2015年5月,杭州萧山区光缆被切断,某公司支付软件受到影响。用户反复登录,但无法使用。一时间#XXX爆炸#成为微博热词。2021年7月,某视频网站半夜宕机,各种产品的所有功能似乎完全崩溃,直到第二天早上服务才恢复。这两个故事引起了吃瓜群众对企业技术实力的质疑和误解,影响深远...
1.2 关于我讲完两个故事,我来说说我自己,原Tik Tok电商C端营销&推广方向POC,阿里巴巴2020年货节&后年货节推广组技术执行PM,六年广告、电商领域后端开发经验,大数据量、高并发、巨额资金场景下的技术测试。
1.3 关于选题从这两个故事中,我们可以看到,如果我们没有充分考虑失败的情况,对一个公司的声誉有多坏。从程序员个人的角度来看,面向失败的设计对个人有着同样大的影响。企业事故的责任最终会落到程序员个人身上,事故往往会消耗组织对个人的信任,直接或间接影响个人的发展。在字节跳动,事故对个人的影响不算太大,但在其他公司,一次事故往往意味着程序员一年的工作都白做了。
不同年代的程序员有什么不同?据我所知,面向失败的设计能力也是除了架构设计能力、项目管理能力、技术规划能力、技术领导力之外极其重要的一部分。
业务开发的新生,有时候可能会很着迷,很自信,觉得自己写的代码和老鸟没什么区别。其实写正常流程的业务代码的人之间并没有太大的区别,但是对异常、边界、不确定性的处理才真正体现了一个程序员的功力。老鸟在长期的训练下往往已经形成了各种各样的肌肉记忆。遇到具体问题时,他们会举一反三,脑海中会蹦出很多失败导向的设计点,从而写出高可用的业务代码。如何学习失败导向设计的方法论,逐渐形成自己独特的肌肉记忆,才是新手成为老鸟的康庄大道。
基于这样的考虑,我写了这篇文章,总结了我这些年的一些经验和教训,希望能吸引更多的老鸟来分享经验,互相学习,共同进步。
二、道在道的层面,我想谈谈失败设计的世界观。
2.1 失败无处不在理想状态下,机器硬件永远不会老化,系统软件永远不会过期,流量永远在预期范围内,自己写的代码没有bug,产品经理永远不会更改需求。但是,现实总会给你一拳,给你一记来自社会的严厉敲打:硬件总会在某个时间点失灵,软件总会在某个时间点跟不上时代的潮流,流量总会在你意想不到的时候突然增加——哪怕是在婚礼上,没有不写bug的程序员,也没有不写产品经理。

无论是在传统软件时代,还是在互联网和云时代,系统最终都会在某个时间点失效。面向失败的设计不是为了消除失败,而是为了减少甚至消除失败的影响,保住企业和个人的钱袋子。
2.2 唯一不变的是变化不仅失败无处不在,改变也无处不在。
2.2.1 不要写死——你的 PM 为改需求而生“不要写死|你的PM是为改变需求而生的”,这句话是我的同行舒菲的亲笔签名,深得我心。永远不放心把代码写死。根据墨菲定律,越是你认为不会改变的领域或函数,它们就越会改变。所以多一些配置,少一些死写,可以在产品改变需求的时候快速反应,让别人印象深刻,也可以在出问题的时候有更多的手段快速恢复。
2.2.2 隔离可变性——程序员应软件变化而生如果系统软件永远不变,我们还需要设计模式吗?还需要面向对象吗?面对过程不是又快又好吗?但是,一个程序员对于一成不变的系统软件有什么用呢?Tik Tok已经变得如此强大,它可以在不改变任何东西的情况下为字节赚很多钱。Tik Tok的程序员可以被解雇吗?好像不是。
设计模式是应对前人总结的变化的利器。23设计模式,一句话,说:隔离可变性。无论是创意模型、结构模型还是行为模型,设计的目的都是把变化关进设计模式的笼子里。
2.2.3 定期回归——功能在演化中变质定期回访也是应对失败的重要原则。互联网的迭代真的太快了。传统软件往往以年、月为单位迭代,而互联网往往以周甚至天为单位迭代。每一天,系统的功能都可能在进化中退化。快速迭代不仅让业务代码迅速腐败成一堆屎,也让内部逻辑日益臃肿,甚至相互冲突。总有一天,没有bug运行良好的代码会成为事故的导火索。
2.3 对代码的世界保持警惕警惕代码的世界,否则总有一天你会经历血与泪的教训。
2.3.1 不要相信合作方的“鬼话”对合作方给你的所有接口和方案都要持怀疑态度,不要相信合作方任何没有经过自己验证的结论。实践是检验真理的唯一标准,永远怀疑世界是工程师的核心品质。失败后和伴侣甩锅的时候不要后悔。前期多做验证,保护你和他,保护你们之间的塑料友谊。
2.3.2 不要相信代码注释一行错别字的代码评论把我从阿里带到了字节跳动,一次血泪的亲身经历。错误的代码注释总比没有注释好。不要用错误的评论给后人埋坑。救救孩子们。
2.3.3 不要相信函数输入NPE(nullpointerexception空指针异常)可能是程序员职业生涯中遇到的最常见的错误,也是比较混乱的,因为程序员从LeetCode的第一个问题就知道需要检查函数参数。
之所以会出现这样的结果,是因为在线制作环境所能遇到的场景远比一个代码问题复杂,这其实就是工业界和学术界的区别。学术界的问题是确定的,工业界的问题是不确定的。即使上游传递参数的系统是你认为极其可靠的系统,即使你翻遍了程序上下文,确定空参数不会出现,你也最好做一些防御性的设计,因为可靠的系统也会给你返回非标准的参数,当前没有空参数的代码,总有一天会被改得面目全非。
2.3.4 不要相信基础设施连支付宝都会崩溃,连六个9可用的系统全年都会中断31秒。不要轻信基础设施,做好备灾和混沌工程,让你每晚都能睡个好觉,避免被报警电话吵醒。
2.4 设计原则2.4.1 简洁的方案最优雅如果你设计的技术方案不是太华而不实,整体呈现出一种从大道至简约的美感,也许你就接近成功了。简洁的方案代表了更低的理解成本、更低的维护成本和更好的可扩展性。
如果你的计划充满了华而不实的招数,看起来复杂严谨,那么也许你离让自己头疼,让别人头疼就不远了。操作猛如虎,月薪2500。
当然,不是最简单的方案就是最合适的。比如核心交易环节的服务,必然会比数据展示要求更高的稳定性,所以在做出更高可用的设计后,方案会更复杂。因此,建议在满足稳定性的前提下,尽量选择简洁的方案。
2.4.2 开闭原则是设计模式的总纲开闭原则是设计模式的总纲。大多数设计模式都有开闭原则的影子。软件实体应该对扩展开放,对修改关闭。开放封闭原理可以通过“抽象约束和包变化”来实现。开闭原则可以使软件实体具有一定的适应性和灵活性,以及稳定性和连续性。
基于开闭原则,回答了许多常见的设计问题:
(1)大量if-else的屎山代码问题。大量的IF-else当然不符合开闭原则,IF-ELSEs的每一个代码分支都是对原有代码结构的破坏。这里,工厂+策略设计模式可以应用于剥离IF-ELSES,逻辑的添加和修改可以限制在工厂模式子类内部。
(2)冗长的业务流程处理问题。业务流程代码往往非常冗长。如果没有很好的封装,代码的阅读和维护是非常困难的。我们可以考虑使用命令+责任链设计模式来封装工作流。封装的好处是整个工作流程读起来会非常清晰,主要的流程代码往往可以从几百行减少到十行以内,流程的修改只是简单的断链或者增加链节点的操作,这样就把修改的影响降到了最低。
