

本文以豆瓣电影(非TOP250)为例,从数据抓取、清洗和分析三个维度入手,详细讲解和还原了数据抓取和分析的全链路。

作者周志鹏
编辑|郭蕊
朋友,暑假已经过去一大半了。
虽然这个遥远而炙热的名词与作者无关,但工作犬,穿着裤衩,吹空调,在房间里吃西瓜,看电影,依然是假期最好的打开方式。现在裤子,空笔记,西瓜都唾手可得,压力都在电影这边。
至于电影推荐和排名,豆瓣是个好地方,但是TOP250电影的排名太经典了,有点老套。想点新的,就按照默认的“最高分”Emmm排序,结果好像比较小:
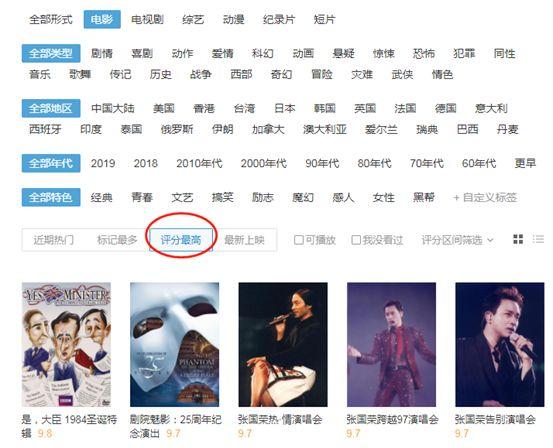
按照年龄筛选,发现返回的结果远不如预期。
我该怎么办?我们不如自己对豆瓣电影做一个更全面的抓取和分析,然后DIY评分规则,根据电影的上映年份,做一个各年龄段的百大电影榜单。

数据搜索
1。网站法律探析
听的人越多,看的人越多,这个分数就越有说服力,于是我们去导航页选了“Mark Most”。(虽然多做标记不完全等于多看,但也差不多。)
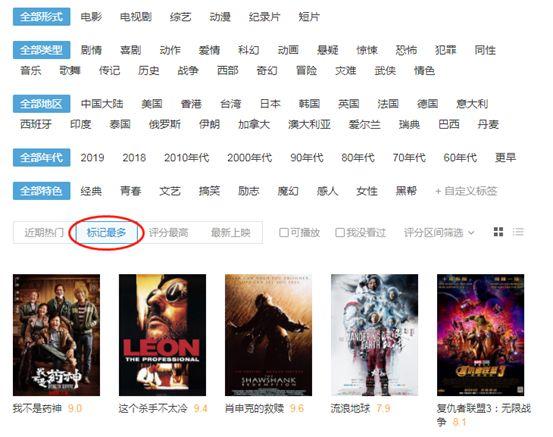
要找到网站的变化规律,常规的套路是先右击“查看元素”,然后反复点击“加载更多”刷新页面找到规律。
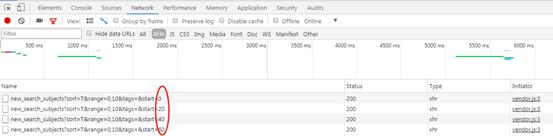
URL规则异常简单,初始URL不变,每页增加start的值20就可以了。
一页就是20部电影。一开始我们设定的是爬9000部电影,也就是450页。
2。单页解析+循环爬行
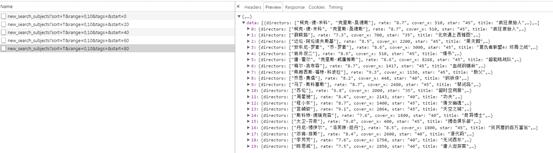
豆瓣永远贴心,每个页面都是JSON格式存储的常规数据,在抓取和清理上省了不少事:
在这里,我们只需要将用户代理伪装在标题中就可以愉快地爬行了:
headers = { ' User-Agent ':' Mozilla/5.0(Windows NT 6.1;Wow 64)苹果WebKit/537.36 (Khtml,像壁虎一样)Chrome/63 . 0 . 3239 . 132 Safari/537.36 ' }代码直接进行单页解析:
def parse_base_info(url,Headers):
html = requests . get(URL,Headers = Headers)
bs = JSON . loads(html . text)
df = PD . data frame
for I in bs[' data ']:
casts = I[' casts ']# staring[/br Cover = I[' Cover ']# poster
Directors = I[' Directors ']# Director
M _ ID = IDataFrame({ '主演':[演员],'海报':[封面],'导演':[导演],。Tag': [star],' title': [title],' website ':[URL]})
df = PD . concat([df,cache]]
Return df然后我们写一个循环来构造我们需要的450个基本网站:
#你想抓取多少页?其实你加载了多少次
def format _ URL(num):
URLs =
base _ URL = ' https://movie . douban . com/j/new _ search _ subjects?排序= T & amp范围=0,0,10 & amp标签= % E7 % 94 % B5 % E5 % BD % B1 & ampStart = {}'
for I in range (0,20 * num,20):
URL = base _ URL . format(I)
URLs . append(URL)
return URLs
[
结果= pd。DataFrame
#查看对URL中的URL搜索了多少页面
Count = 1
: DF = parse _ base _ info(URL,Headers = Headers)
result = PD . concat([result,DF])
time . sleep(random . random+2)
print('我搜索了% d'% count的页面)
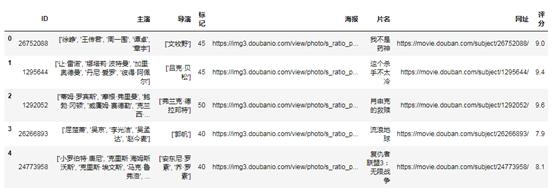
接下来,我们还想分批访问每部电影,以获得电影每个明星的收视率比例的更丰富信息,然后我们想根据收视率分布进行排序。
3。爬单部电影的细节:
当我们打开单部电影的网站时,诀窍就是直接点击右键,查看源代码,看看我们想要的字段是否在源代码中。毕竟爬静态源代码是最省力的。

