最近几天看了一下关系抽取方面的论文,但是整理的感受是文章是两极分化,一极是“创新点起的高”,逼格有点大,说的有点模糊,以至于觉得很厉害;二极是创新点真的是没有,但是自圆其说的能力真的是香,这点确实值得我们这样的小白菜学习,发出优质论文,毕竟很少有人能把自己的创新点称之为Innovation。好了,我们来说一下关系抽取的相关问题吧,关系抽取是基于实体识别的,所以实体识别比关系抽取的难度低了一个档次,关系问题解决,我们构建那个啥玩意-----知识图谱。所以,我想说的是,关系抽取是属于底层任务,所以作为一个帅气美丽资深的NLP研究者,我们应该掌握。我先说一下关系抽取分为两个类别:pipeline和joint model,具体的名词解释和基础知识背景大家自行查阅,下面我们开始相关论文介绍啦!!!
(1). pipeline
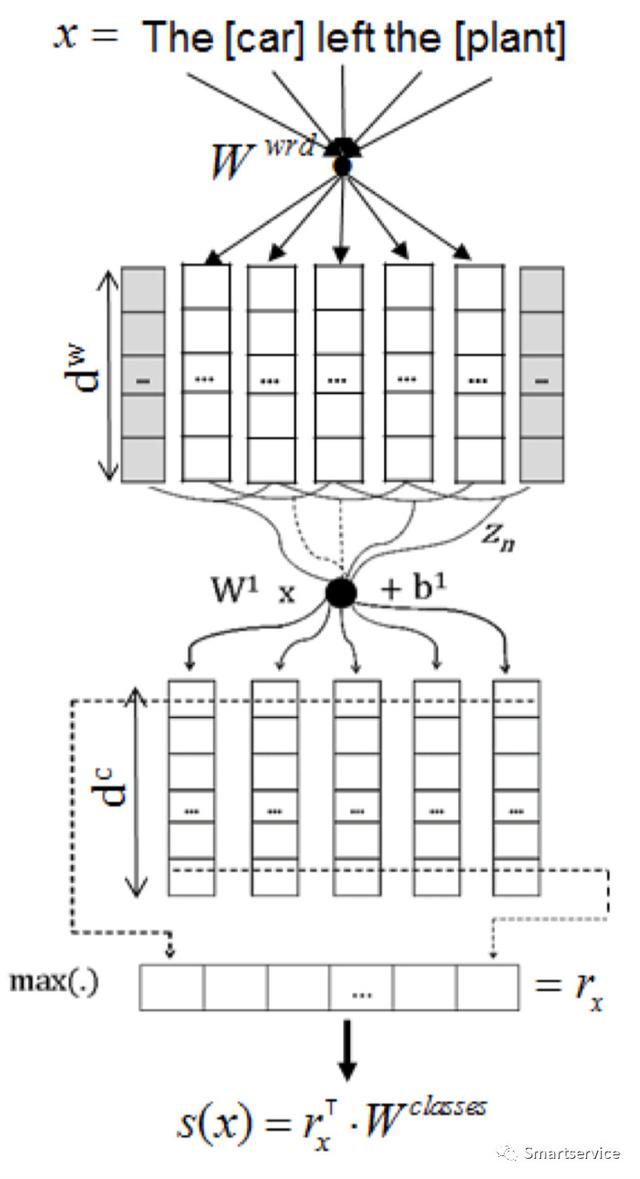
2015年提出的基于CNN的关系分类,这里是将实体抽取和关系分类进行串行处理,也被我们称之为pipeline,即关系是被的效果是依赖于实体识别的效果的。这里面用到了词嵌入和位置嵌入,词嵌入还是用的我们常规的方法,位置嵌入用的是当前词和目标关系实体名词的位置关系,w1和w2,我们会得到两个位置关系,我们通过嵌入方式,讲得到的两个vector进行拼接,形成一个位置向量。这篇文章最后是将位置向量和词嵌入向量在进行拼接的。卷积神经网络在这里的作用是,首先对拼接成的向量进行卷积操作,然后对卷积后的特征向量进行max pooling操作。这篇文章的地址:https://arxiv.org/pdf/1504.06580.pdf。
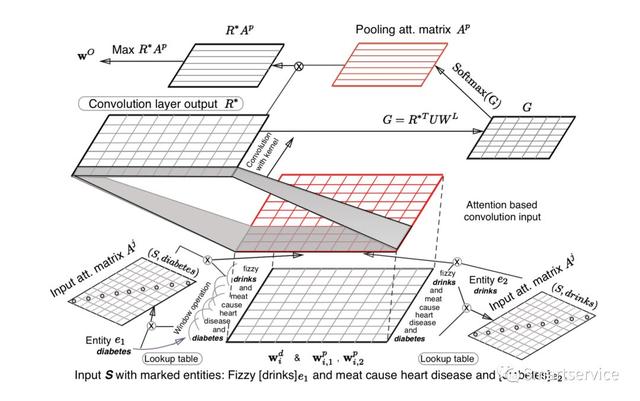
2016年ACL提出了多级的attention的CNN来做关系抽取。第一级attention的作用是计算与目标实体之间的权重,第二级attention是基于池化层的。输入的处理,输入和之前我们在2015年中的文章一样,位置嵌入和词嵌入vector进行拼接,形成一个新的向量。第一级attention的计算当方法文中已经给出,我们一般用一个前馈网络进行学习。第二个attention是利用卷积操作提取到的特征矩阵和目标关系嵌入矩阵作注意力机制计算操作,计算结果再和特征矩阵相乘,最后maxpooling得到目标的一个关系向量。这篇文章的下载地址:http://people.iiis.tsinghua.edu.cn/~weblt/papers/relation-classification.pdf。
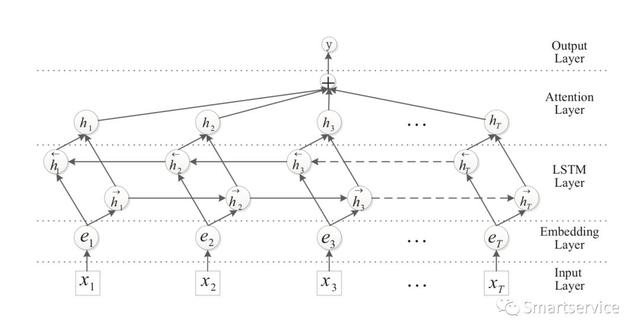
2016年的ACL还有一篇论文,是《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification 》,这篇论文讲的是利用基于attention机制的双向LSTM作关系提取的。句子中的词编码方式还是传统的词嵌入形式,通过双向的LSTM提取到时序特征序列加权求和,然后送入到全联接层再分类。文章个人觉得没有丝毫的创新点,当然了,我们也给出这篇文章的下载地址:https://www.aclweb.org/anthology/P16-2034.pdf。
(2). joint model
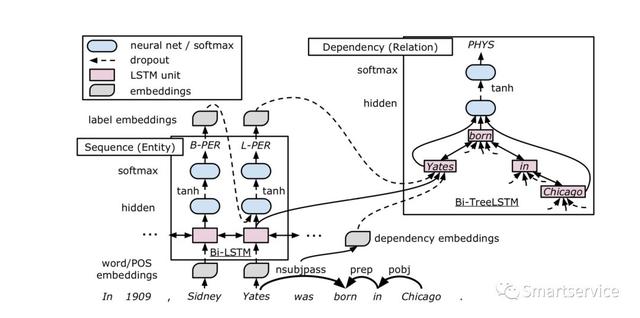
