一、Databricks 数据洞察产品介绍1.Databricks公司介绍
2。什么是阿里云Databricks数据洞察产品?
01 data bricks公司介绍

①创始公司ApacheSpark也是Spark最大的代码贡献者,Spark技术生态背后的商业公司。
2013年由加州大学伯克利分校AMPLab创始团队ApacheSpark创始人创立。
②核心产品和技术,引领和推动Spark开源生态。
ApacheSpark、DeltaLake、考拉、MLFlow、OneLakehousePlatform
③公司定位
Databricksis是数据+AI公司,为客户提供数据分析、数据工程、数据科学和人工智能方面的服务,并集成了Lakehouse架构。开源VS商业版:公司大部分技术研发资源投入商业产品。多云策略,与顶级云服务商合作,提供数据开发、数据分析、机器学习等产品,以及数据+AI综合分析平台。④市场地位
科技独角兽,行业标杆,引领星火整体科技生态的潮流和风向标。2021年最值得期待的科技上市公司02 Databricks公司估值和融资历史
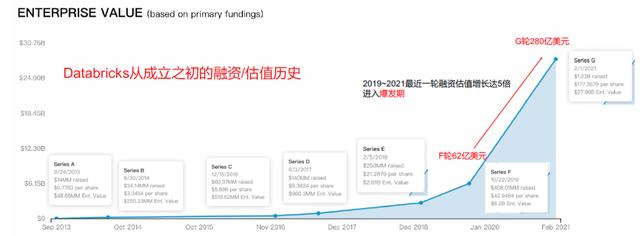
(来源Databricks官网)
①2019年10月G轮,估值62亿美元。
②2021年2月初F轮,估值280亿美元。
在此轮融资中,三大云服务商AWS、GCP、MSAzure和Salesforce都进行了后续投资——足以看出云厂商对Databricks发展的重视。预期上市:计划IPO将在2021年——多方预测,当Databricks上市时,其估值可能达到350亿美元,甚至高达500亿美元。
