编辑:在电商软件中搜索一个产品,页面上会显示很多相关的产品。这些页面是如何显示的?为什么会这样显示?本文作者以电商产品为例,分析其页面排名系统,希望对你有所帮助。

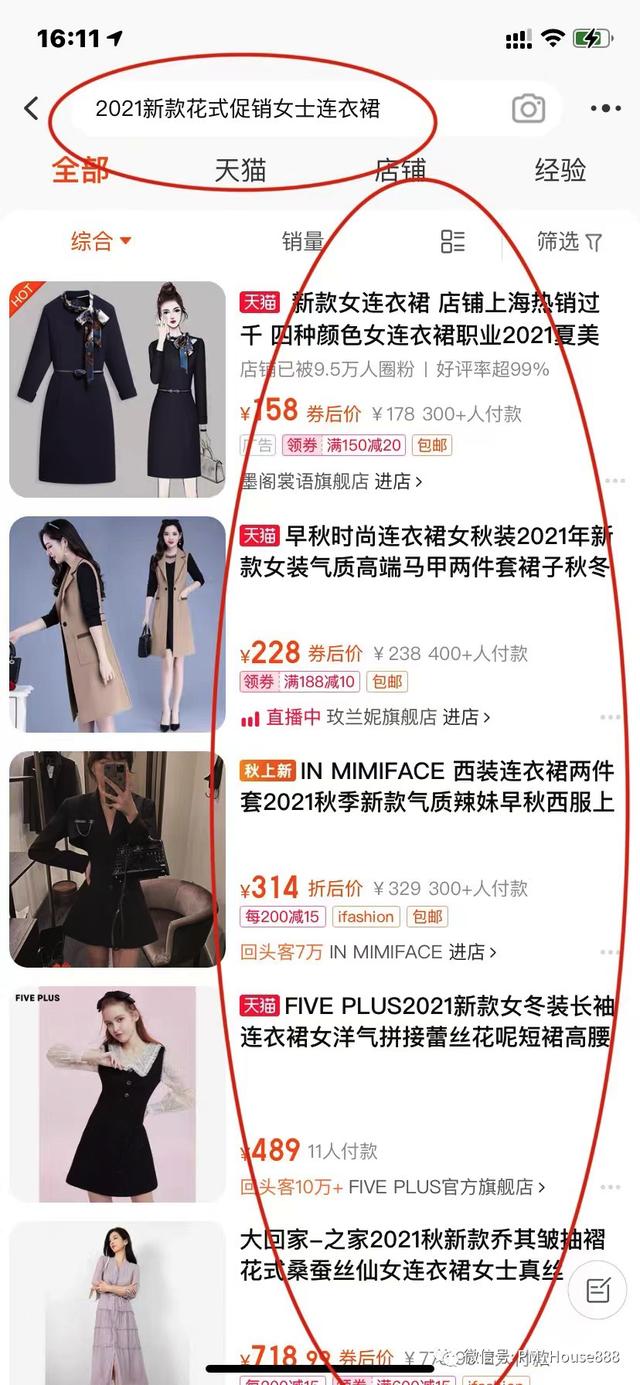
在上一篇文章中,我们分析了一个电子商务搜索系统的业务和召回分析器及模型。例如,当用户在淘宝APP搜索框中输入搜索关键词“2021新款花式促销女装”时,搜索系统会通过分析器和各种模型了解用户的搜索意图,进而达到召回产品的目的(这一块的原型将在“电商搜索系统详解系列”的下一个三部曲中推送给大家);
然后考虑一个问题。用户搜索“2021新款花式促销女装”后,页面如何显示,为什么会这样显示?依据是什么,如下图?
这就是我们今天要讲的内容。往下看:
在分析这一块的内容之前,我还是再次引用现实生活中的场景模型:
某公司产品总监需要招聘一名有丰富中台教育行业经验的产品经理,BOSS直聘的职位描述JD(职位描述)增加了有中台教育行业经验的招聘要求,所以以下求职者前去面试:
现在,假设你是这家公司的产品总监,你该怎么选择?别看下面,先想;
其实答案很简单。你必须选择一个适合这个职位要求的。那么什么是合适的,判断的依据是什么?如何评价这四位求职者担任产品总监?
