2017年底,DeepMind推出了AlphaZero,这是一个可以自主学习国际象棋、国际象棋(类似日版象棋)和从零开始的技能的系统,全面超越各项赛事的世界冠军。
全公司的R&D人员对这个系统带来的初步成果感到非常兴奋,也很高兴看到国际象棋界成员的热烈反应。他们在AlphaZero的象棋游戏中找到了一种突破性的、高度动态的和“不同于传统”的游戏风格,这也使它与之前存在过的任何象棋游戏引擎完全不同。
如今,AlphaZero已经出现在著名的科学杂志上,并以封面论文的形式发表。背后的公司DeepMind也在官方博客上撰文,详细分析了这一系统的最新成果。InfoQ将全文翻译如下:
今天,我们很高兴地发布AlphaZero的完整评估报告,该报告已发表在《科学》杂志上:
http://science.sciencemag.org/content/362/6419/1140

编辑已经确认并更新了这些初步结果。这篇文章描述了AlphaZero如何快速学习每一种象棋,包括从没有任何内置指导的随机游戏开始,成长为有史以来最强大的棋手。
这种从零开始学习每一种棋的能力,不受人类固有思维的束缚,因此产生了一种与传统相悖但极具创造性和动态性的独特游戏风格。大量的国际象棋。马修·马修·萨德勒和国际象棋女大师娜塔莎·雷根在将于明年1月出版的《游戏改变者》一书中分析了AlphaZero玩的数千种国际象棋游戏,发现其风格不同于任何传统的国际象棋引擎。马修说:“这就像发现了古代象棋大师的秘密。”
传统的国际象棋引擎——包括世界计算机国际象棋冠军Stockfish和IBM众所周知的“深蓝”——依赖于人类顶级国际象棋选手提供的数千条规则和启发式方法。这些信息试图解释游戏中的每一种可能性。姜奇也遵循这一原则,它的程序只适用于姜奇本身,但它使用了类似于国际象棋程序的搜索引擎和算法。
艾泽罗采用的方法完全不同。它用一套深度神经网络和大量的通用算法来代替那些手工制定的规则,而这些算法除了象棋的基本规则之外,什么都不知道。

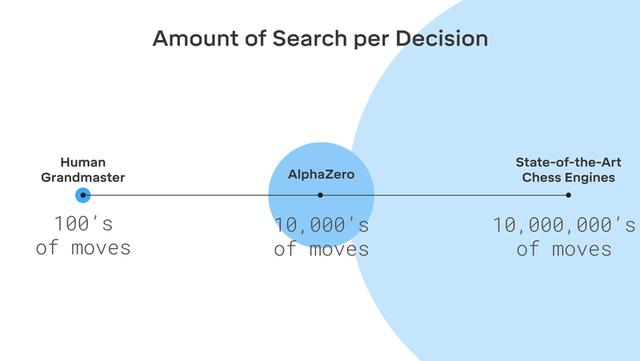
在国际象棋中,AlphaZero仅用4个小时就成功击败了Stockfish。在下棋方面,仅用了2个小时就打败了埃尔莫。至于围棋,AlphaZero在30小时内击败了2016年曾击败世界冠军李世石的AlphaGo版本。注意:每个训练步骤代表4096个磁盘位置。
为了学习每一种棋,这个未经训练的神经网络会通过一个叫做强化学习的实验和试错过程来完成数百万次自我博弈。起初,它完全是随机的;但是,随着时间的推移,系统会从输赢和平局的经验中学习,从而调整神经网络的参数,使其在未来的选择中更有可能做出有利的判断。网络需要的训练量取决于游戏的风格和复杂程度——象棋需要9个小时左右,围棋需要12个小时左右,围棋需要13天。
这个经过训练的网络用于指导一种搜索算法——称为蒙特卡罗树搜索(简称MCTS)——在当前棋盘下坐下来选择最有利的棋步。对于每一步棋,AlphaZero所需的位置搜索量只是传统象棋引擎的一小部分。比如国际象棋,AlphaZero每秒只需要搜索6万个位置;相比之下,Stockfish需要搜索大约6000万个位置。
经过全面的训练,这套系统已经被用来对抗最强大的传统象棋(Stockfish)和通用象棋(Elmo)引擎,甚至是AlphaZero的“一奶同胞”大哥AlphaGo,世界上最强的棋手。
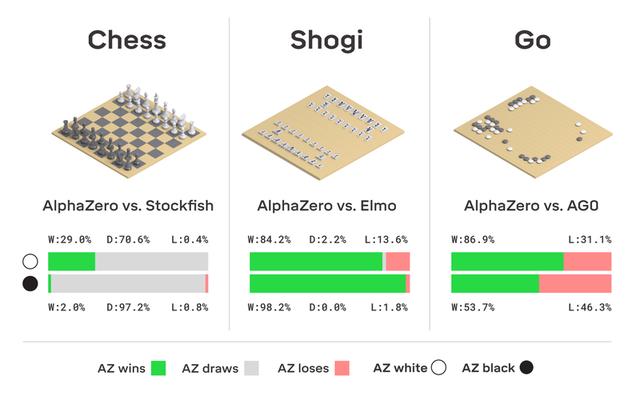
然而,更令人着迷的是AlphaZero在游戏过程中展示的棋风。比如在象棋方面,AlphaZero在自我学习和训练中自主发现并使用了常见的人类下棋模式,如开局、守王、战阵等。但是因为自学,完全不受传统观念的影响,AlphaZero也发展出了自己的直觉和策略。他提出的一系列激动人心的新奇想法,极大地拓展了几个世纪以来人类对国际象棋战略的认识。
玩家首先注意到的一定是AlphaZero的棋风。马修·萨德勒说,“它的举动充满了目的性和侵略性,总是围绕着对方的国王进行策划。”在此基础上,AlphaZero还具有高度动态的下棋能力,大大提高了自身棋路的灵活性和机动性,同时也限制了对手棋子的灵活性和机动性。与直觉相反,AlphaZero似乎不太重视棋子的作用。现代竞技项目的一个基本特征是,所有参与者都是有价值的。如果一方棋手的棋子在棋盘上的价值高于另一方棋手,则说明前一方棋手在棋子的作用上占有优势。但与此不同的是,AlphaZero更倾向于在游戏开始时牺牲掉这些棋子,从而获得更长远的态势利益。
马修指出,“令人印象深刻的是,它在各种角色和位置上都表现出了这种强烈的棋风。”同时,他观察到AlphaZero在初始阶段会刻意从“与人类意图非常相似”的设计入手。
马修解释道,“传统引擎非常稳定,几乎没有明显的错误。但是,在没有具体解决方案可供参考的时候,就显得很无奈了。相比之下,AlphaZero可以在这样的位置表现出“感觉”、“洞察”或者“直觉”。
这种独特的能力是其他传统象棋引擎所不具备的,也在最近的世界象棋锦标赛中给象棋爱好者带来了新的思路和灵感。芒努斯·卡尔森和法比亚诺·卡鲁阿纳之间的竞争就是一个例子,这将在《游戏规则改变者》一书中进一步讨论。娜塔莎·里根(Natasha Reagan)说,“分析AlphaZero和顶级国际象棋引擎甚至顶级大师下棋的方式真的很迷人。”
Azero带来的体验也呼应了2016年AlphaZero与传奇围棋大师李世石的对局。在这场比赛中,AlphaGo想出了很多创造性的获胜方法,包括在第二场比赛中只用了37步就赢了——这彻底颠覆了人类几百年来对围棋的认识。这几招被包括李世石本人在内的很多玩家奉为经典案例。李世石在评论step 37时说,“我一直以为AlphaGo属于那种基于概率的计算工具,毕竟它只是一台机器。但是看到这一步,我改变了想法。不可否认,AlphaGo具有真正的创造力。”
和围棋一样,我们也为AlphaZero在国际象棋领域的创造力感到兴奋。自计算机时代开始以来,国际象棋一直是人工智能技术面临的主要挑战——包括巴贝奇、图灵、香农和冯诺依曼在内的许多早期先驱都在试图设计国际象棋问题的解决方案。然而,AlphaZero的应用并不仅限于国际象棋、国际象棋或围棋。为了建立一个能解决各种实际问题的智能系统,我们要求它具有灵活性,能适应各种新情况。虽然我们在实现这一目标方面取得了一些进展,但这仍然是人工智能研究中的一个核心挑战。虽然目前的系统可以以非常高的标准掌握特定的技能,但它往往无法解决任务,即使只是轻微的修改。
AlphaZero能够掌握三种不同的复杂国际象棋游戏(甚至覆盖所有完美信息项)代表着克服这一问题的重要一步。这证明了单个算法在不同的特定规则下学习和发现新知识是完全可能的。此外,虽然还处于早期开发阶段,但AlphaZero的创造性想法,加上我们在AlphaFold等其他项目中观察到的令人兴奋的结果,让我们对创建通用学习系统的目标充满信心。这意味着我们有望找到更多新的解决方案来解决最重要和最复杂的科学问题。
下载论文:
https://deepmind.com/documents/260/alphazero_preprint.pdf
原始链接:
https://deepmind.com/blog/alphazero脱落新光大游戏国际象棋和围棋/