(3)历史字段类型的修订。在互联网开发过程中,经常需要修改历史字段的类型。根据开闭原则,我们应该增加一个新的字段,而不是修改原有字段的类型,以保证对上下游环节的影响最小。
(4)中间篡改对象属性的问题。以一个实际的业务场景为例。在一些业务请求中,Tik Tok速成版需要做与Tik Tok相同的处理。把Tik Tok速成版的APPID改成Tik Tok的APPID是最简单的方法,但是这种方法不符合开放封闭原则。改变中间对象的属性会改变程序中对象的语义。总有一天,它会达不到预期,导致许多事故。正确的做法是在上下文中传递一个新的字段,下游处理的每一步都能选择正确的字段做正确的处理,不会被中间篡改的字段蒙蔽。
2.4.3 懒惰是程序员最大的美德懒惰是程序员最大的美德。好的程序员往往默默无闻。越是程序员围着团队喊着救火,刷存在感,越有可能是团队的慢性毒药。
为了让自己变懒,做好业务,程序员必须掌握平台、工具和自动化。平台,把程序员从无休止的重复工作中解救出来;工具,把程序员从人类运输和紧急呼叫的可怕困境中拯救出来;自动化让程序像流水线一样顺畅,从而提高了程序员的人效。这三个轴能挥舞到什么水平,也反映了程序员的能力达到了什么水平。有了平台化、工具化、自动化,才能做到标准化、规模化,公司和业务才能继续往上走。
三、术在技术层面,我想从组织和流程的角度谈谈如何针对失败进行设计。
3.1 组织3.1.1 面向失败设计的工种测试工程师、测试开发工程师、风险控制&安全合规工程师都是开发工程师最值得信赖的合作伙伴,也是企业为面向失败的设计而设立的岗位类型。
测试工程师是软件质量的把关人。他们是在线质量的守护者,负责开发工程师代码的质量和性能。测试开发工程师是软件测试工作的技术类型。除了做常规的测试工作,他还可以编写一些测试工具和自动化脚本,用自动化的手段提高测试的质量和效率。风控和反作弊工程师负责业务生态,监控业务异常问题,提高业务风控效果。安全合规工程师负责信息安全,可以为项目提供合规咨询和信息安全风险评估。
3.1.2 面向失败设计的组织形式安全生产团队是针对故障设计的组织形式。安全生产团队往往是一个横向的技术团队,为规范制定和实施、生产过程控制、事故重复组织等几个业务团队提供技术支持。,并对在线质量负责。通常在每个业务团队中设立一个负责系统稳定性的人,作为接口人,有效执行他们制定的制度。
结对编程也是故障设计的一种组织形式。严格地说,结对编程需要两个程序员在一台计算机上一起工作。一个人输入代码,另一个人检查他输入的每一行代码。结对编程可以让程序员写出更短的程序,更好的设计,更少的缺陷。同时结对编程还可以促进知识的传播,让新人进步很快,让老人在带新人的过程中总结自己的知识和经验,避免相应开发人员离职或辞职带来的工作交接问题。
严格来说,结对编程在互联网行业是极其罕见的,很少有团队会真的这么做,或许是因为在管理者看来,两个人做同样的事情,大大增加了人力成本。但是结对编程的一些思想和理念也值得我们借鉴。比如我们可以让两个程序员结对做业务负责人,互为备份,互为代码评审,在一定程度上获得结对编程的好处。
3.2 流程假设不进行面向失败的设计,软件开发过程可以简化为两个步骤:编码和发布。但是,成熟企业的发展过程大致如下:
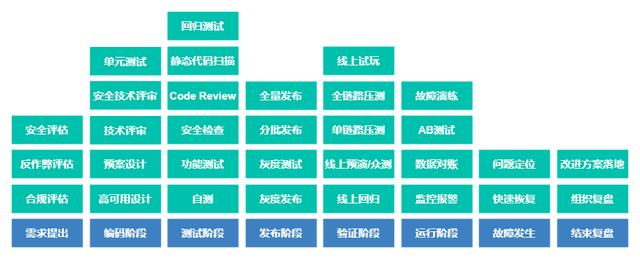