03 data bricks与阿里云联合打造的高质量星火大数据分析平台

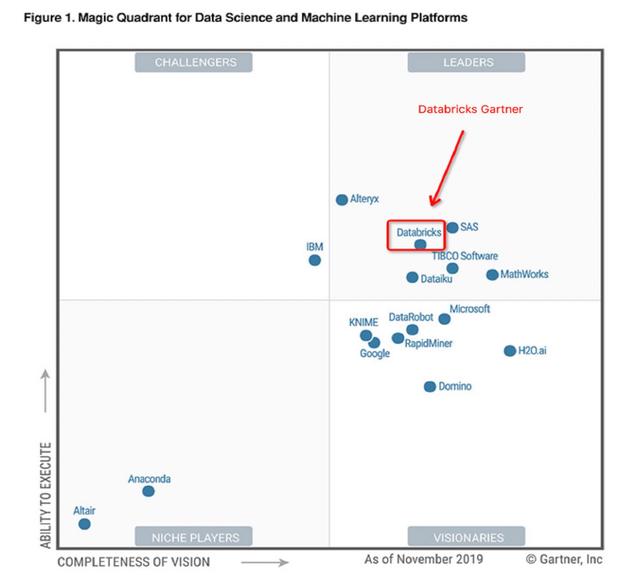
Apache Spark背后的商业公司,Spark创始团队,美国科技独角兽。在全球拥有5000多家客户和450多家合作伙伴,拥有强大的品牌知名度。2020年,在Gartner发布的数据科学与机器学习(DSML)平台魔力象限报告中,位于领导者象限。

04 Data bricks+阿里云= Databricks Data Insight

核心产品:
基于商用Spark & AI平台的全托管大数据分析内置商业版Spark engine Databricks运行时,在计算层面提供高效稳定的保障。与阿里云产品集成互操作,提供数据安全、动态扩展、监控报警等企业级特性。产品和服务:
100%兼容开源Spark,由阿里云和Databricks优化。提供商业SLA保证和7*24小时数据块专家支持服务。
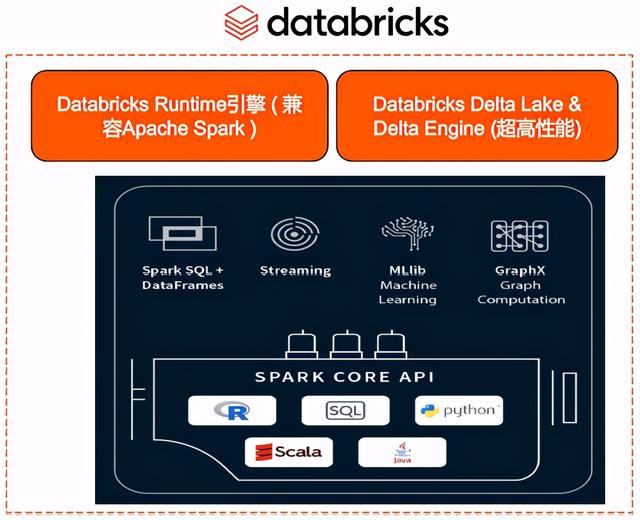
DDI产品功能的核心组件
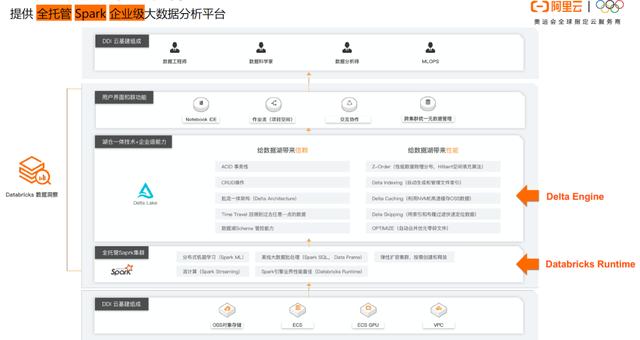
产品的关键信息和优势
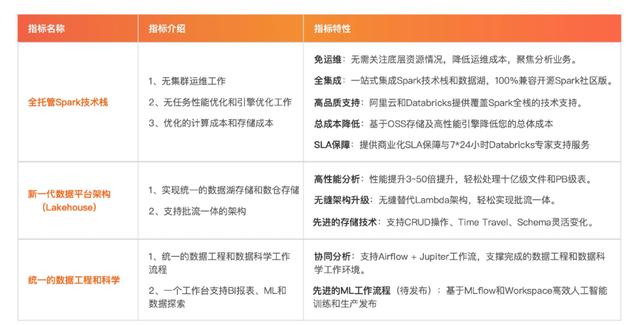
二、DDI 产品功能介绍1.整体架构
2。发动机性能
3。性能。功能。成本。
01阿里云数据块数据洞察(DDI)架构
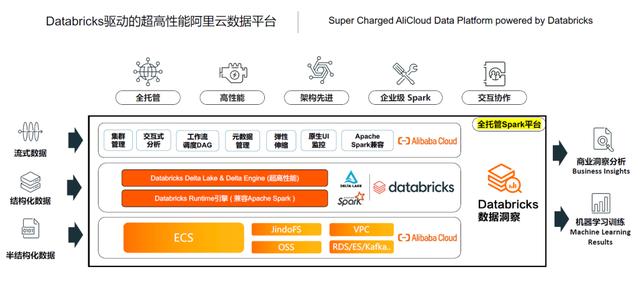
02引擎:企业级性能优化,提高计算引擎效率和数据读写效率
企业级高性能、稳定性和可靠性
