开源精选是我们在Github、Gitee等开源社区分享优质项目的专栏,包括技术、学习、实用和各种有趣的内容。本期推荐JD.COM App的后端中间件,毫秒级检测热点数据,毫秒级推送至服务器集群内存,大大减轻热键对数据层的查询压力。
对于任何无法提前感知的突发热数据,包括但不限于热数据(如同一产品的突发群发请求)、热用户(如恶意爬虫刷)、热界面(突发群发请求的同一界面)等。,可以在毫秒内准确检测到。然后,这些热门数据,热门用户等。被推送到所有服务器JVM的内存中,以大大降低对后端数据存储层的影响,用户可以决定如何分配和使用这些热键(例如,本地缓存热商品、拒绝热用户访问、融合热接口或返回默认值)。这些热点数据在整个服务器集群中是一致的,而且业务是隔离的,worker的性能是强的。
该框架经过多次压力测试,其性能指标主要有两项:
1检测性能:8核单机工每秒可接收处理16万个重点检测任务,16核单机每秒至少可流畅处理30万以上,实际压力测试达到37万,CPU支持稳定,无异常帧。
2推送性能:在高并发写入的同时,目前外推的性能大概是每秒10-12万次流畅。举个例子,如果有1000台服务器,一个工作人员每秒生成100个热键,那么1秒内就可以平滑推送100 * 1000 = 100000次,100000次全部在1秒内送达。如果少写,多推,纯推计数,框架每秒可以稳定推40-60万次,80万次的极限可以持续几秒。
单机每秒吞吐量(写+推)目前稳定在70万左右。
核心功能:
检测数据并将其推送到群集中的每台服务器。
适用场景:
再来看redis的热键、刷用户、限流等典型场景。
redis热键:
这种以前的解决方案更加丰富多彩,比较常见的有:
刷爬虫用户:
电流限制:
综上,我们会发现,虽然都可以归结为热键领域,但是并没有统一的解决方案。我们期待一个统一的框架,能够用热键实时感知解决所有场景。最好是不管是什么键,什么维度,只要我把这个字符串拼接起来,交给框架检测,设置一个判断它热的阈值(比如字符串2秒内出现20次),毫秒之内,应该是。
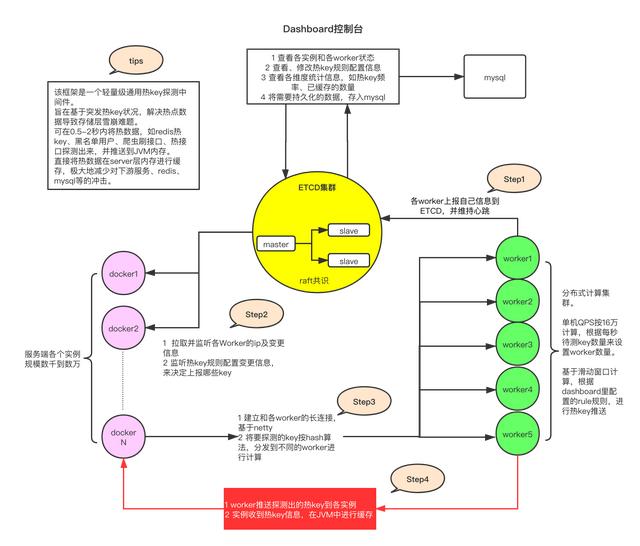
该框架主要由4个部分组成1。etcd集群
作为一个高性能的配置中心,etcd能够以最小的资源占用提供高效的监控和订阅服务。它主要用于存储规则配置、工作人员的ip地址、检测到的热键、手动添加的热键等。
2。客户端jar包
它是服务中添加的引用jar。介绍完后,你就可以用一种便捷的方式来判断一个键是否烫手。同时,jar完成键报告、监控规则更改、工人信息更改、etcd中的热键更改以及热键的本地咖啡因缓存。
3。工作者群集
Worker是一个独立部署的Java程序。它启动后会连接到etcd,定时上报自己的ip信息,让客户端获取地址,连接到总统。之后主要是积累各个客户端发来的待测密钥。当达到etcd中设置的规则阈值时,热键被推送到每个客户端。
4。仪表板控制台
控制台是一个Java程序,有可视化的界面,也连接了etcd,然后在控制台里设置每个APP的按键规则,比如热键2秒出现20次。然后,当工人检测到热键时,它会将该键发送到etcd,仪表板也会监控热键信息,并在仓库中保留记录。同时,dashboard还可以为每个要监控的客户端手动添加和删除热键。