现在一些大公司都购买了在线招聘系统,HR和产品总监直接将这四位求职者的面试结论用文字输入到这个招聘系统中,系统会给出一个建议分数,提供给产品总监和HR人员,供决策评估和参考。当然,没有这个网络招聘系统也没关系。最土的方式就是手工填写面试考核表,手工打分,但是这种方式的打分比较主观。
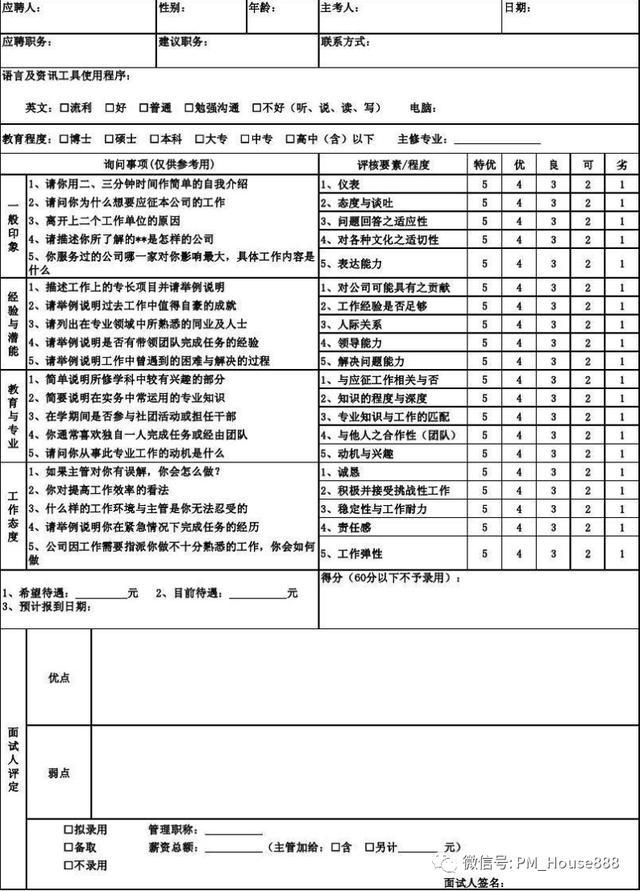
所以最后的结论就是给每个求职者打分,然后通过打分给B、C、D、E四个求职者排名,排名第一、第二、第三、第四,最后选出最优秀的候选人。
好了,我上面说的就是招聘工作。想想吧。这是不是我们每年高考选拔最优秀考生的相同方式?同样的场景模型,我们尝试搬到线上,应用到召回产品的分拣上。然后看:
那么,问题来了。同样的场景模型搬到线上,就会涉及到召回产品如何评分的问题。这是核心。人类有大脑,可以进行主观判断,但计算机没有眼睛,没有感觉系统,所以不能像人一样思考。所以我们需要做的就是向他输入一系列评分规则,计算机就可以对召回的产品进行评分和排序,从而达到我们的目的。接下来,我们来看看排序策略。
02 排序策略回想之前浙江卫视的中国好声音节目。那些在电视屏幕上看到的歌手,一定是提前开始了试演,然后一步步通过试演,才参加电视歌唱比赛的。如果没有试镜,只要报名,大家都可以直接在电视上唱那首歌。岂不是要累死浙江卫视的工作人员?于是选手们通过试镜,一步步竞争,一关接着一关,最终选出前100名选手参加电视歌唱比赛。
我们采用同样的程序。召回的产品(因为这个数量级也是非常巨大的)都是先海选,再选。很多业内人士称海选为粗选,所以召回的产品要先进行粗选,通过粗选把所有可能符合用户意图且质量相对较高的产品(比如10000个召回产品)筛选出来,再对筛选结果(10000个召回产品按筛选排序)进行优化,最后选出前1000个入选产品。
搜索引擎本身对检索性能要求很高,所以需要采用前面提到的两阶段排序流程:粗排序和细排序。粗略排名就是上面说的海选。我们可以从搜索结果中快速找到高质量的商品,取出前N个结果按照精细的排名进行评分,最终将最好的结果返回给用户。所以一般来说,在搜索系统中,粗排列对性能影响很大,细排列对最终排序效果影响很大。所以要求粗排列尽量简单有效,只能提取数据库表中的关键因素(字段)。关键问题在于如何得分。在这里,我们将介绍常见的评分策略:
首先,我们引入一个新概念——表达式计算方法。
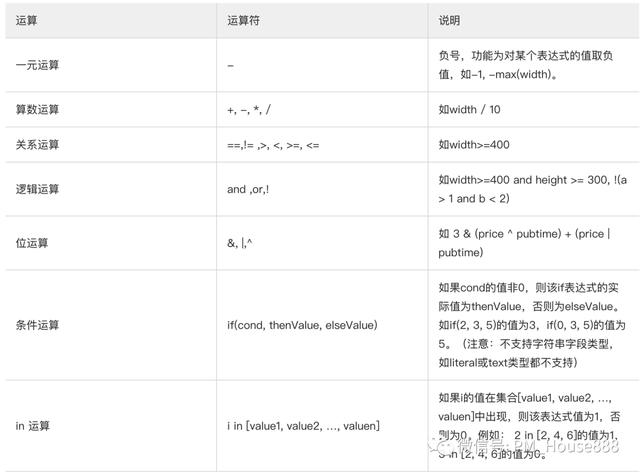
