图像抠图是提取精确的alpha抠图的过程,它将图像中的前景和背景对象分开。这项技术传统上用于电影制作和摄影行业,用于图像和视频编辑,如背景替换、合成散光和其他视觉效果。图像抠图假设图像是前景和背景图像的组合,因此每个像素的亮度是前景和背景的线性组合。
在传统图像分割的情况下,图像以二值模式分割,其中一个像素属于前景或背景。然而,这种类型的分割无法处理包含精细细节的自然场景,如头发和头发,这需要为前景对象的每个像素估计透明度值。
与分割遮罩不同,Alpha遮罩通常非常精确,可以在发束级别保留头发细节和准确的前景边界。尽管最近的深度学习技术在图像抠图方面显示出了潜力,但仍然存在许多挑战,例如在地面上生成准确的真实阿尔法掩模,提高现场图像的泛化能力,以及在处理高分辨率图像的移动设备上进行推理。
在Pixel 6中,谷歌引入了一种新的方法,从自拍图像中估计高分辨率和精确的alpha mask,这显著改善了人像模式下拍摄的自拍的外观。在合成景深效果时,使用alpha mask可以让Google提取出更准确的主体轮廓,并且有更好的前景和背景分离。这使得各种发型的用户可以使用自拍相机拍摄出美丽的人像照片。在这篇文章中,谷歌描述了谷歌实现这一改进所使用的技术,并讨论了谷歌如何应对上述挑战。

相对于新的高质量Alpha蒙版,使用低分辨率和粗糙Alpha蒙版的自拍照片的人像模式效果。
Portrait Matting在设计人像抠图时,谷歌训练了一个由一系列编解码器块组成的全卷积神经网络,以逐步估计高质量的阿尔法掩模。Google将输入的RGB图像与作为输入传递到网络的粗糙alpha蒙版(通过使用低分辨率字符分割器生成)连接起来。新的人像抠图模型首先通过使用MobileNetV3主干和浅层(即具有较少层)解码器来预测在低分辨率图像上运行的精细低分辨率alpha遮罩。然后Google使用一个浅层编码器-解码器和一系列残差块来处理高分辨率图像和上一步中细化的alpha mask。浅层编码器-解码器比以前的MobileNetV3主干更依赖于低层特征,专注于高分辨率的结构特征,以预测每个像素的最终透明度值。通过这种方式,模型可以细化初始的前景alpha蒙版,并精确地提取非常精细的细节,例如头发。提出的神经网络架构使用Tensorflow Lite在Pixel 6上高效运行。
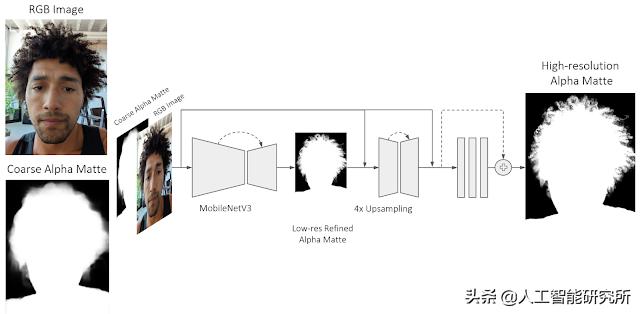
该网络从彩色图像和初始的粗糙阿尔法掩模中预测高质量的阿尔法掩模。先用Google MobileNetV3骨干网和浅层解码器预测精细的低分辨率alpha matte。然后谷歌使用浅层编码器-解码器和一系列残差块来进一步细化初始估计的AlphaMatter。
最新的图像抠图深度学习工作依赖于手动注释的每像素阿尔法掩模来将前景与背景分开。这些遮罩是通过使用图像编辑工具或绿色屏幕生成的。这个过程很枯燥,不适合生成大型数据集。此外,它通常会产生不准确的alpha蒙版和受污染的前景图像(例如,来自背景的反射光或“绿色溢出”)。此外,这不能确保主体上的照明与新背景环境中的照明一致。
为了应对这些挑战,人像抠图使用自定义体积捕获系统Light Stage生成的高质量数据集进行训练。与之前的数据集相比,这更加真实,因为重新照明允许前景对象的照明与背景相匹配。此外,Google使用来自实地图像的伪地真实alpha mask来监督模型的训练,以提高模型的泛化能力,具体如下。地面实况数据生成过程是这项工作的关键组成部分之一。
地面真实数据生成为了生成准确的地面真实数据,Light Stage使用配备了331个自定义彩色LED灯的测地线球体、一组高分辨率摄像头和一组自定义高分辨率深度传感器。
生成一个接近真实的角色模型。结合灯光舞台数据,谷歌使用时间复用光和先前记录的“干净的板”来计算精确的阿尔法掩模。这种技术也称为比率抠图。