综上所述,我们可以看到框架不依赖于任何定制的组件,与redis无关。核心是依靠netty连接,客户端发出要测试的密钥,然后每个工人完成分布式计算。计算完热键后直接推送给客户端,非常轻量级。
worker端强悍的性能表现每10秒打印一行,totalDealCount代表处理的按键总数,可以看出每10秒的处理能力在270万到310万之间,对应每秒30万QPS左右。
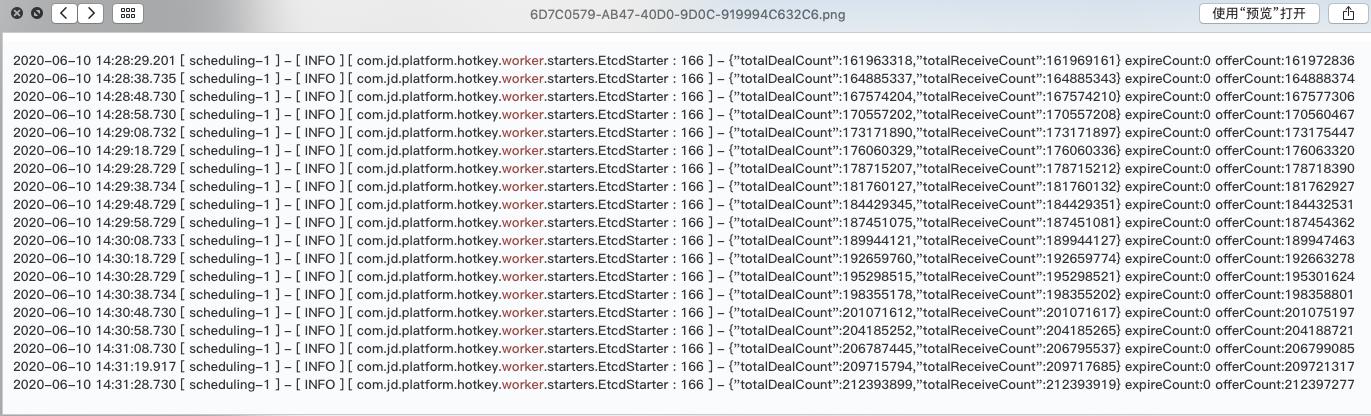
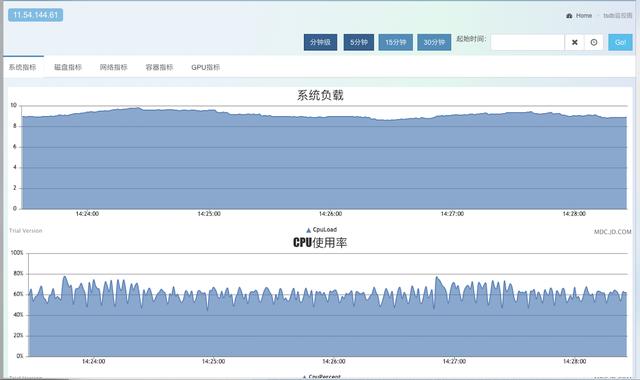
protobuf序列化后性能进一步提升。第二级36万以上时,可以稳定在CPU的60%,压力测试持续5小时以上,没有任何异常。30万小时,压力测试持续多日,未发现异常。

安装etcd
1.在etcd下载页面下载相应操作系统的etcd。https://github.com/etcd-io/etcd/releases使用3.4.x或更高版本。
2.启动worker(集群)下载编译代码,将worker打包成jar,启动。比如:
Java-jar $ Java _ opts worker-0 . 0 . 1-snapshot . jar-etcd . server = $ { etcd server } worker可配置项如下:

EtcdServer是etcd集群的地址,用逗号分隔。
JAVA_OPTS与配置的JVM有关,可以根据实际情况进行配置。
ThreadCount是处理密钥的线程数,在未指定时由程序计算。
WorkerPath表示工作者为哪个应用程序提供计算服务。例如,不同的应用程序appName需要由不同的工作人员进行隔离,以避免资源竞争。
3.启动控制台
下载并编译dashboard项目,创建数据库,导入资源下的db.sql文件。在application.yml中配置数据库关联和etcdServer地址
启动dashboard项目,访问ip:8081,可以看到界面。
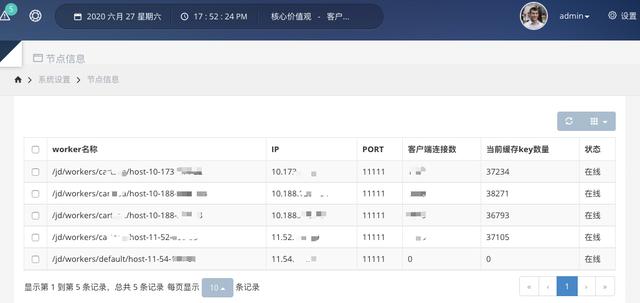
其中,节点信息是当前启动的工作者的列表。
规则是每个app设置规则的地方,第一次使用需要先添加app。在用户管理菜单中,添加一个新用户,并设置他的应用程序名称,如sample。之后新添加的用户可以登录dashboard为自己的APP设置规则,登录密码默认为123456。
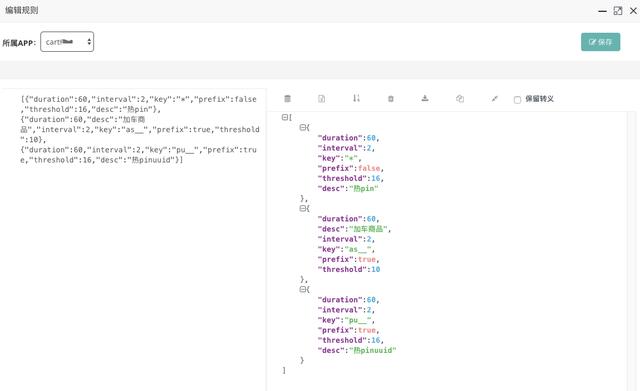
如图,是一套规则。例如,如果以as__开头的热键的规则是threshold-2秒内10次,它将被视为热键,并将它推送到jvm内存并缓存60秒。prefix-true表示前缀匹配。然后,在应用程序中,您可以使用一组以as__ _开头的键来检测。
4 .客户端访问和使用
介绍客户端的pom依赖。
初始化应用程序启动时的热键,例如
