
一:搜索系统概述
在互联网崛起的过程中,搜索起到了至关重要的作用。我们熟知的谷歌和百度都是全网搜索引擎,对互联网的发展起到了强大的推动作用。在电商垂直领域,搜索是一个无处不在的工具,也是每个电商平台的主要流量入口。它集成了海量数据处理和查询、机器学习、深度学习等技术。对时效性和并发性要求非常高。Suning.cn搜索是一个垂直电子商务搜索引擎,具有商品、推荐、金融和虚拟商品功能。
苏宁的搜索系统主要经历以下三个阶段:一是2008-2011年的搜索引擎商业版;二、2011-2015年基于开源的搜索引擎;2016年将走自主研发之路,打造符合苏宁商业模式的高性能搜索引擎。无论是基于开源还是自主研发,搜索系统在历年大促(如苏宁818、苏宁11.11 O2O购物节)中经历了数千万UV、上亿PV,实现了零问题、零事故,有效保障了大促的圆满达成。
二:搜索系统架构
搜索主要分为离线计算和在线实时计算两部分。离线计算主要包括数据处理、加工和数据索引生成。在线计算主要包括流计算、准实时增量索引、实时用户查询分析、查询响应、排序等功能。整个架构如下:
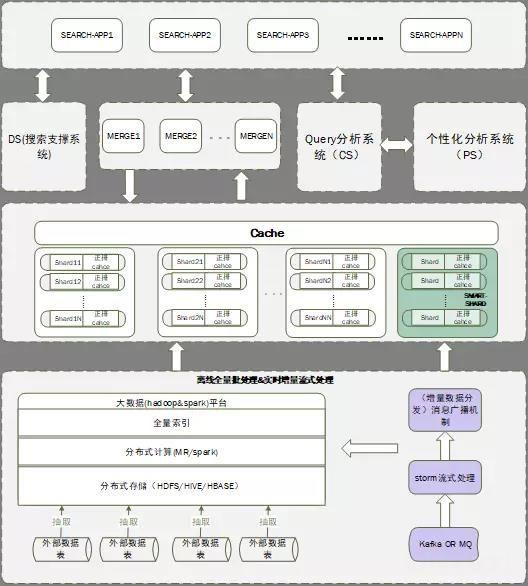
1.采用轻型倒排机制,实现倒排索引的准实时更新。
2.定期切换在线状态,同步循环中的索引,减少SMART-SHARD的倒排长度。
3.大量使用前排缓存,无需索引数据即可实现准实时更新,提升排序的时效性。
4.增加缓存机制,在发动机机器故障时缓冲机舱。有效降低机房事故率。
5.搜索支持系统提供了对外围系统接口信息的统一访问,减少了过多请求的数量。
6.查询分析实现了中心词识别、类别预测、组件识别、纠错、扩展、个性化标签等一系列查询分析功能。个性化标签内容在个性化服务系统中单独处理,需要查询分析系统调用和打包。
基于以上特点,搜索采用短链+前排的方式实现索引更新的秒级更新,保证了流入搜索的数据能够被快速索引并及时响应用户。11月11日 今年苏宁O2O购物节,数亿价格变化无需缓存数十亿次访问即可更新。在排名层面,目前电商的底层排名主要基于规则和机器学习(LTR)。在上层,有政策、营销策略的排序规则,以及门店、品牌、品类的多样性(当然像上层的排序会在单独的排序系统中处理,上层结构中没有体现)。其中,机器学习和训练的数据是半年内的数据。这里数据是差异化的,不是一般的半年数据。有些数据其实只有四分之一的数据,有些快消品和季节相关的商品是苏宁搜索精心挑选的。如果使用太过笼统的数据,实验发现效果与人工拟合权重排序没有特别大的区别。下面重点介绍以下搜索工具:
1:搜索工具-用户反馈系统
那么,当用户访问搜索系统时,苏宁搜索系统需要了解用户的点击、访问和购买情况。如果没有这些数据,搜索只是一个静态的输出引擎,当然不是我们追求的目标。我们期望的系统是一个可以和用户互动的系统。通过用户过去的行为数据和现在的行为数据,可以调整搜索排名,保证给用户更合理的排名结果。系统的整体架构如下:
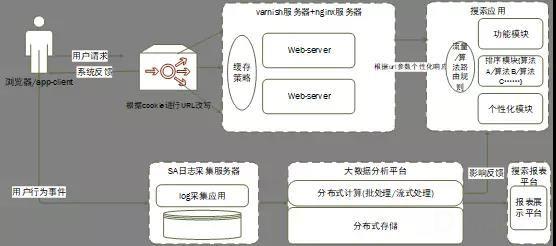

1.实时收集用户行为(点击、翻页、收藏、购买等。)
2.数据流,将实时用户行为数据与历史数据相结合,生成供产品/运营使用的报告。
3.实时数据处理用于反馈影响在线排序。
4.因为底层的排序规则是由不同的模块组成的,所以这里有一个路由规则,通过它将一定比例的用户分配到不同的排序规则中。
2:搜索工具-用户意图识别系统
分析的总体结构如下:
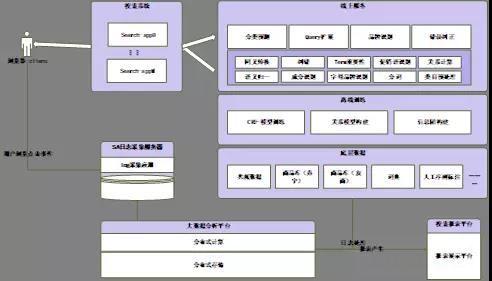
整个处理流程如下:
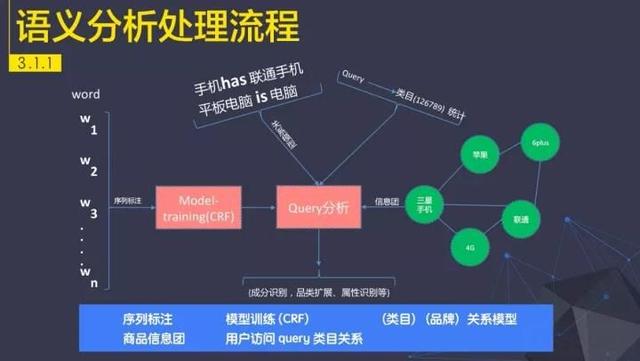
整体画面如下:
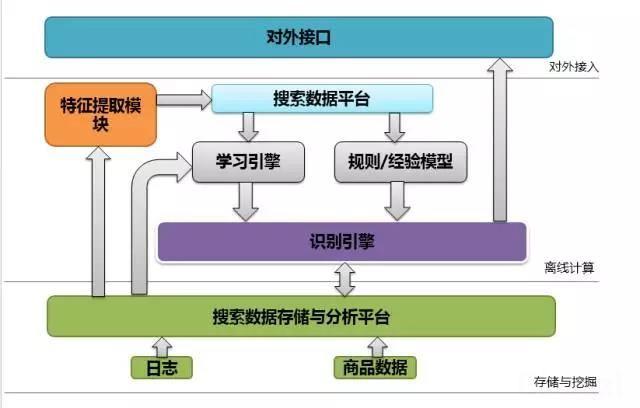
系统辨识可能比较容易理解,因为系统是一个二元分类问题,可以用二元分类算法(可以实现LR或者NBM)对输入数据进行分类。要么输出作弊,要么不作弊。为了降低出错率,系统。使用黑白分类器。最小化错误率。
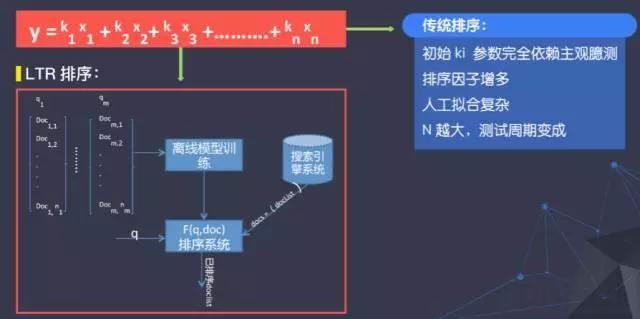
4:搜索工具-LTR
前期搜索的排序叫一个累,一个线性公式,一堆要排序的因素,每个因素,拍着脑袋,权重刚出来,结果就是这个商家反馈,那个反馈。然后分析师不断调整。又累又吃力不讨好。为了减少人为调整因素的权重,需要收集查询-文档列表数据,并根据用户行为对其进行标注。在海量数据的基础上,通过机器学习的方法拟合出各因素的权重。如下所示:
三。搜索系统的智能应用
这里的智能应用并不一定意味着我们理解苹果Siri和微软萧冰。在这里,我们将简化用户操作,降低运维成本。从经验拍手到数据支持的过程,叫做搜索智能应用。这里主要举两个例子:一是价格区间划分,二是默认选择。
1:搜索的价格范围划分:

& ampOslash收集用户行为和商品的相关数据;
& ampOslash数据融合和特征转换
& ampOslash隔离林检测并拒绝异常数据;
& ampOslash模型训练,包括训练测试和模型选择;
& ampOslash将训练好的模型部署到在线服务系统,并用于离线处理;
在这个过程中,最大的干扰就是数据噪声,有些数据是非常离散的。如何选择数据将决定该功能的质量。如何处理这些有噪声的数据成为该功能成功与否的关键。经过不断的采样和不断的处理,最终在实验中发现采样隔离林来检测和剔除异常数据能够达到预期的效果。
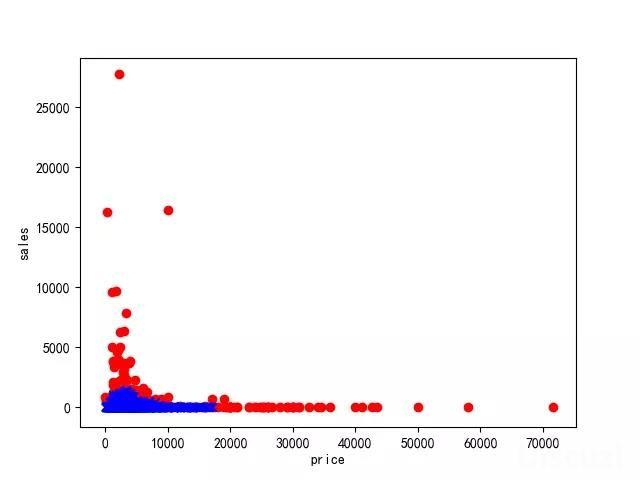
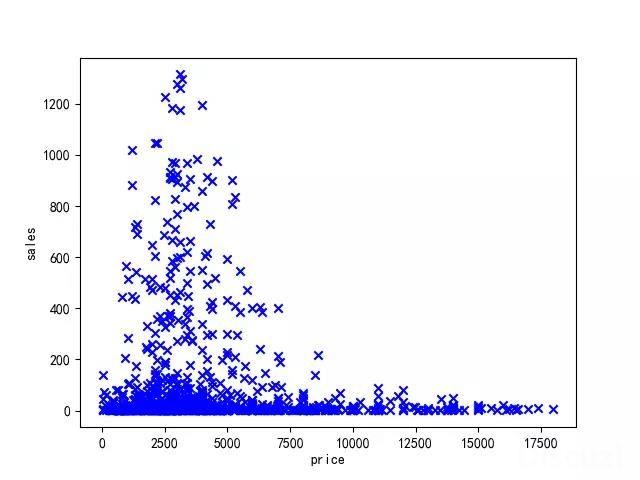
2:默认过滤/选择功能:

四:场景搜索应用
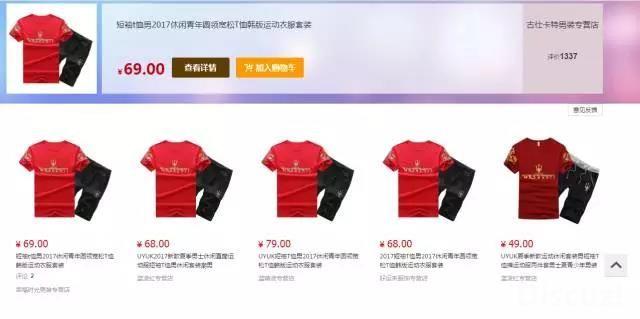
1:图片搜索:
在某些场景下,用户无法表达自己的意图或者用户表达了自己的意图,但是用户的表达过于个性化,最终导致引擎没有输出或者输出结果不理想。比如在街上看到别人穿的很漂亮,就上去问,担心尴尬。那么这个时候如果你手里拿着手机,只需要简单的拍照就可以检索到相同款式的产品。想想这个功能就兴奋。这个技术就是图像识别技术。应用于搜索场景时,就是图像检索。通过图像检索,召回相似度高的产品。下图是苏宁的图片搜索效果:
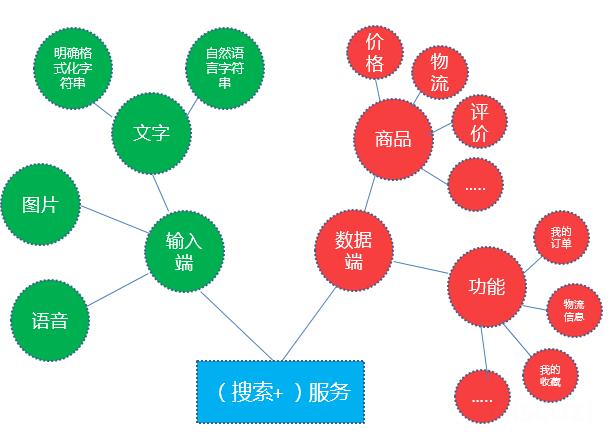
2:(搜索+)服务:
搜索+服务,我们都知道搜索可以检索网页和产品,因为它是海量的,所以搜索。互联网的爆发导致了用户可用功能和产品的爆炸。“搜索+”的意思是搜索产品或功能。让用户在最短的时间内找到最好的产品和最常用的功能。如下图:
当用户打开搜索时,在即将翻页之前没有点击行为,是否希望用户继续翻页?或者在这种场景下,提示用户“有更精准的召回功能,可以尝试使用这个功能,里面包含了你想要的商品”,那么这个商品必须具备识别用户意图和用户自然语言表达的能力,同时利用商品的多维度标签提醒用户为什么召回这样的商品。所以,让用户更自然地表达自己的想法,可以覆盖更多的信息,融入更多的情感因素。让用户更清晰地表达自己的需求。同时利用多维度的用户分析和丰富的产品内容展示,给用户精准的产品召回。下图是搜索创新的精准搜索:








