机器之心专栏
作者:张颖,王晓睿,王中原
在电影配音、角色模仿、人物音色再现等领域,声音转换的应用非常重要。近年来,基于深度学习的语音转换取得了很大的进展,但是小数据的语音转换仍然是一个热点问题。Aauto的R&D人员更快地提出了基于说话人感知模块(SAM)的单样本语音转换解决方案。说话人作为目标说话人的语音转换只需要从说话人的单句语音样本中提取用户的语音表示即可实现。
语音转换(VC)是指在保持一句话内容不变的基础上,将说话人的语气从原来的语音转换成目标说话人的语气。声音转换在电影配音、角色模仿和角色音色再现中有着重要的应用。
目前,基于深度学习的特定目标说话人的语音转换已经取得了很大进展。例如,基于CycleGAN、VAE和ASR的语音转换方法可以很好地实现对训练集中说话人的语音转换。
但是如果要添加目标说话人的音色,或者自定义用户的音色,通常需要大量的说话人数据来重新训练一个以说话人的音色为目标音色的语音转换模型,或者用少量的数据对现有模型进行自适应训练。实际操作中,数据库录音的周期和成本都比较高,普通用户很难获得大量的语音数据。因此,小数据的语音转换已经成为一个亟待解决的热点问题。
来自MMU——Aauto quickiter音频技术R&D部的R&D人员提出了一种基于说话人感知模块(SAM)的单样本语音转换解决方案。在该方案中,只需从说话人的单句语音样本中提取用户的语音表示,就可以实现说话人作为目标说话人的语音转换。目前该成果已被ICASSP 2021验收,发明专利申请已在国内提交。
地址:https://ieeexplore.ieee.org/document/9414081
基于说话人感知模块的单样本语音转换
要完成单个样本的语音转换,有两个关键点:一是完成语音中内容特征的提取;其次,利用目标说话人的单个样本对目标说话人的特征向量进行解耦,然后将目标说话人的特征向量与提取的语音内容特征进行耦合,完成向目标音色的语音转换。
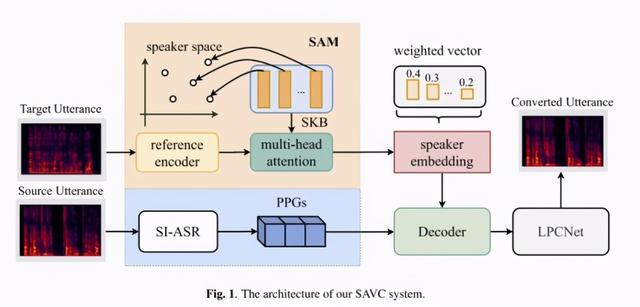
说话人感知语音转换(SAVC)系统,包括:
使用预训练的非特定人语音识别模型(SI-ASR)从语音中提取非特定人声学后验概率(PPGs)。声学后验概率可以表示每一帧语音的内容信息。
说话人感知模块用于将说话人特征向量从语音中分离出来;为了避免语音中的内容信息对说话人特征向量提取的干扰,辅助模型可以更好地解耦说话人信息。SAM和SI-ASR的输入特征来自同一说话人的不同声音。
解码器,耦合声学后验概率和说话者向量,并预测与特定说话者相关的声学特性。
声码器使用LPCNet作为后端声码器,将解码器预测的声学特征重建为语音信号。
SAM的设计灵感来源于声纹识别的成果和注意力机制的应用,包括以下三个模块。
参考编码器
对变长目标说话人的语音特征进行编码,由于原说话人的语音和目标说话人的语音通常长度不等,而且理论上说话人矢量不随语音内容而变化,所以用帧级特征矢量来表示目标说话人的参考编码显然是不合适的。将其压缩成固定长度的参考编码向量,不仅可以使其对时域信号变化不敏感,而且便于与从原始语音中提取的ppg进行进一步的特征耦合。
