
大家好,我是强哥。
这几天郭的文章《灭鬼之刃》即将上线。强哥的一个朋友很喜欢《灭魂之刃》,可以说是痴迷了。每次有新文章上线,都会第一时间观看。虽然这家伙这次上线之前已经看过了,但是这个消息还是让他激动不已,拉着我和他一起重温。

不是,昨天他找我要了一个爬虫代码,还上网搜了各种跟鬼刃有关的图片。可是,我把代码给他不到一个小时,这家伙又来找我,发誓要跟我算账,说他用了我的代码。起初,他爬得相当好,非常舒服。可是过了近半个小时,发现他经常看图片的两个网站都爬不上图片了。而且没有软件,他无法用自己的电脑浏览器访问这两个网站,这让他很恼火。
听他这么一说,我大概明白了,十有八九应该是爬的有点猛,IP被封了。用手机5G网络看对应的网站,还是可以正常访问的,没错。
我赶紧给这家伙讲了一些关于爬行动物的法律知识。爬虫虽好,能解放我们的双手,但太凶了,请不到茶。几年前,又有一家公司的CTO兼程序员被捕判刑。所以我还是要控制频率,不要无节制...
他做了一次演讲,但现在他想继续。他该怎么办?没办法,只好找经纪人了。这家伙是化石白嫖党。没有办法让他付钱。强哥要出自己的大招了。
IP代理池没错。要解决这个问题,最简单易用的方法就是IP代理池,也就是我们可以得到很多可以正常使用的代理IP。那么我们在使用爬虫的时候,并不是直接把请求发送到目标网站,而是借助代理IP,先把请求发送到代理服务器,然后代理服务器帮我们把请求发送到目标网站。这样,如果被目标网站发现,被封的也是代理商的IP,而不是我们自己的IP。
至于为什么要用代理池,主要是怕同一个代理IP一直被屏蔽就无法访问,所以宁愿多几个。