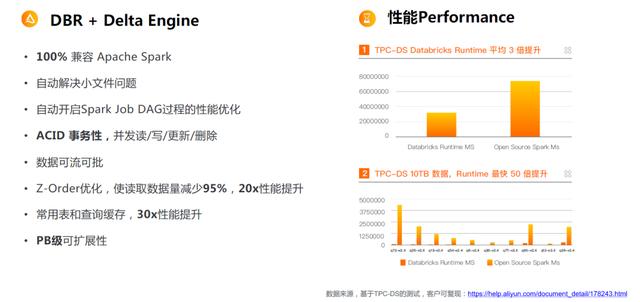

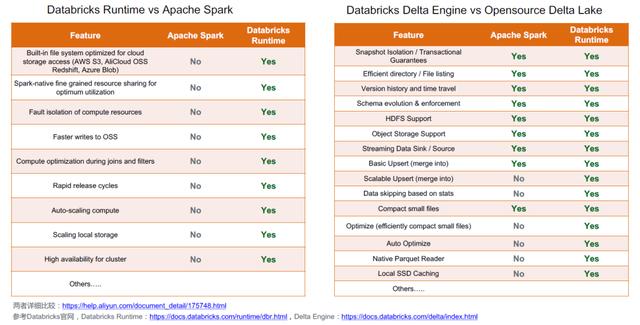
03企业数据块运行时vs社区开源Spark
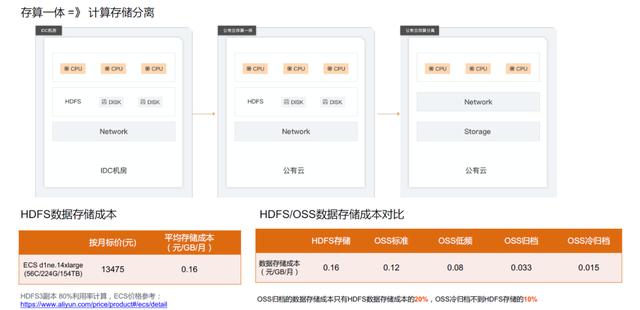
04基于计算存储分离架构的HDFS与OSS成本比较
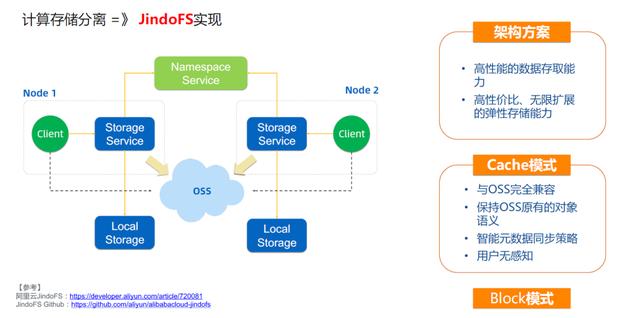
05基于JindoFS的OSS访问优化加速,优化数据访问性能
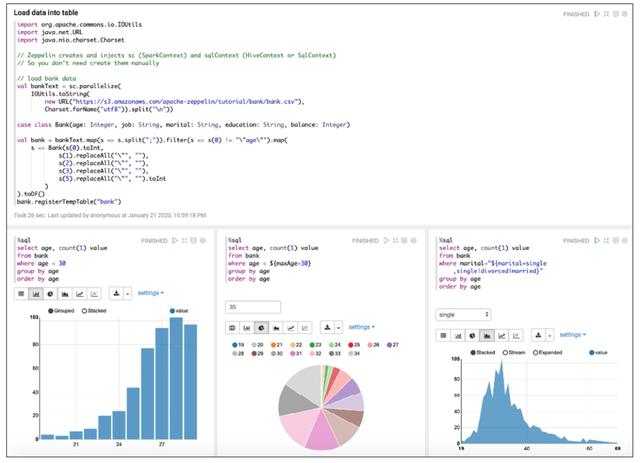
06笔记本互动分析,数据汇总
优化的阿帕奇齐柏林飞艇
多语言支持Scala、Python、Spark SQL、R交互作用分析数据可视化综合调度能力一站式开发平台多用户协作开发
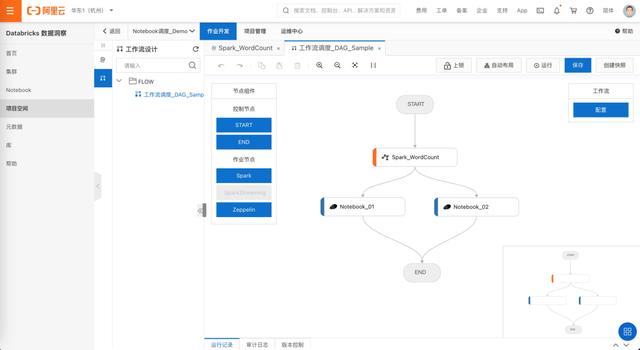
07数据开发作业提交和工作流调度
支持jar包提交作业和作业调度能力支持火花/火花流/笔记本不同作业类型的工作流混合调度支持调度运维、审计日志、版本控制等。
08丰富的数据源支持

09元数据管理
元数据选择的三种方式

三、典型场景1.客户的痛点以及如何解决DDI
2。Lambda架构到批处理流集成架构
3。湖边小屋建筑的演变。阿里云的DDI产品组合。
01开源大数据平台客户的常见痛点

02 Databricks data insight帮助客户在四种情况下提高生产效率
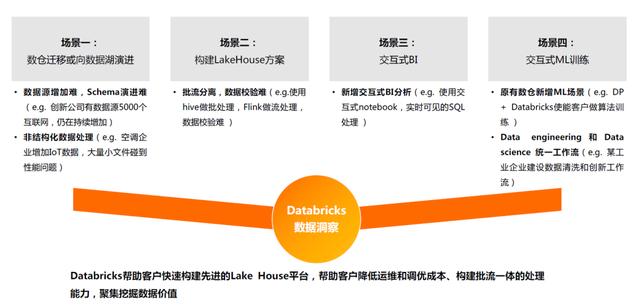
03三角洲湖项目背景及待解决问题