电影名?是啊!导演信息?是啊!豆瓣评分?还在!CTRL+F搜索显示,我们需要的所有字段都在源代码中。爬上去太容易了。这里我们使用xpath来分析:
def parse_movie_info(url,headers = headers,IP = ' '):
if IP = = ' ':
html = requests . get(URL,headers = headers)
else:
html = requests . get(URL,headers = headers,proxy = IP)
BS = etree.html(html . text)
# Title = BS . XPath('//div[@ ID = " wrapper "]/div/h1/span ')[0]。year = bs . XPath('//div[@ id = " wrapper "]/div/h1/span ')[1]。text
# movie type
M _ type =
for t in bs . XPath('//span)M _ type . append(t . text)
a = bs . XPath('//div[@ id = " info "]')[0]。XPath(' string ')
# length
m _ time = a Region
area = a[a . find('国家/地区:')+9:a.find('n语言')] # Region
#评分者人数
Try:
People = bs . XPath(')。text
#分数分布
Rating = { }
Rate _ count = bs . XPath('//div[@ class = " Ratings-on-weight "]/div ')
for Rate in Rate _ count:。rating[rate . XPath(' span/@ title ')[0]]= rate . XPath(' span[@ class = " rating _ per "]')[0]。text
except:
people = ' None '[/br br/]try:
brief = bs . XPath('//span[@ property = " v:summary "]')[0]. text . strip(' n u 3000 u 3000 ')
brief = ' None '
try:
hot _ comment = bs . XPath('//div[@ id = " hot-comments "]/div/div/ptext
except:
hot _ comment = ' None '
Cache = PD。DataFrame({' title': [title],'上映时间':[年份],'电影类型':[m_type],'电影长度':[m_time],
' region': [area],' raters ':热评':[hot_comment],'网站':[URL]})
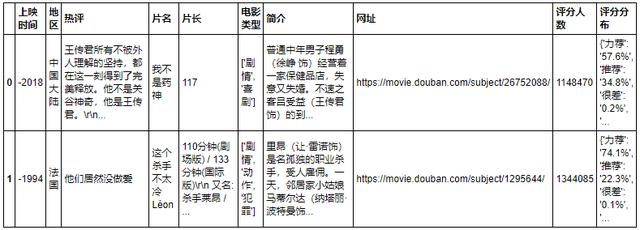
返回缓存第二步:我们已经拿到了9000部电影的所有网站,只需要写一个循环,批量访问即可。但是goose,尽管设置了访问时间间隔,我们还是会发现,damsel在爬了上千个页面之后,还是会封禁我们。
回想一下,我们没有登录,也不需要cookies来验证,只是因为频繁的访问骚扰了豆娘。那个问题还是比较容易解决的。我不想呆在这里。我想换个IP留在这里。各位朋友,我们发现单部电影的页面解析有一个默认的IP参数。我们只需要在旧IP被封禁后传入一个新IP。
PS:代理IP如果演示太长,网上有很多免费的IP代理(缺点是短且不稳定)和付费的IP代理(缺点是不免费)。另外需要强调的是,这里传入的IP如下:{ ' https ':' https://115 . 219 . 79 . 103:0000 ' }
movie _ result = PD . data frame
IP = ' ' #在此处构建自己的IP池
Count2 = 1
CW = 1
对于URL,名称在zip中(result ['URL'])。值[结果['标题']。Values [6000:]):
# for name,URL in errors。items:
try:
cache = parse _ movie _ info(URL,headers = headers,Ip = Ip)
movie _ result = PD . concat([movie _ result,cache])
# time . sleep(random . random)
print('我们爬了第一个:% d movie-Name))
count 2+= 1
除外:
print('滴滴滴,第{}个错误'。format(CW))
print(' IP is:{ } '。格式(IP))