所谓表达式计算方法:通俗地说,就是通过不同的计算公式,计算出每一个召回产品与用户意图的相关度。从某种意义上说,这个关联度就是得分的分数。业界一般称这个过程为关联得分。基本运算(算术运算、关系运算、逻辑运算、位运算、条件运算)、数学函数、排序特征等常用计算公式。
基本操作:
数学函数:
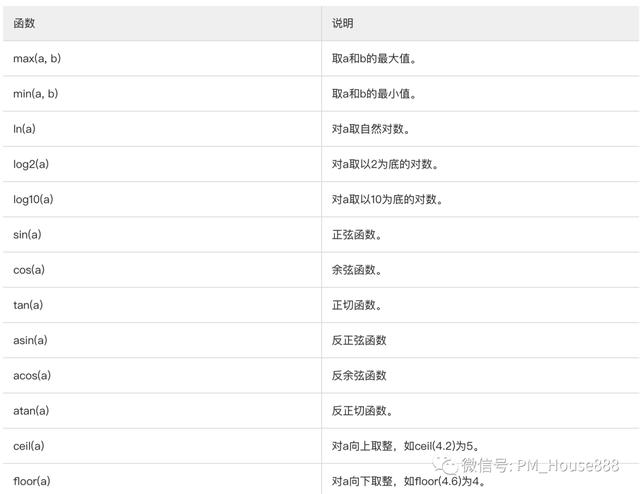
以上两个函数比较简单,高等数学里也有内容,这里就不赘述了。我们来看看上面提到的rough row常用的几个功能(以下以天猫搜索为例):
关键词相似度分为文本相似度函数:用于计算用户输入的关键词文本与召回产品的相关度。值越大,相关性越高;
GoodsTime函数:用于计算召回商品到现在的时间,一般取(0,1)之间的值。一般值越大,列出的商品越接近当前时间,越容易在用户界面显示。
类别预测函数CategoryPredic:用于计算用户输入的关键词与商品类别的相关度。这里需要仔细解释一下类别预测:

所谓品类预测,是指通过计算机算法对搜索到的关键词和商品进行预测。
比如用户在淘宝App搜索框中输入关键词“苹果”,品类预测会计算商品所属的品类与输入的关键词“苹果”之间的相关度。品类和关键词的相关性越高,产品的排名得分就越高,也就是上面说的相关性得分越高,这样产品就会排在前面。借助下面两个图,更好理解:
第一张图:搜索的关键词是“苹果”,既有手机产品,也有食品产品。左图是没有使用品类预测模型评分,所以食品苹果也被召回,排名第一。右图是使用品类预测模型后的评分和排名效果。
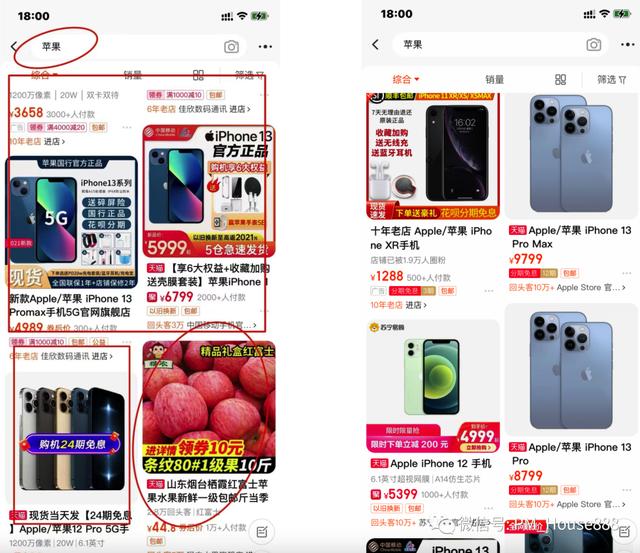
用户输入“苹果”,找到一批产品,其中一批归类为“手机”,另一批归类为“食品”。根据计算机大数据对所有用户的搜索历史行为的分析,发现在搜索“苹果”的人中,点击归类为“手机”的产品的人比归类为“食品”的人多得多。类目预测会给出“手机”类目与“苹果”类目的相关性高于“食品”类目与“苹果”类目的相关性的预测结果,所以在计算每个商品的相关性得分时,“手机”类目的商品会比“食品”类目的商品得分高,所以“手机”类目的商品会排在前面,从而提高搜索业务。
所以我们在做产品的原型设计时,也要考虑搜索到的关键词和商品类目的相关性,需要在原型设计中加入类目预测模型的设计。
再来来回回看,前面说过,排序的首选是海选,也就是粗排,粗排之后的产品结果再进行细排。粗排已经提到了,怎么细排?
