l收藏网站
[场景描述] 收集revisionvillage网页中所有图片的数据。
[来源网站介绍]国外知名IB真题网站revisionvillage有一个IB数学刷题网站,每道题都有视频讲解。
[工具]for spider数据采集系统,免费下载:for spider免费版下载地址
[门户地址]https://www . revision village . com/I b-math-analysis-and-approach-HL/question bank/number-and-algebra/sequences-and-series/
[收藏内容]
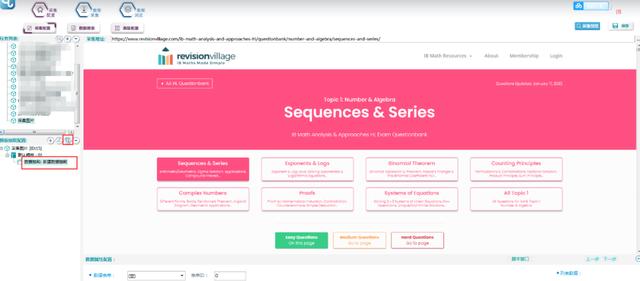
收集页面中的真实图片数据。
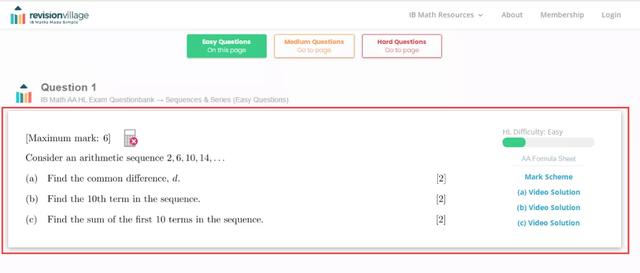
[采集效果] 如下图所示:

l 配置步骤
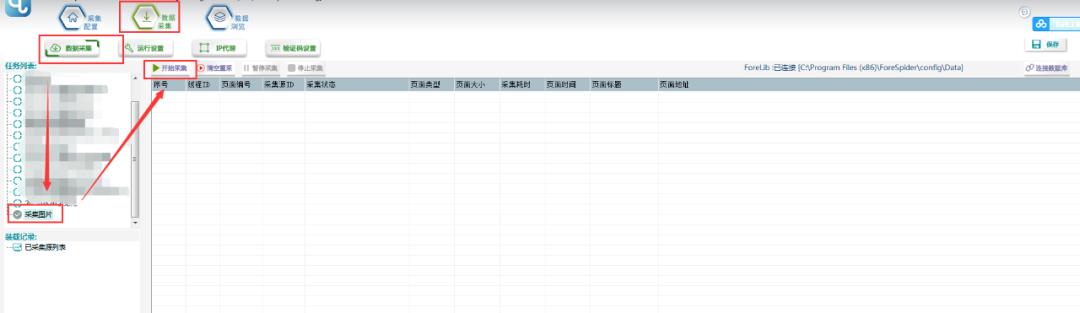
1。创建新的采集任务
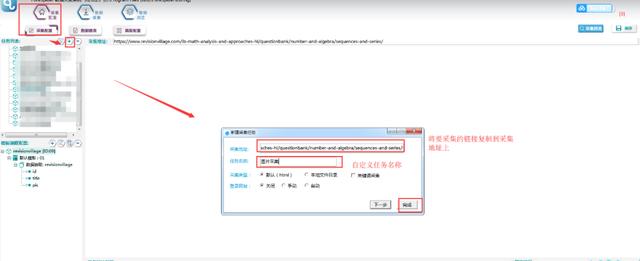
选择【采集配置】,点击任务列表右上角的[+]新建一个采集任务,在【采集地址】框中填写采集入口地址,自定义【任务名称】,点击【下一步】。
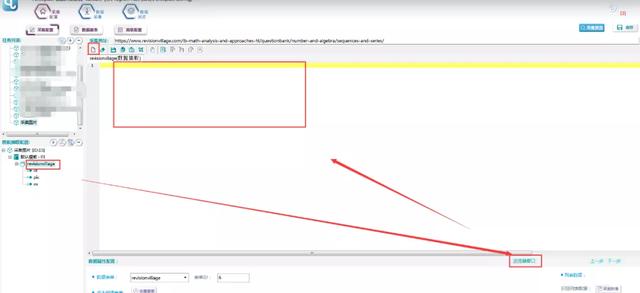
2。寻找图片链接
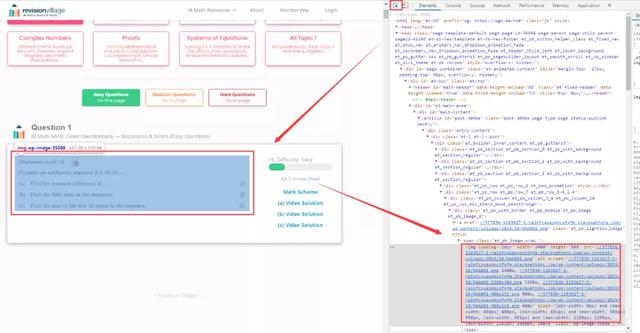
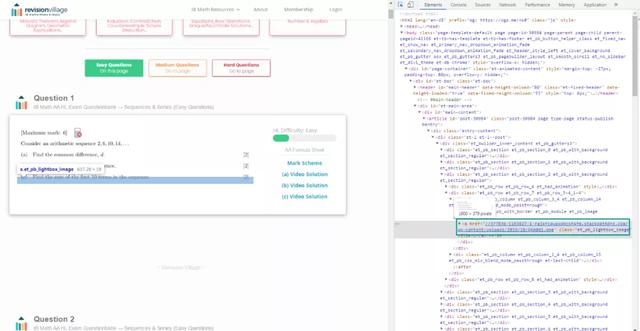
在浏览器中打开页面,点击F12,选择指针,点击页面中的图片位置,在源代码中找到图片链接,如下图所示:
该链接如下图所示:
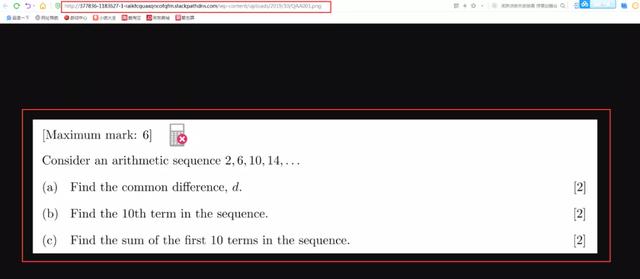
复制图片链接,在浏览器中打开,就是图片页面:
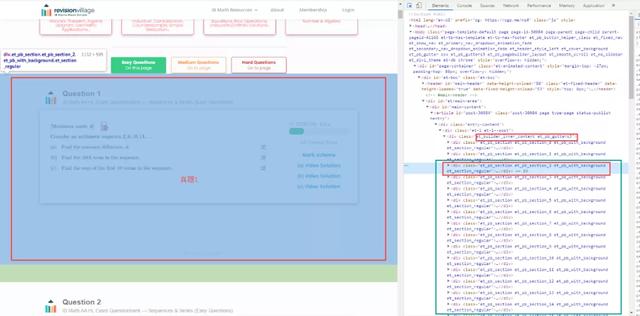
3。查找图片链接位置/规则

观察源代码,发现每个真题对应源代码中的一个类,如下图所示:红框表示真题1对应的源代码,绿框包含所有真题的源代码,从类为[et _ builder _ inner _ contentet _ Pb _ gutters 3]的子节点的下一个节点开始。
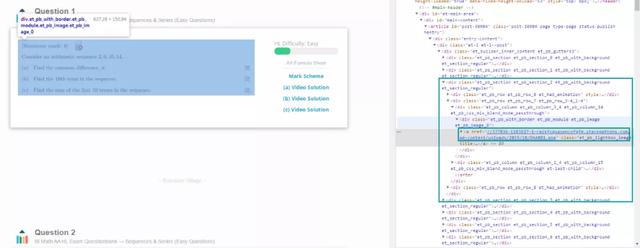
打开第一个真题对应的源代码后,如下图所示,观察到图片链接的位置在该节点的下一个子节点的子节点的href值中。
4。数据提取
①打开模板,创建新的数据提取,如下图所示:
②新建一个数据表,如下图所示:
③相关数据表

④打开脚本窗口,创建新的数据提取脚本。
⑤根据图片链接规则,编写脚本如下:
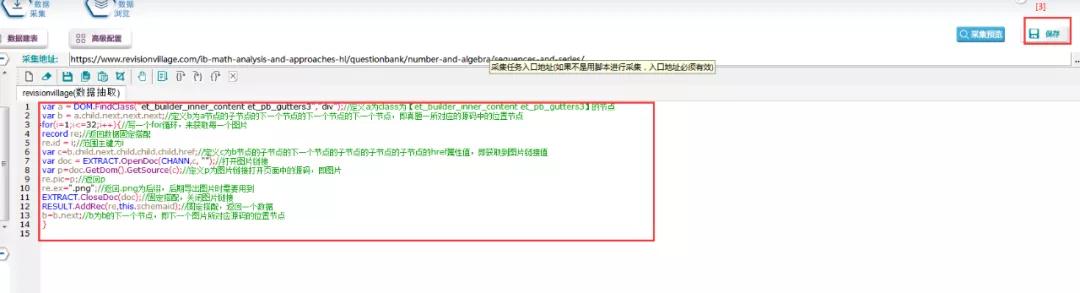
脚本文本:
var a = DOM。find class(& # 34;et _ builder _ inner _ content et _ Pb _ gutters 3 & # 34;,"div & # 34);//用类[et _ builder _ inner _ contentet _ Pb _ gutters 3]
var b = a . child . next . next . next定义一个节点;//将B定义为节点A的子节点的下一个节点的下一个节点,即for(i=1的位置节点
;我& lt=32;I++){//写一个for循环得到每张图片
记录re;//返回数据固定搭配
re . id = I;//范围主键为I
var c = b . child . next . child . child . child . href;//将c定义为节点B的下一个子节点的子节点的href属性值,即得到图片链接值
vardoc = extract . opendoc(chann,c,& # 34;");//打开图片链接
var p = doc。getdom()。getsource(c);//将p定义为图片链接打开的页面中的源代码,即图片
re . pic = p;//Return p
re.ex = "。png”;//返回后缀。png
摘录。CloseDoc(doc);//固定搭配,关闭图片链接
result.addrec (re,this . schema bid);//固定搭配,返回一个数据
b = b . next;//b是B的下一个节点,即下一张图片对应的源代码的位置节点
}
⑥采集预览
发现图片已经全部采集完毕,说明配置成功。
l 采集步骤
模板配置完成,采集预览无问题后,即可进行数据采集。
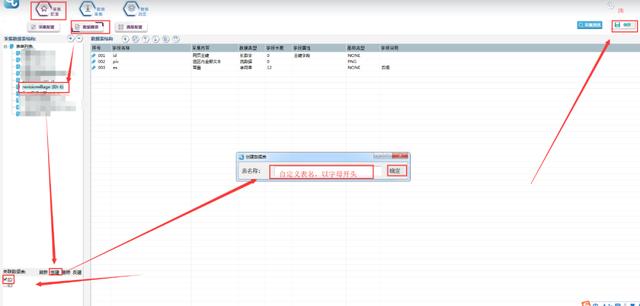
1。创建数据表单
选择数据表,在表单列表中单击该模板的表单,然后选择在关联数据表中创建。表名是用户自定义的,这里命名为ID(请注意不允许用数字和特殊符号命名),然后点击OK。创建,检查数据表,点击右上角的保存按钮。
2。开始收集
选择数据采集,勾选任务名称,点击开始采集,采集正式开始。

3。导出数据
采集完成后,您可以在数据浏览中选择数据表,查看采集的数据并导出数据。

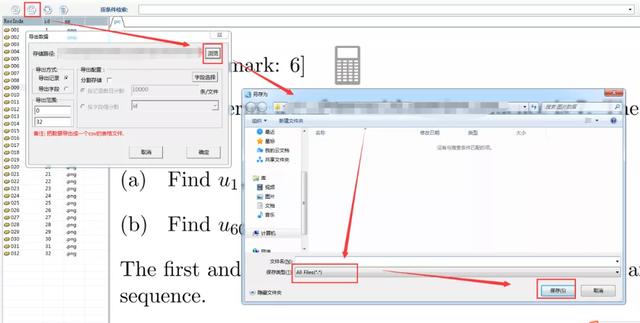

4。打开导出的文件,如下图所示

本教程仅供教学使用,严禁用于商业用途!
l前鼻简介
钱斯尼夫大数据(Qiansniff Big Data),国内领先的R&D大数据专家,多年来致力于大数据技术的研发,自主研发了从数据采集、分析、处理、管理到应用、营销的一整套大数据产品。前卫致力于打造国内首个深度大数据平台!