2016年的ACL论文,《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures 》。这篇文章的特色在于联合抽取,模型分为三个部分,词嵌入层(这里面用到了词性pos),基于双向LSTM的句子序列编码,以及使用基于LSTM的依赖树。模型的工作原理,第一步当然是数据预处理部分,用的是词嵌入和词性向量的拼接;接着是对输入的序列进行特征提取,使用的是双向的LSTM,这部分已经是老生常谈了;接着是实体检测,实体检测这里也是比较简单的,将每个特征向量输入到前馈网络中,但是需要注意的是:这里是从左向右的输入到网络中的,这里可以理解用了一个RNN网络,然后将结果送入到softmax层产生标记结果;关系抽取的过程相对复杂点,其中用来了依存句法标签、实体标签和上一步骤提取的序列特征,关系分类主要还是利用了依存树中两个实体之间的最短路径(shortest path)。主要过程是找到sequence layer 识别出的所有实体,对每个实体的最后一个单词进行排列组合,再经过dependency layer 得到每个组合的向量,然后同样用两层NN + softmax 对该组合进行分类,输出这对实体的关系类别。难点在于,大家可能没看懂的地方:这里构建了一棵句法依存树,然后根据实体对来找共同的祖先,然后自顶向下和自底向上使用双向LSTM来提取特征。这篇文章在关系抽取部分容易让人懵逼,也给出这篇文章的下载地址:https://arxiv.org/pdf/1601.00770.pdf。

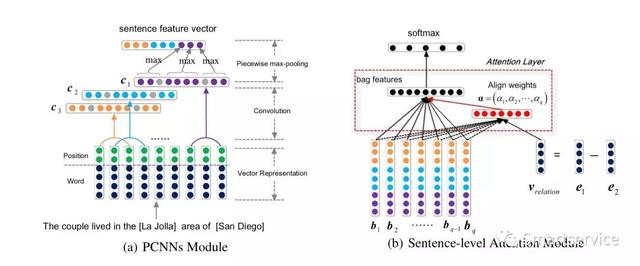
2017年的AAAI论文,我们来点高端会议论文《Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions 》,看看装逼风格是否会转换。这篇文章的开头就给我们搞了一个远程监督学习,估计被说的一头雾水。这篇文章提出的方法主要是两部分组成:PCNN model和句子级别的attention,PCNN包括Vector Representation, Convolution and Piecewise Max-pooling, 句子级别的attention包括:Attention Layer and Softmax Classifier 。首先我们介绍第一部分:句子的输入还是词嵌入和位置向量,我已经不想再多提,然后进行的就是一维卷积,通过多个卷积核得到多个特征向量,在做池化操作的时候,我们使用的是分布max-pooling,其实对于看了这么久眼力疲劳的人已觉得没有新鲜感。第二部分是将同一个袋中的句子通过PCNN获取一个vector用作后面的关系分类,这里的attention是将所有的vector和预先根据三元组计算得到的关系向量进行运算的结果,并将最终得到的关系向量输入到softmax中得到最终结果。但是注意的是,这个文章有一个需要你care的地方就是“袋子”思想,就是相同的关系在一个袋子中他们所占的权重会。这篇文章是挂着羊头卖着狗肉,和联合抽取没有多大关系,但是要注意它的创新地方,也给出这篇文章的下载地址:https://pdfs.semanticscholar.org/b8da/823ad81e3b8e5b80d82f86129fdb1d9132e7.pdf_ga=2.165746039.873069772.1570763379-663222830.1543144917。