数据清理
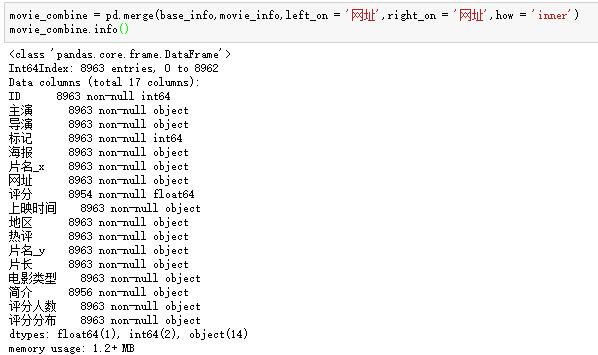
1。合并基本信息表和电影内容表
base_info表包含了我们批量抓取的电影的基本信息,而movie_info表则是我们进入每部电影时得到的感兴趣的领域的汇总。以下分析依赖于两个表,因此我们将它们合并起来:
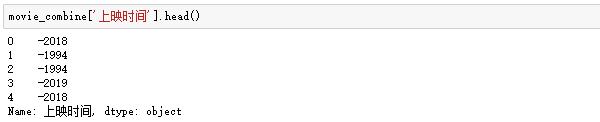
2。清除电影年份数据:
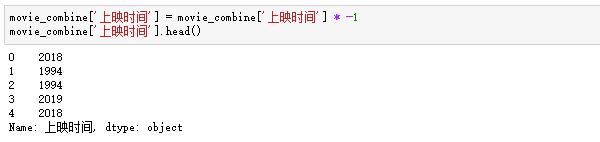
我们发现之前爬的发布时间数据不够规律,前面有个“-”:
去掉前面多余的符号,我们发现不管怎么用str.replace返回Nan,原来这里的熊猫默认所有数字都是负数,所以我们只需要把这一列的所有数字乘以-1:
3。分数的规则分布:
最终我们希望结合一部电影的整体评分(比如一部电影8.9分)和不同评分水平(5颗星的70%)进行分析。刚才我在抓取评分数据的时候,为了偷懒,用字典把评分等级和对应比例包了起来。但是鹅和熊猫默认把他当成字符串,不能直接当字典:

一道光?这个类似字典的字符串,用JSON解析,会不会变成字典?试一试:

结果,疯狂的错误:

错误似乎表明我们是最外面的引号,这就导致了问题。目前我们使用双引号(“{'a':1}”)。只能用单引号(' {'a':1} ')吗?先试试:

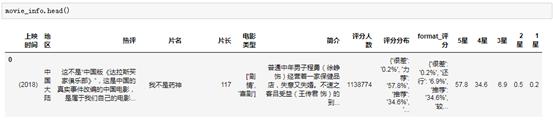
错误已解决。接下来我们把字典形式的分数拆分成多列,比如每个星对应一列,百分比的格式变成数值,写一个循环函数,用apply应用:
#将单列字典的分数分布转换为五列,每列为数值
def get_rate(x,Types):
try:
return float(x[Types]。strip(' % ')
除外:
pass
movie _ combine[' 5星。apply(get_rate,types = ' recommendation ')
movie _ combine[' 4星']= movie _ combine[' format _ score ']。apply(get_rate,Types = ' recommended ')
movie _ combine[' 3星']= movie _ combine[' format _ score ']。apply(get_rate,Types = ' OK ')
movie _ combine[' 2星']= movie _ combine[' format _ score ']。apply(get_rate,types = ' poor ')
movie _ combine[' 1 star ']=
好了,清洁工作到此结束。

数据分析
你还记得开头的旗子吗?我们想入选各年龄段的100部最佳电影名单。所以直接按年份划分电影,然后按电影评分排名就行了!
但是,鹅,这个听起来有点粗糙粗糙。如果只按照电影总分排序,会忽略内部评分细节的差异。例如,搏击俱乐部:
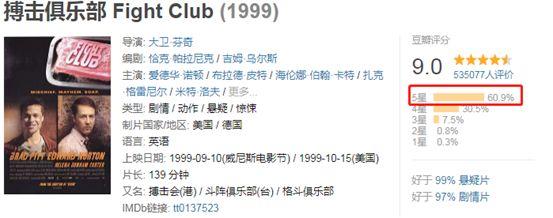
总分9.0,60.9%打5星,30.5%打4星。
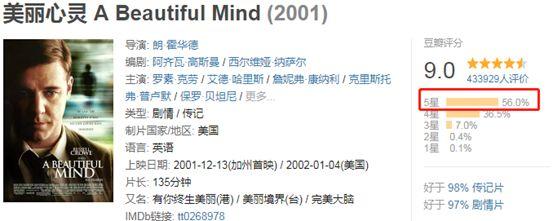
9分,美魂56.0%获得5星好评,比搏击俱乐部少4.9%,比4星数量多6%。可以不负责任地总结:两部电影都是9分经典,但观众对《搏击俱乐部》的5星倾向高于《美丽心灵》。
说到这一点,我们可以对电影评分的排名做一个简单的规则:先按照总评分排名,然后比较5星的比例,如果相同,比较4星,以此类推。这种评分和排序逻辑在PYTHON中应该不会太简单,只需要一行代码:
#根据总分,拥有5星、4星、3星的人数比例...以此类推
movie _ combine . sort _ values([' score ',' 5星',' 4星',' 3星',' 2星',' 1星'],升序=我们会发现这个排名的一些小瑕疵。有些高分片其实比较小众,比如《歌剧魅影:25周年演出》、《悲惨世界:25周年演唱会》。
我们要找的是人们喜闻乐见的电影排名。在这里,人数只能用收视率的多少来表示。我们先来看看所有电影的收视率分布:
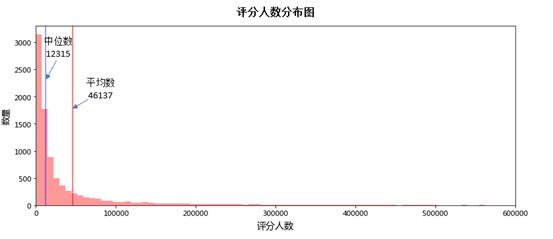
分数跨度极大。为了减少极值对平均值的影响,让中位数来衡量人们喜不喜欢,所以我们只留下大于中位数的分数。