还需要通过函数计算搜索到的关键词与商品的相关度。常见功能包括:
文本关联功能:
地理相关性:
及时性:
算法相关性:
功能性:
你不需要研究以上函数的细节,只需要看看函数的中文解释就可以帮助你理解和消化,知道如何统计精确的分数,统计哪些维度。如果你还是不懂他们,可以和我交流。
现在,大家一定很好奇。为什么用户没有提到他们最关心的产品的受欢迎程度?别担心,别担心。接下来引入一个新概念——人气模型,针对搜索人气高的商品如何排序。
上面说的类目预测模型是要实时计算的,而人气模型是可以离线计算的,一般称为离线计算模型,这也是淘宝和天猫搜索最基本的排名算法模型。
流行度模型会计算并量化每个产品的静态质量和流行度,称为产品流行度得分。最开始流行的模式是来自淘宝的搜索业务,但实际上这个模式对于其他搜索场景也是非常通用的。在非产品搜索场景中,流行度模型还可以计算索引产品的流行度。比如在一个论坛中,你可以通过人气模型对更多的帖子进行排序和搜索,并将这些帖子的内容优先展示给用户。
那么,对于一个商品来说,这个人气模型是如何计算出来的呢?毕竟系统的目标是通过这个模型计算出商品的受欢迎程度,然后进行排名排序,对吧?
通常,流行度模型从四个维度计算得分,如下所示:
第一维度:实体维度;
比如:商品、品牌、商家、品类等。
第二个维度:时间维度;
例如:1天、3天、7天、14天、30天等。
第三个维度:行为维度;
比如:曝光、点击、收藏、购买、购买、评论、好评等。
第四维:统计维度;
比如:数量、人数、频率、点击率、转化率等。
每个特征从上述四个维度中的一个或两个维度进行组合,然后从历史数据中统计组合特征的最终特征值:
例如:
上述方法产生的结果的数量级相当于计算四维的笛卡尔积,然后对笛卡尔积的分数进行排序;
好了,说起现在用来分拣召回商品的算法,目前知道的就这么多,当然能力有限,一些搜索细节还有待进一步探索;
03 召回与排序总结

我们先把上一篇文章和今天讲的内容简单总结一下。当用户在淘宝APP搜索框输入“2021新款花式促销女装”时,搜索引擎系统首先要通过上一篇文章提到的分析器来理解用户意图,通过语义理解、命名实体识别、拼写纠错、停用词模型等手段来理解用户意图。然后通过这个意向电脑,去后台数据库搜索所有符合意向的商品。在检索到商品后,搜索引擎系统首先通过各种函数和模型对商品进行粗略排列,然后对粗略排列的结果进行精细排列。精细排列的基础就是上面的函数和模型,当然还有品类预测模型和人气模型。这是大概的过程。
这还没有结束。首先看下图:
想一想,上图左图的热搜背景和热搜列表是怎么来的,右图的下拉提示是怎么出现这样的?这是原计划今天需要告诉你的引导和排序内容;
我们将在下一篇文章中继续分享指南排序部分的内容,今天就到这里。再见!
04 预告


本文由@产品研究站原创发布,人人都是产品经理。未经许可,禁止转载。
图片来自Pexels,基于CC0协议。