因为我们想要白嫖,我们必须寻找开源项目。既然要找开源项目,那就必须足够专业,匹配强哥的代码。所以,这一次的主角是崔的开源项目:ProxyPool,Python3 Webcrawler开发实践的作者。
先简单介绍一下项目结构:
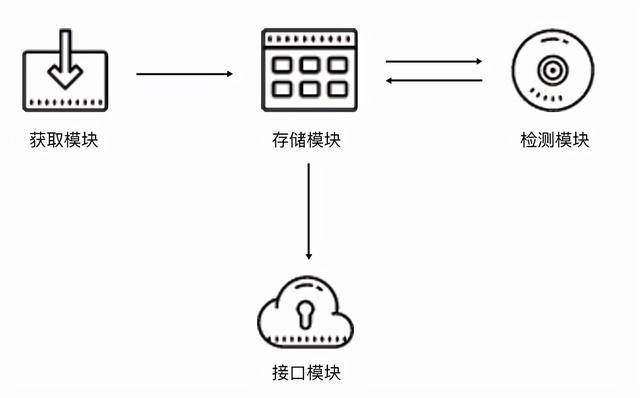
代理池分为四个部分:采集模块、存储模块、检测模块和接口模块。
该项目的原理是,只有在提供IP代理池的各大网站获得IP后,该IP才会被保存下来供我们使用,然后该程序就可以进行测试和使用,这相当于帮助我们节省了寻找免费IP代理的时间。
当然,如果只是拿来用的话,也不用太在意这些细节,直接冲就好了。
上手ProxyPool需要在本地运行。运行后会在本地公开一个接口地址:http://localhost:5555/random。可以通过直接访问获得随机可用的代理IP。
在Docker模式下下载完项目图片后,我用docker-compose up命令运行服务,然后浏览器访问效果如下:
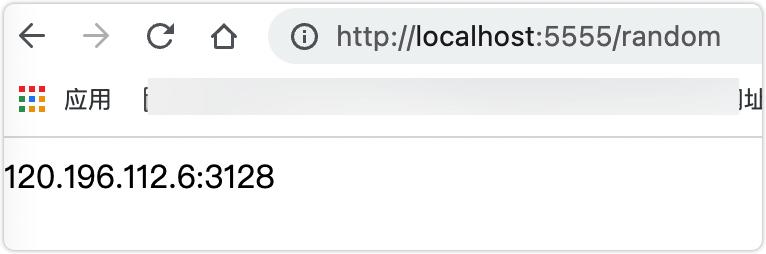
是的,返回的120.196.112.6:3128是代理IP。
Docker图像下载方法:
Docker拉Germey/代理池 也想有个小伙伴。自己去GitHub吧。用起来还是很简单的:https://github.com/Python3WebSpider/ProxyPool.
怎么帮朋友现在工具已经可用,只需将我之前给朋友的爬虫代码放在上面就可以了。当然,我不会在这里直接暴露我的爬虫代码。给我一个官方的样本代码,和我写的差不多:
导入请求 proxy pool _ URL = & # 39;http://127 . 0 . 0 . 1:5555/random & # 39; target _ URL = & # 39;http://httpbin.org/get' def get _ random _ proxy(): & # 34;"" 从proxypool中获取随机代理 :return:proxy & # 34;"" return requests . get(proxy pool _ url). text . strip() def爬网(URL,proxy): & # 34;"" 使用代理抓取页面 :param url:页面url :param proxy: proxy,如8 . 8 . 8 . 8:8888 :return:html & # 34;"" proxy = { & # 39;http & # 39: 'http://& # 39;+proxy } return requests . get(URL,proxy = proxy)。text def main(): & # 34;"" main方法,入口点 :return:none & # 34;"" proxy = get _ random _ proxy() print(& # 39;获取随机代理& # 39;,proxy) html = crawl(target _ URL,proxy) print(html) if _ _ name _ _ = = & # 39;_ _ main _ _ & # 39: main() 如你所见,使用代理的关键就是这句话:请求。get (URL,proxy = proxy),直接把你得到的代理IP拿到代理上就行了。
这里,我们还应该提到代码中使用的另一个开源项目的地址。是的,是http://httpbin.org/get.,我们可以根据这个地址返回的数据判断我们发起访问这个地址的IP。
直接浏览器访问的强大效果:
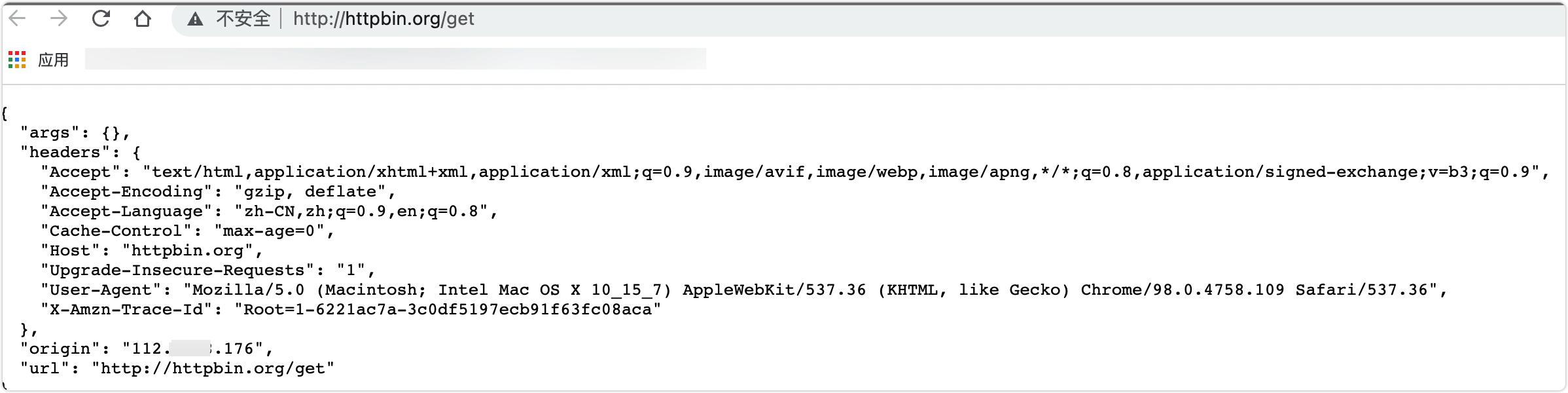
您可以看到这里使用了本地IP。
使用上述代理代码访问的效果:
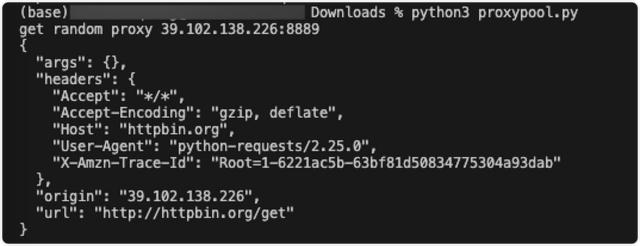
可以看到返回的原点确实使用了代理IP。换句话说,我们的IP代理池已经被成功使用。
强哥的朋友拿到了新的爬虫代码,控制了频率。终于,他不再被IP封了。顺便给我发了张图:

怎么说呢?你这种不咬竹子的豆子不是好豆子。
搞更深点除了crawler之外,还会在哪里使用IP代理池?
良好的.....如果你看了强哥朋友的上一篇文章,应该能猜到,当然是DoS攻击。其实爬虫和DoS攻击还是有交集的地方。如果爬虫控制不好,很可能会变成DoS。这个我就不多展开了。
强哥前天也看了一个DoS攻击项目,利用反射原理进行攻击。哈哈,之前在看DoS攻击方法介绍的时候学的。这次看到代码还挺激动的,有机会给大家介绍一下。