在需求呈现阶段,需要提前做一些合规评估、反作弊评估、安全评估,在前期消除一些潜在的安全合规风险。
在编码阶段,设计技术方案时,要考虑止血/降解/回滚的措施,组织技术评审和安全技术评审,对技术方案中的安全风险进行一些评估。另外,最好做一些单元测试,这样可以大大提高代码的质量。
在测试阶段,开发人员要做自检,然后测试工程师要参加功能测试,安全工程师要做安全检查。鉴于代码更改可能带来的额外影响,应该进行更大规模的回归测试,以消除一些意想不到的影响。
在发布阶段,需要采用灰度发布的机制,先发布少量机器,或者只针对部分地区用户的灰度。灰度释放后,做灰度测试,验证功能正常,继续批量释放和完全释放。
验证阶段允许测试生在发布后进行一次在线回归,以保证功能的在线环境稳定可用。对于大型活动,往往需要组织内部用户在线预览或公测。鉴于意外内部流量可能造成系统挂起的风险,可以做单链路压力测试和全链路压力测试。大型活动开始前,如果条件允许,或者小范围做一个线上演示,提前暴露一些风险。
在运营阶段,需要开发者做好监控报警和离线数据对账工作。对于项目的效果,可以用AB检验来量化收益。
发生故障时,必须在第一时间迅速恢复故障,将网上损失降到最低,然后再考虑定位故障原因。
项目完成或故障排除后,需要组织有效的复制,对过程中的问题进行总结,形成有效的改进计划,持续跟踪改进计划的实施。
3.3 一些观点3.3.1 测试同学的重要性,怎么吹都不为过测试工程师是在线质量最重要的守护者,他们的重要性不能被夸大。一个优秀的测试生可以做到以下几点:
编写单元测试用例看似耗时,其实是最省时的方式。单元测试保证了代码的行为与我们的预期一致,从而节省了大量发布、自测、联调、修改代码的返工时间。此外,可用于单元测试的代码往往职责更清晰,分层更合理,稳定性更好。
3.3.3 复盘是对齐做事高标准的一个必要方式复试是不断优化组织,向高标准看齐的必要途径。通过PDCA(Plan-Do-Check-Action,pdsa)这样的循环,经过工作的不断改进,最终会形成知识沉淀,运用到下一步的计划执行中,这样团队的执行力会越来越强,个人也会成为更好的我。
3.3.4 研发红线是程序员的保护伞R&D红线是企业面向失败设计的有效暴力机器。它是由无数的零件(规格和物品)组成的,冰冷的,机械的,运行中不可阻挡的,独立于个人意志的。R&D红线强制程序员遵守企业的程序和规范,并警告程序员不要犯低级错误。看似冷酷无情,实则是程序员的保护伞。
四、技在技术层面,我想谈谈面向失效设计的具体技术细节。但是技术细节太多,限于篇幅,这里只列举一些经典技术问题的解决方法。
4.1 将面向失败当做系统设计的一部分你只看到了二楼,你把我当成了一楼。实际上,我在五楼。
——芜湖福马
Redis在六个层次上实现了分布式锁。让我们看看我们通常使用的分布式锁处于什么级别。
分布式锁的设计原则:
第一级:
雷迪斯。SetNX(ctx,key,& # 34;1") defer redis.del(ctx,key)使用SetNx命令,可以解决互斥问题,但不能做到无死锁。
第二级:
雷迪斯。SetNX(ctx,key,& # 34;1",expiration) defer edis . del(CTX,key)使用lua脚本保证SetNX和Expire的原子性,做到无死锁但无一致性。
第三级:
Redis.set NX (CTX,key,随机值,expiration) deferreredis . del(CTX,key,随机值) /以下是del if redis . call(& # 34 get & # 34;,KEYS[1]) == ARGV[1]然后 返回redis . call(& # 34;德尔& # 34;,keys[1]) else return 0 end将分布式锁的值设置为一个随机数。删除时,只会删除当前线程/线程抓取的锁,避免在程序运行过慢、锁过期时删除其他线程/线程的锁,可以达到一定程度的一致性。
第四级:
func my func()(errCode *常量。error code){ errCode:= distributed lock(CTX,key,randomValue,lock time) defer deldistributed lock(CTX,key,randomValue) if errCode!= nil { return errCode } //do something } func distributed lock(CTX上下文。上下文、键、值字符串、到期时间。持续时间)(错误代码*常数。ErrorCode) { ok,err := redis。SetNX(ctx,key,value,expiration) if err = = nil { if!OK { 返回常量。err _ mission _ got _ lock } Return nil } //针对超时和成功的场景,先获取看看情况 time . SLE . = nil { Return constant。err _ cache } if v = = value { //表示超时成功 return nil } else if v!= ""{ //表示被别人抢了 Return常量。Err _ mission _ got _ lock } //表示锁没有被别人抢,再抢一次 OK,Err = redis。= nil { 返回常数。ERR_CACHE } if!OK { Return constant . err _ mission _ got _ lock } } /以下是del ifredis . call(& get & # 34;,KEYS[1]) == ARGV[1]然后 返回redis . call(& # 34;德尔& # 34;,keys[1]] else return 0 end //如果你的Redis版本已经支持CAD命令,那么上面的lua脚本可以改成下面的代码 func deldistributedlock(值字符串)(errCode *constant。ErrorCode) { v,err := redis。Cad(ctx,key,value) if err!= nil { 返回常数。err _ cache } Return nil }解决超时和成功的问题。写超时和成功是一个偶然的,灾难性的经典问题。
剩下的问题是:
第五级:
启动计时器,并在锁到期但进程未完成时续订租约。只有当前线程/协同进程获取的锁才能被续订。
//下面是renewal的lua脚本,实现了CAS(compare and set) ifredis . call(& # 34;获取& # 34;,KEYS[1]) == ARGV[1]然后 返回redis . call(& # 34;过期& # 34;,keys [1],argv[2]) else return 0 end //如果你的Redis版本已经支持CAS命令,那么上面的lua脚本可以改成下面的代码 redis.cas。