然后,再看历年电影数量分布:
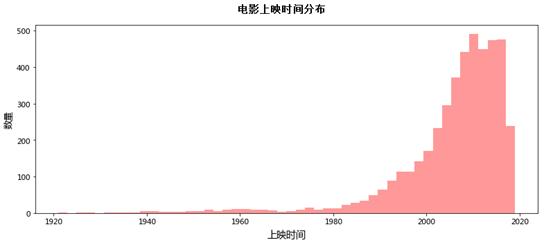
直到2000年初,放映的电影数量才接近200部,而更早期的电影数量在20年内似乎不到100部。为了让结果更直观,我们按年来统计电影的上映时间。涉及到对每部电影的上映时间进行分类,有点棘手。...
绞尽脑汁,终于找到了一个便捷的方法。首先,我构造了时间标签,然后我使用cut函数来划分发布时间,间隔为十年,最后我将标签传递到参数中。

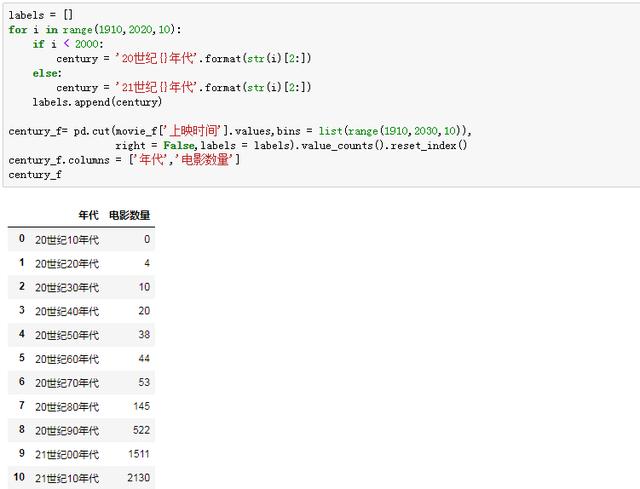
乐!数据直观的反映了每个十年的发行量,80年代以前真的少得可怜。看到这里,我不禁想起了我们最早设立的“制作年份TOP100榜单”的旗帜,因为缺少早期影片,完全站不住脚。
不要慌,一个优秀的数据分析师一定要本着具体问题具体分析的精神调整旗帜:
final _ rank = PD . data frame
for century,count in zip (century _ f.index,century _ f . values):
f1 = movie _ F2 . loc[movie _ f[' year ']= = century,:]1000:
return _ num = int(count * 0.1)
# 1000或以上,取前100个
else:
return _ num = 100
F2 = F2])根据上一步构建的century_f变量,结合各年上映的影片数量,筛选出1000部影片中不到前10%的影片,超过1000部的影片只筛选前100部。 结果,结果出来了。
在附上代码和榜单之前,我预感到大部分朋友都和我一样懒(他们不会仔细看榜单),于是我整理了不同年代的TOP5电影(其中有不到TOP5的),做了一个精英版的历史电影榜单。

从结局牛逼的《控方证人》,到为无罪真相辩护的《12怒汉》,再到重新诠释希望与坚韧的《教父》系列,《肖申克的救赎》,再到将灵感提升到新高度的《阿甘正传》。(我还没看过片子,只在榜单上看过这些。)
每一部好电影都是一块从高处落下的石头空。它总能在人们的心灵和湖泊上激起水和涟漪,唤起人们对生活、社会和人性的思考。烂片是从高处掉下来的空矿泉水瓶空。它摔得很厉害,但最终只会浮在水面上,让看过的人心疼,灵魂被污染。
有了新的电影排行榜,再也不用担心剧荒了。
抓取、清理、分析每一步的详细代码和完整的电影排名列表。详见https://github . com/seizeeveryday/da-cases/tree/master/douban movies。
作者:周志鹏,两年数据分析,在学习过程中深深感受到数据分析的趣味性和缺乏案例的无奈,于是开通了微信官方账号“数据不是吹牛”,定期更新数据分析相关技巧和有趣案例(包括实战数据集),欢迎大家关注和交流。
声明:本文由作者投稿,版权归其所有。
【结束】








