发生了变化,于是得到了抓取列表的网络地址。
接下来,我们来看看网页对应的源代码:
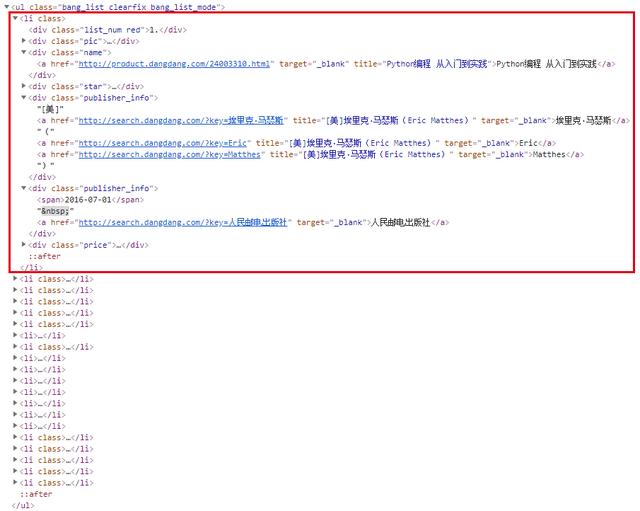
当当源代码
从源代码中,我们发现所需的数据存储在。bang _ list >:李的。class >:和a. publisher _ info >:在a标签中。只要通过选择器找到这两个标签,就可以得到我们想要的数据。
通过上面的分析,我们只需要通过给定的URL获取当当网-电脑和互联网图书销售列表页面的HTML DOM树,然后对其进行分析就可以找到相应的数据。这里推荐一套开源工具Jumony,可以在Github上下载。
Jumony下载
下载地址是:
https://github.com/Ivony/Jumony
这里就不多介绍Jumony了。有兴趣的可以在图文下方留言,我后面会写几张图文介绍一下这个工具。
至此,已经介绍了网页分析和使用的工具。下面介绍一下我们写的代码。
1。构建一个结构化的Book类来存储图书信息。
公共课书 { ///& lt;总结& gt[/h /// <或者设置销量排名 //
public static ihtml document GetHtmlDocumentDd(int page) { string URL = " http://bang . Dangdang . com/books/best sellers/" +" 01 . 54 . 00 . 00 . 00 . 00-" +" recent 7-0-0-1-" +page; IHtmlDocument文档; try { document = new JumonyParser()。加载文档(URL); } catch { document = null; } 返回文档; } 3。解析HTML DOM树以获取存储书籍的链表;。
公共静态列表& ltBook & gtGetBooksDd(int page) { ihtml document doc = GetHtmlDocumentDd(page); if (doc == null) 返回null; List & lt;Book & gtresult =新列表& ltBook & gt(); List & lt;IHtmlElement & gt列表=文档。查找("。bang _ list & gt李”)。to list(); for(int I = 0;我& lt列表。数数;i++) { Book Book = new Book(); 书。num = I+1; 书。Source = "当当"; List & lt;IHtmlElement & gts =列表[i]。查找("。名称& gt一”)。to list(); //获取图书名称 book.title = s [0]。属性(“标题”)。Attributevalue.trim()。 List & lt;IHtmlElement & gtinfor = lists[i]。查找("。publisher _ info & gt一”)。to list(); //获取作者姓名 book.author = infor [0]。属性(“标题”)。Attributevalue.trim()。 //获取出版社名称 book . press = infor[infor . count-1]。innerhtml()。trim(); 结果。添加(书); } 返回结果; } 4。Markdown打印格式存储图书的链接列表。
私有字符串GetReport(字符串名称,列表& ltBook & gtlst) { 字符串结果=环境。换行符+ " - " +环境。NewLine + "### " +名称+环境。换行; for(int I = 0;我& ltlst。数数;i++) { result +=环境。NewLine + lst[i] +环境。换行; } 返回结果; } 5。减价文本格式呈现。

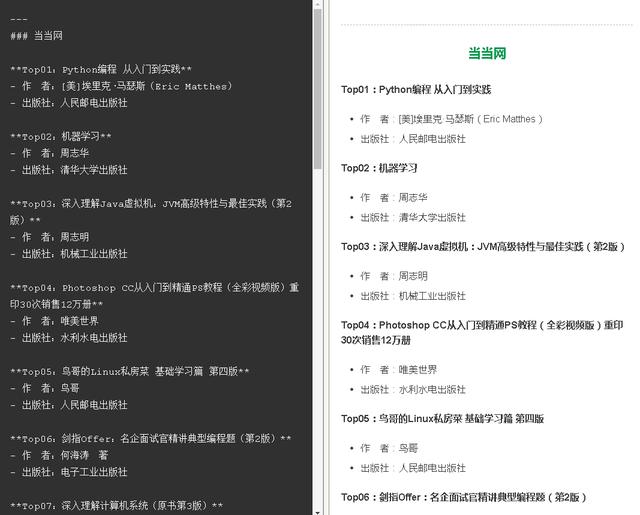
当当结果
最后,我们再总结一下。
通过对当当网-电脑和互联网图书销售排行榜的网页进行分析,确定抓取网页的URL地址结构,利用Jumony开源工具获取网页的HTML DOM树,利用选择器获取相应的图书数据集,最终打印格式为Markdwon text。渲染后可以形成我们每周推荐的计算机书籍周销量排行榜的“当当”部分。怎么样?是不是很有意思?让我们试一试。今天到此为止,再见!