同时,我们可以发散性的思考。续租的方法失败了怎么办?我们如何解决“用于保证高可用性的高可用性方法的高可用性”这个娃娃问题?开源类库Redisson使用了watchdog的方法在一定程度上解决了锁的更新问题,但是在这里,我个人建议不要更新锁,更简洁优雅的方式是延长到期时间。因为我们的分布式锁代码块的最大执行时间是可控的(取决于RPC、DB、中间件等调用设置的超时时间),所以我们可以设置超时时间大于最大执行时间。
第6级:
Redis的主从同步(复制)是异步的。如果主服务器在向主服务器发送修改数据的请求后突然出现异常,发生高可用性切换,缓冲区中的数据可能无法同步到新的主服务器(原始副本),导致数据不一致。如果丢失的数据与分布式锁有关,就会导致锁机制出现问题,从而导致业务异常。本文介绍了这一问题的两种解决方案:
(1)使用红色锁。红锁是Redis作者提出的一致解决方案。红锁的本质是一个概率问题:如果高可用切换时一个主从Redis失锁的概率是k%,那么n个独立Redis同时失锁的概率是多少?如果用红锁来实现分布式锁,那么失锁的概率是(k%) n,鉴于Redis极高的稳定性,此时的概率完全可以满足产品的需求。
红色锁的问题是:
(2)使用等待命令。Redis的WAIT命令将阻塞当前客户端,直到该命令之前的所有写命令都成功地从主服务器同步到指定数量的副本服务器,并且可以在命令中设置以毫秒为单位的等待超时。锁定后,客户端将等待数据成功同步到副本,然后再继续其他操作。WAIT命令执行后,如果返回结果为1,则同步成功,无需担心数据不一致。与红锁相比,这种方法大大降低了成本。
4.3 热点库存扣减秒杀是一个很常见的面试问题。很多面试官上来就要求面试官设计一个秒杀系统。当然,面试官都是“身经百战”的,很快就能背出“标准答案”。
但是秒杀还是一个比较简单的库存扣除热点问题,因为扣除的库存并不大。一个比较典型的热点库存扣费问题是春节红包雨,同一个资金池上亿人抢红包。介绍两种春节红包雨方案:
方案一:
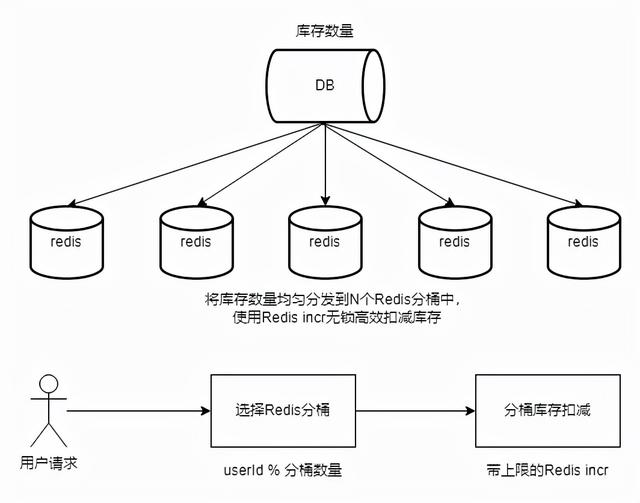
存在的问题:
方案二:
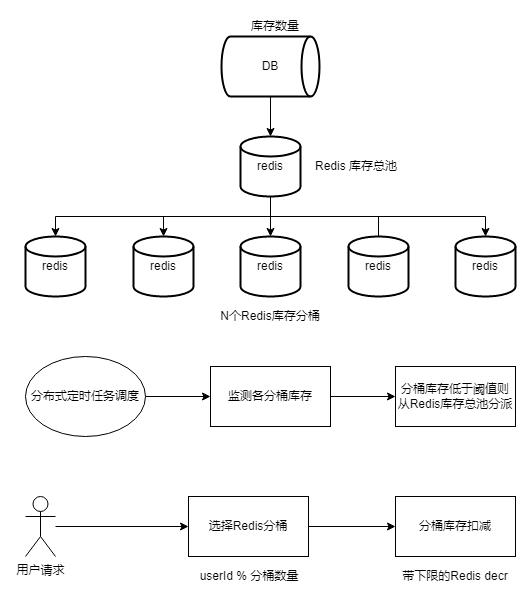
分几次分配库存,从而缓解桶库存消耗不均的问题。
2021 Tik Tok春节红包也是一个很好的技术思路,分散了用户的进入时间,降低了瞬时请求高峰。
如何体现面向失败的设计:
(1)为什么要在桶内库存不足的情况下,使用预定任务调度来主动分配库存,而不是被动拉库存?
答:因为主动调拨库存的QPS比被动拉库存低几个数量级。
(2)流量过大怎么处理?
答:流量达不到DB,分桶散。
(3)为什么3)Redis库存主池不需要主机维护,机器是通过预定任务调度随机选择的?
答:反单点。
五、跋编程之美是惊人的。好的代码往往结构清晰,表达清晰,设计巧妙。无论是阅读还是编写代码,都能给程序员一种直击心灵的美感,甚至让读者爱不释手,让作者引以为傲,引为自己的代表作。但为了留住这份美好,我们还是要做面向失败的设计,充分考虑失败场景,这样才能降低失败的概率,从死亡中活过来。
本文对面向失效的设计做了一些粗浅的思考,欢迎讨论、补充和修正。
六、引