Orange是一个开源的数据可视化、机器学习和数据挖掘的工具。其特色是从前端到后台的探索性数据分析和交互的数据可视化功能,同时它也可以作为Python的库。许多的科研著作都在iris数据集上做分类操作。该数据集由3种不同类型的鸢尾花的50个样本数据构成。下面小编带你用Orange做iris数据集的初步可视化。

Orange是一门视觉化程式设计语言(图源:Orange官网)
第一步:下载安装Anaconda,或直接安装Orange(网址:https://orange.biolab.si/)。安装Anaconda后打开Anaconda Navigator。

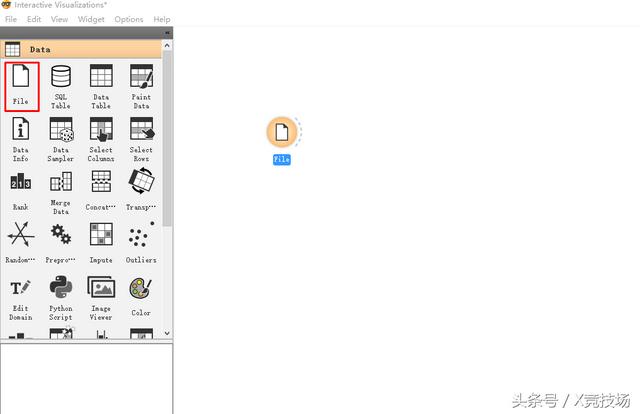
第二步:启动Orange,单击或拖动“File”图标到空白区域。
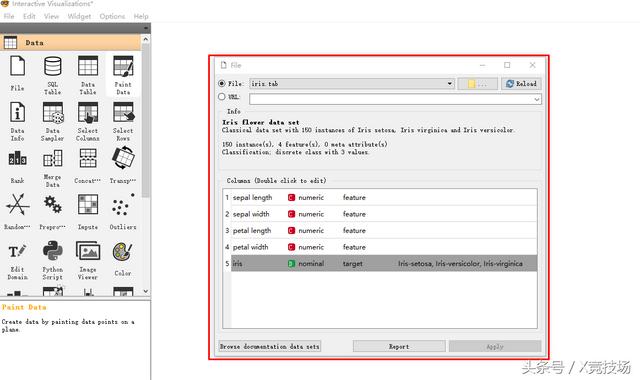
第三步:双击“File”图标,出现如下界面,选择“iris数据集”。鸢尾花数据集包含以下5个属性:
Sepal.Length(花萼长度),单位是厘米;
Sepal.Width(花萼宽度),单位是厘米;
Petal.Length(花瓣长度),单位是厘米;
Petal.Width(花瓣宽度),单位是厘米;
种类:Iris Setosa(山鸢尾),Iris Versicolor(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾)。
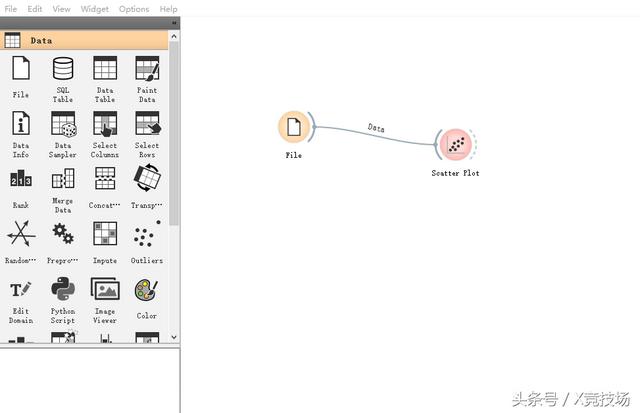
第四步:从“File”虚线部分向外拖动,出现可选数据可视化类型框,选择“Scatter Plot”(散点图)。
第五步:双击“散点图”图标,出现数据散点图。X和Y轴可以任意选择不同的花的属性。X选择“种类”、Y选择“花萼长度”的可视化效果如下:
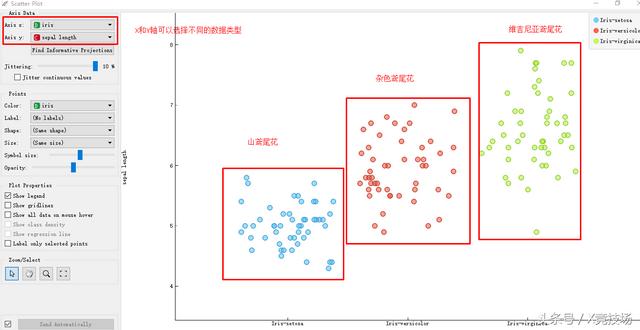
第六步:选择图内“山鸢尾”部分。
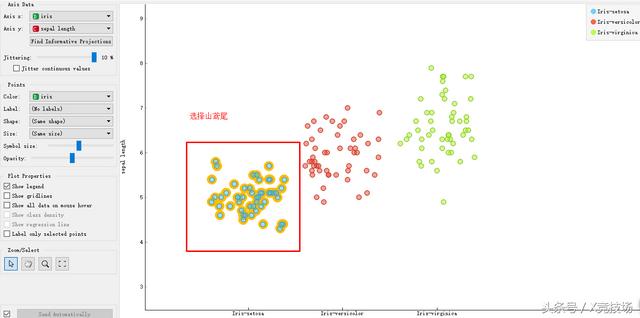
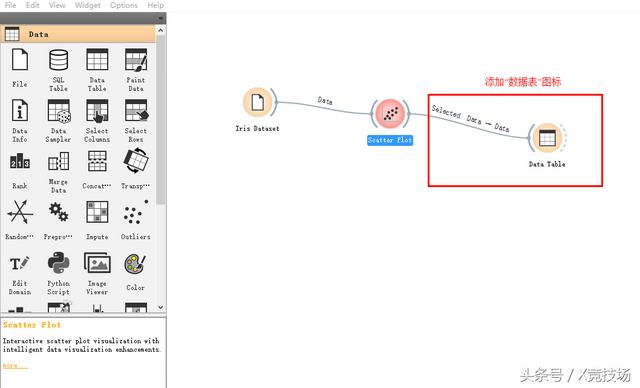
第七步:返回“Workflow”,按照第四步的步骤形成“Data Table”(数据表)图标。
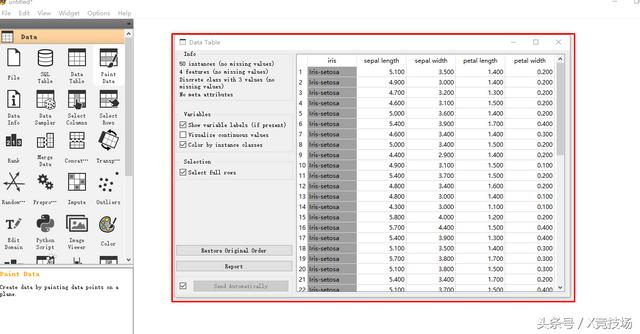
第八步:双击“Data Table”,刚才在图里选定的“山鸢尾”数据出现了。
鸢尾花数据集的目的就是通过每朵花的四种特征的数值将其分到对应的类中。以后我们将训练数据,让它可以根据给定的鸢尾花数据来判定它属于具体哪一个类别。