假设输入是x = [x _ 1,x _ 2,...,x _ t],t是输入的长度,所以目标说话人编码矢量可以表示为R=RefEncoder(X),其中R∈,d_r是定长目标说话人编码矢量的维数。
演讲者的先验知识模块(SKB)
在声纹识别任务中,通常使用x向量、I向量等特征来表示不同的说话人向量。这些向量分布在同一个超曲面空中,既能表示不同说话人的差异,又能包含不同说话人之间的相关性。通过预训练的声纹模型提取说话人矢量x-vector,将多个说话人的矢量组合成SKB。SKB的数据分布可以看作是说话人表示空区间,更多的说话人向量可以更详细地表示说话人空之间的信息。
假设说话人的向量特征维数为1×d_x,选择n个说话人作为说话人先验知识模块的基本说话人,在训练集中选择说话人时考虑性别平衡(男女各半)。那么SKB可以表示为S=[S_1,S_2,…,S_N],其中S∈。本文使用的说话人矢量x-vector为200维,选取200个基本说话人。
多关注层
它被用于对全局说话人矢量建模,并找到参考说话人矢量和SKB之间的距离相似性。SKB中的特定说话人矢量可以被视为说话人表示空之间的坐标点。因此,可以通过对先前说话人矢量空中的所有基本说话人进行加权和量化来表示新的说话人矢量。

关注层的输出可以表示为:
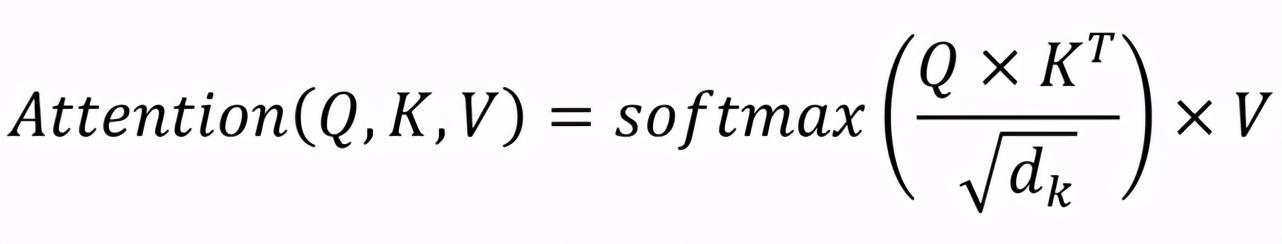
其中,Q、K、V为关注度查询和键值,d_k用于表示键的维度。
多头关注层的计算可以表示为:
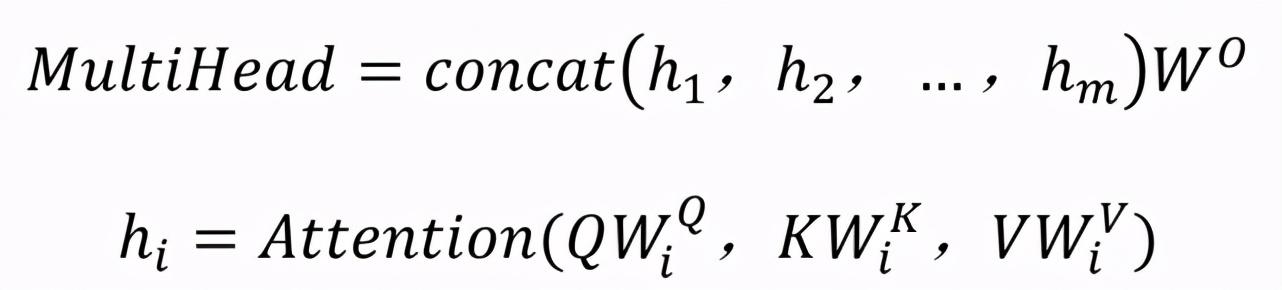
本文选取了四个注意层,W _ I Q,W _ I K,W _ I V,W O为参数矩阵。
最终的目标说话人矢量表示为:
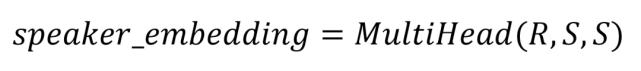
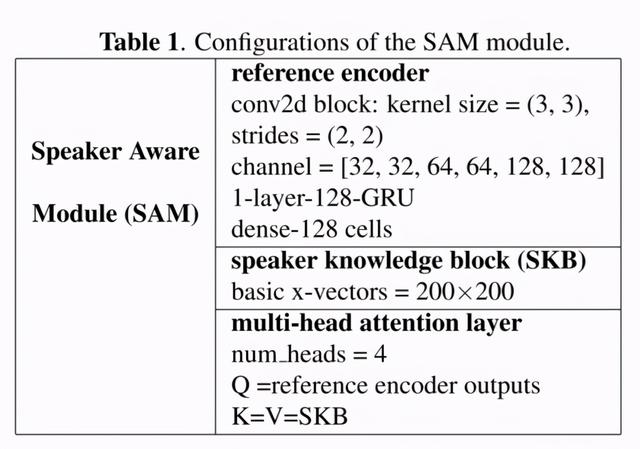
SAM模块网络参数如下表所示:
实验对比
本文对目前几种基于单样本的最优语音转换网络进行了比较。本文提出的基线模型和SAVC模型都使用Aishell-1训练集中的340个中文数据作为训练数据集。选择Aishell-1测试集之外的说话人作为测试中使用的原说话人和目标说话人。
实验结果如下。可以看出,在单样本语音转换任务中,该方法的主客观测试指标均优于SOTA。
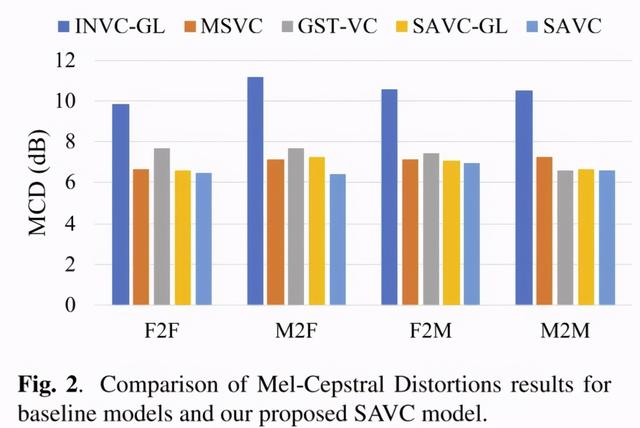
本文提出的SAVC模型和基线模型的Mel光谱失真(MCD)结果如图2所示。结果表明,SAVC-GL模型的Mel谱失真比INVC-GL模型的低得多。此外,SAVC模型的Mel谱失真结果优于SAVC-GL模型,这表明后端声码器的改进可以进一步提高性能。与MSVC模型和GST-VC模型的失真结果相比,SAVC模型表现更好,SAVC模型的结果与跨性别语音转换的结果没有明显差异。这些都证明了SAVC-GL模型的有效性。