@ post construct public void init hotkey(){ client starter。构建器构建器=新客户端启动程序。builder(); client starter starter = builder . set appname(& # 34;appName & # 34).setEtcdServer(& # 34;http://1.8.8.4:2379,http://1.1.4.4:2379,http://1 . 1 . 1 . 1:2379 & # 34;).build(); starter . start pipeline(); }也可以通过setCaffeineSize(int size)设置本地缓存的最大数量,默认为50,000,setPushPeriod(Long period)默认为500ms。值越小,热键报告越频繁,响应越及时。建议根据实际情况进行调整。比如单机每秒有10个qps10,只需要每0.5秒上报一次,否则。最小值为1,即每1 ms报告一次。
注:

如果原项目使用的是番石榴,需要升级到以下版本,否则过低版本的番石榴可能会出现jar包冲突。或者删除自己项目中番石榴的maven依赖,番石榴升级不会影响任何原有逻辑。
& lt依赖性& gt & lt;groupId & gtcom . Google . guava & lt;/groupId & gt; & lt;artifactId & gt番石榴& lt/artifact id & gt; & lt;版本& gt28.2-JRE & lt;/version & gt; & lt;范围& gt编译& lt/scope & gt; & lt;/dependency & gt;有时候项目中可能没有直接依赖番石榴,但是引进的pom引用了番石榴,也需要排除。
使用有以下四种主要方法可用
Boolean jdhotkeystore . is hotkey(String key) Object jdhotkeystore . get(String key) void jdhotkeystore . smartset(String key,Object) Object jdhotkeystore . getvalue(String key)1 Boolean is hotkey(String key),该方法将返回该键是否为热键,如果为真,如果不为假,则将该键上报给探针簇进行数量计算。这种方法通常用于判断只需要判断键是否热,而不需要缓存值的场景,比如刷用户,界面访问频率等等。
2 Object get(String key),这个方法返回这个键的本地缓存的值,可以用来确定它是一个热键,然后得到本地缓存的值,这个值通常用在redis热键缓存中。
3 void smartset(字符串键,对象值),该方法为热键赋值。如果是热键,这个方法会赋值,但不是热键,什么都不做。
4 Object getValue(String key),这是一个集成方法,相当于isHotKey和get方法的集成,这个方法直接返回本地缓存的值。如果是热键,有两种情况,1是返回值,2是返回null。返回Null,因为它还没有设置真正的值。非null表示已经调用了set方法,并且本地缓存值有值。如果不是热键,则返回null,并将该键报告给检测簇进行数量检测。
更多:https://gitee.com/JD-platform-open来源/热键