这种方法的工作原理是记录光照背景下物体的轮廓,作为光照条件之一。此外,谷歌捕获了一个干净的背景照明板。轮廓图像,除以干净的牌照图像,提供了一个真正的阿尔法掩模。

然后,谷歌使用基于深度学习的抠图网络,将记录的alpha抠图外推至Light Stage中的所有相机视点,该网络使用捕获的干净板作为输入。这种方法允许Google将alpha mask计算扩展到不受约束的背景,而无需特殊的时间复用照明或干净的背景。这种深度学习架构只使用比率抠图方法生成的地面真相抠图进行训练。

从灯光舞台的所有相机视点计算的Alpha遮罩
使用每个主体的反射场和谷歌地面真实遮罩生成系统生成的阿尔法遮罩,谷歌可以用给定的HDR光照环境重新照亮每个人像。根据Google alpha混合方程,将这些重新光照的物体合成到目标光照对应的背景中。然后,通过将虚拟相机定位在中心和光线追踪,从HDR全景图生成的背景图像从相机的投影中心进入全景图。确保Google投影到全景图中的视图与其重新照明的方向相匹配。谷歌使用不同焦距的虚拟相机来模拟消费者相机的不同视角。该管道通过在一个系统中处理抠图、重新光照和构图来生成逼真的构图,然后Google用它来训练人像抠图模型。

使用地面真实生成的alpha蒙版来合成不同背景上的图像(高分辨率HDR地图)
使用野外肖像进行训练监督为了缩小Light Stage生成的人像与实地人像之间的差距,Google创建了一个管道来自动标注实地照片,并生成伪地的真实alpha蒙版。因此,Google通过使用Total Relighting中提出的深度抠图模型创建了一组模型,该模型可以从现场图像中计算出多个高分辨率的alpha masks。谷歌在Pixel手机内部拍摄的大量人像照片数据集上运行这一管道。此外,在这个过程中,Google通过推断不同尺度和旋转的输入图像进行测试时间增强,最终聚合所有估计的alpha masks中每个像素的alpha值。
根据输入的RGB图像对生成的阿尔法掩模进行视觉评估。感知上正确的alpha遮罩(即,跟随对象的轮廓和细节(例如,头发))被添加到训练集中。在训练期间,用不同的权重对两个数据集进行采样。所提出的监督策略将模型暴露于更多种类的场景和人体姿态,这提高了其对现场照片的预测(模型泛化)。

使用深度抠图模型和测试时间增强集估计的伪地面真实阿尔法掩模
肖像模式自拍人像模式效果对主体边界周围的误差特别敏感(见下图)。例如,使用粗糙的alpha蒙版导致的错误将总是集中在对象边界或头发区域附近的背景区域。使用高质量的alpha mask使谷歌能够更准确地提取主体的轮廓,并改善前景和背景的分离。
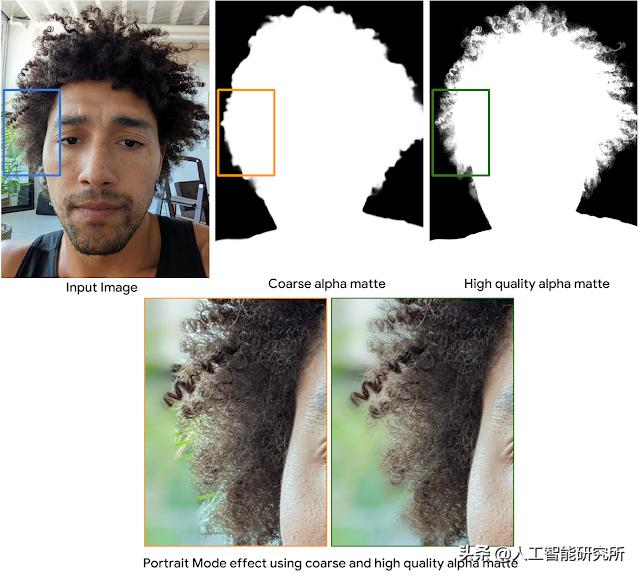
谷歌通过提高Alpha mask的质量,减少最终渲染图像的误差,改善头发区域和主体边界周围模糊背景的外观,改善了Pixel 6上前置摄像头的人像模式。此外,谷歌的ML模型使用了各种各样的训练数据集,涵盖了各种肤色和发型。你可以用新的Pixel 6手机自拍来尝试这种改进的人像模式。

相比新的高质量Alpha蒙版,使用粗糙Alpha蒙版的自拍照片的人像模式效果。