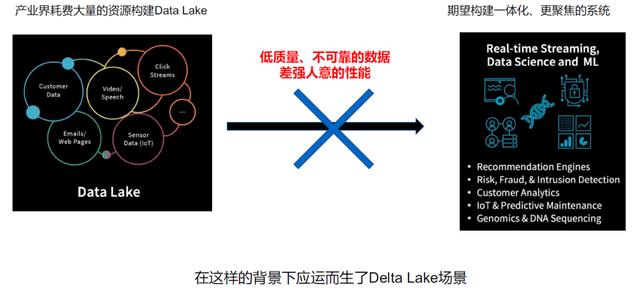
04大数据发展进入湖居时代
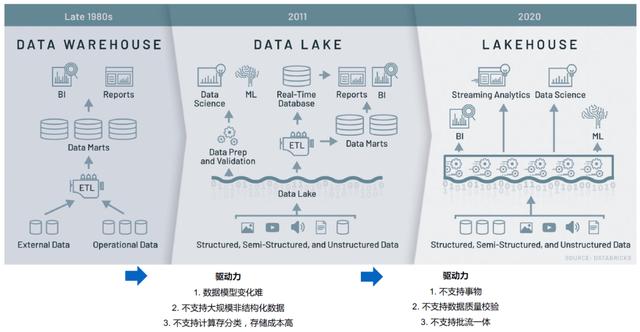
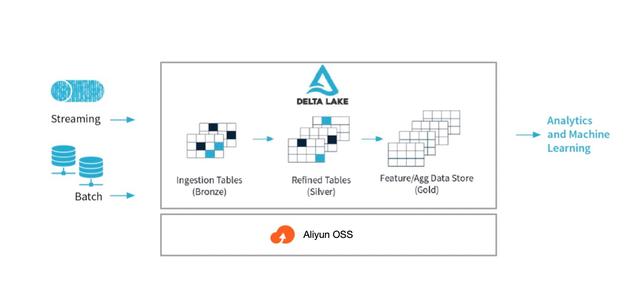
05使用DDI构建批量流集成仓库,简化复杂架构
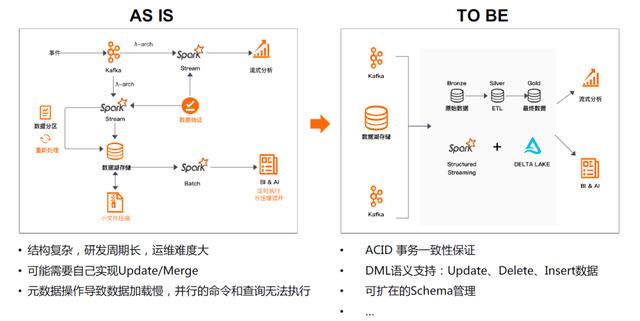
06 DDI在阿里云产品中的组合
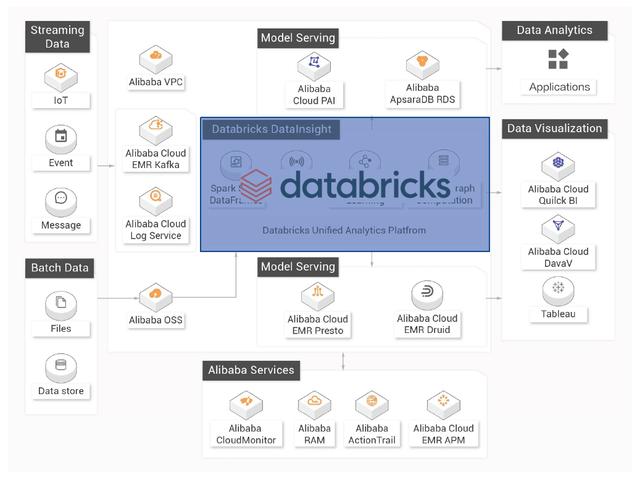
07数据砖块的典型架构数据洞察
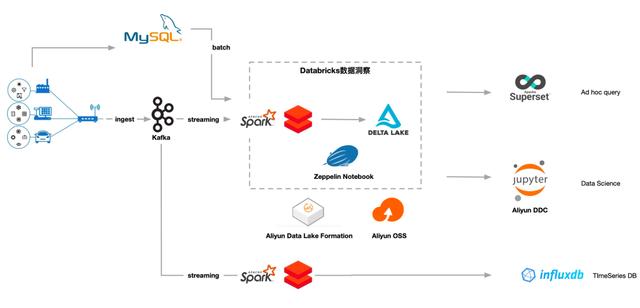
DDI和阿里云产品的深度整合(典型场景)
数据采购
接收实时生成的流数据和外部云存储中的批量数据。数据ETL
持续高效处理增量数据,支持数据回滚和删除,提供ACID事务保障。BI报告数据分析和交互分析
支持即席查询、笔记本可视化分析,无缝对接各种BI分析工具。人工智能数据探索
支持机器学习、Mllib等星火生态AI场景。上游和下游网络是相连的。
如上游对接卡夫卡、OSS、EMR HDFS等。,下游承担弹性搜索、RDS、OSS存储等。四、典型场景客户案例介绍1.STEPONE自建云的案例
2。工业制造总公司数据分析案例。
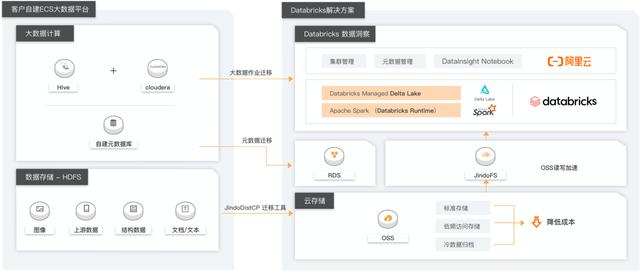
客户案例01:云迁移第一步]第一步的数据块
该架构描述了如何通过使用Databricks数据洞察解决客户的大数据计算问题:
数据存储:自建蜂巢数据仓库——“OSS”(降低存储成本,同时将计算和存储分开)大数据分析:自建CDH -》Databricks data insight(全托管Spark、高性能运行时引擎、笔记本交互分析、工作流DAG调度、Python库轻松安装等。)元数据:自建CDH -》RDS MySQL自建元数据库或使用DDI统一元数据库。数据迁移:使用DistCp或JindoDistCp将数据迁移到OSS,数据结果同步继续使用Sqoop调度任务。
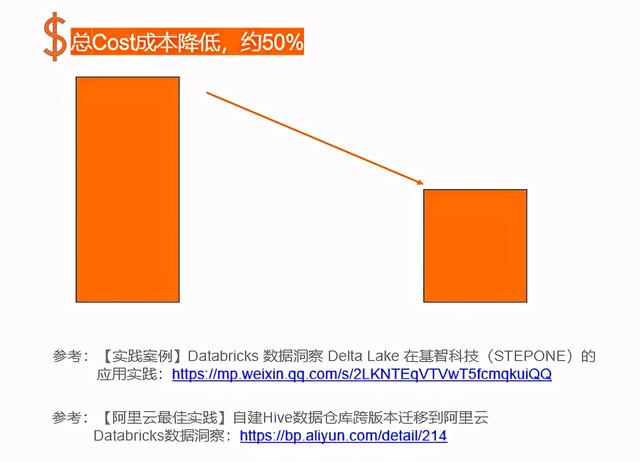
客户成本效益分析
完全托管的Spark集群免运维,节省人力成本(节省1个运维+1个大数据,避免性能调优)比自建机器资源多3倍。除此之外,Databricks运行时的整体性能比开源的spark高9倍(估计是3倍)。笔记本交互式分析+DAG工作流调度,以改善数据开发/分析体验技术方案统一,计算存储分离方案OSS存储节省了客户的存储成本,为未来的数据湖和多计算架构做铺垫。三角洲湖解决了客户增量数据更新的问题。
客户案例02:工业制造负责人空转让公司——大数据分析方案架构
数据采集/存储:接收实时生成的流数据和外部云存储中的批量数据。数据ETL:持续高效处理增量数据,支持数据回滚和删除,提供ACID事务保障。BI数据分析&交互分析:支持查询、笔记本可视化分析,无缝连接各种BI分析工具。数据科学:支持机器学习/深度学习对接状态:如上游对接Kafka、OSS、EMR HDFS等,以及下游对接Elasticsearch、RDS、OSS存储等。
讲师:布朗泽,阿里云技术专家,计算平台事业部开放平台-生态企业团队负责人。
本文为阿里云原创内容,未经允许不得转载。