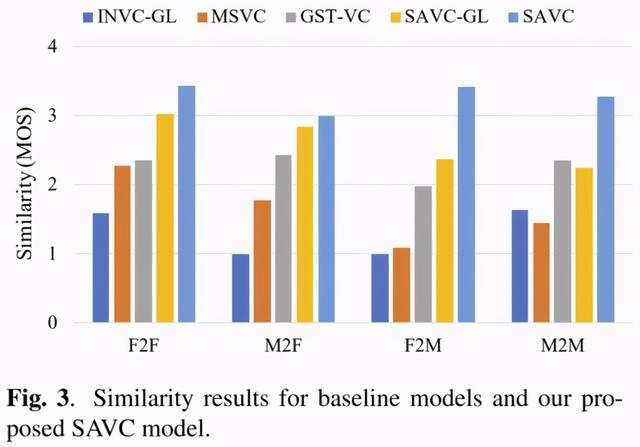
图3中的结果显示,与基线模型相比,SAVC模型在所有转换对中获得了最佳的相似性得分。值得注意的是,GST-VC的男女转换分数低于其他转换对。这可能是因为Aishell-1的训练集中女性数据较多,性别失衡导致GST-VC对不同目标说话人的表征能力存在差异。由于GST-VC中表示说话人信息的模块完全基于无监督训练,无法人工干预这种现象。但在SAVC模型中没有观察到这个问题,因为作者在设计SKB时考虑了性别平衡,有效减少了训练集中数据不平衡带来的干扰。结果符合作者对SAVC设计的期望。
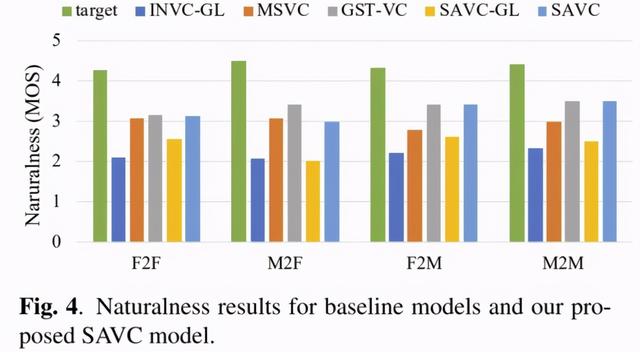
基线模型和SAVC模型的自然度平均意见得分如图4所示。Griffin Lim算法重建的语音评分比LPCNet重建的语音评分差很多。这是因为Aishell-1语料库是语音识别数据集,是手机录制的。音频中有很多噪声,比如混响、信道噪声等。,这些都不利于Griffin Lim算法从频谱参数中预测相位,导致合成语音质量较差。而LPCNet声码器在训练时随机在数据中加入噪声,增强了数据的多样性,因此对含噪信号的鲁棒性更强。虽然后端的声码器都是LPCNet,但是MSVC模型的主观意见得分低于GST-VC模型和SAM-VC模型。因为在说话人编码器中建模的说话人空完全独立于MSVC模型,所以MSVC模型只对训练过程中遇到的说话人向量建模。在预测阶段,对于训练好的MSVC模型,新的目标说话人矢量是完全未知的信息,因此可能存在声学后验概率与新的说话人矢量不匹配的情况,导致语音质量下降。GST-VC模型和SAVC模型的自然度主观意见分非常接近,这很好理解,因为这两个模型使用的说话人矢量都是语音转换模型预测的,而且都是使用LPCNet来重构波形。
下面的视频展示了基于单样本语音转换的SAVC模型和基线模型的效果,输入语音和目标说话人的语音都来自集合外的说话人。视频展示了男声变女声,女声依次变男声的效果。更多演示,请参考作者展示的链接。(https://vcdemo-1.github.io/SAVC/savc.html)
应用
变声技术在Aauto faster中有着丰富的应用场景,如短视频剪辑、现场变声、用户音色个性化定制等。而通过单样本语音转换复制音色,不仅可以大大降低对训练数据库的要求,还可以显著节省计算资源。基于单样本的语音转换是Aauto faster在语音交互领域的重大技术突破,有望引领语音转换应用新趋势。
在Aauto中更快地引入MMU
Aauto Quicker的MMU(多媒体理解)部门负责Aauto Quicker中海量音频、视频、直播的内容理解,为公司提供500+智能服务,应用于搜索、推荐、生态分析、风险控制等多个场景。团队拥有业内顶尖的算法工程师和应用工程师,不断招聘相关领域的技术人才。