回顾了近年来自然语言处理的发展,从项目实施的两个阶段梳理了自然语言处理技术的应用演变。

第一个跟大家分享的案例是基于NLP的。它分为三个部分,即NLP的发展,项目说明和经验教训。
谈NLP的发展是为了更好的了解这项技术,为项目的发展做铺垫。经验教训是作者总结整个项目后自己的收获。
作者本人不是计算机类的,对理论知识的理解难免不深刻,可能会有偏差。请给我你的建议。
目录:
1.1自然语言处理的定义
专注于人类语言和计算机之间交互的研究领域被称为自然语言处理,简称NLP。它位于计算机科学、人工智能和计算语言学(维基百科)的交叉点
总结一下维基百科对NLP的定义,NLP关注的是人类语言和计算机之间的交互。
使用语言,我们可以准确地描述我们大脑中的想法和事实,我们可以倾诉我们的情绪,与朋友交流。
电脑底部只有两种状态,分别是0和1。
那么,机器能听懂人类的语言吗?
1.2自然语言处理的发展历史
自然语言处理的发展经历了两个阶段。第一阶段以“鸟飞派”为主,第二阶段以“统计派”为主。
让我们进一步了解这两个阶段之间区别,
第一阶段,学术届对自然语言处理的理解是:机器要想做翻译或语音识别等只有人类才能做的事情,就要先让计算机理解自然语言,而要做到这一点,就需要计算机具备像我们一样的功能。这种方法论被称为“鸟飞派”,即我们可以通过观察鸟类如何飞行来模仿它们制造飞机。
第二阶段,今天,机器翻译已经做得很好了,上亿人用了。在自然语言处理领域的成功依赖于数学,更准确地说,依赖于统计学。
第一阶段到第二阶段的转折点是在1970年,推动技术路线转变的关键人物是弗里德里希·雅尼克和他领导的IBM沃森实验室。(对IBM沃森实验室感兴趣的朋友可以看看吴军的《潮之巅》,里面有详细的描述。)
我们今天看到的NLP相关的应用都是基于统计的。那么,NLP目前有哪些应用呢?
1.3自然语言处理目前的主要应用
目前,NLP已经广泛应用于知识图谱、智能问答、机器翻译等领域。
二、项目阐述2.1业务背景
注:在项目描述中,具体细节已经隐去。
客户是一家提供金融投融资数据库的科技公司。在其产品线中,有一个产品叫人人库,包括投资人库和创始人库。
我的服务就是服务这两条产品线。因为这个项目主要关注相关人员的简历信息,所以项目代号为“蔡雅艺信息提取”。
被抽取人的简历信息由学校、工作、投资(案例)、创业经历、获得荣誉五部分组成。
2.2项目指标
项目指标包括算法指标和工程指标。
2.2.1算法索引
在算法层面,指标用的是召回率和精度。为了避免大家对这两个指标比较熟悉,我带大家一起回顾一下。
我们先来了解一下混淆矩阵。混淆矩阵是分别统计分类模型中被分类到错误类和正确类的观测值的个数,然后将结果以表格的形式显示出来。矩阵中的每一行代表预测类别,每一列代表实际类别。
通过混淆矩阵,可以直观地看出系统是否混淆了两个范畴。
我们可以举一个混淆矩阵的例子:
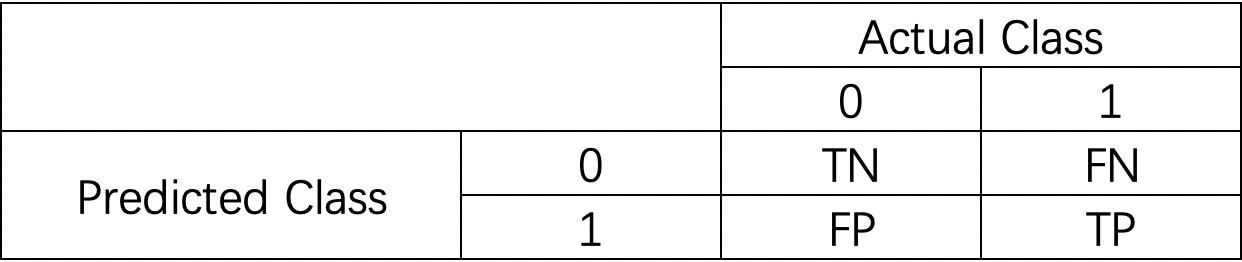
0代表消极,1代表积极。
除了以上,我们还需要知道以下三个指标,即召回率、准确率和f1。

好了~了解了以上测量算法模型中用到的基本概念后,我们再来看看这个项目的指标。
模型索引为:回忆90;;精度60 .
一个思考问题?为什么召回90,精度60?还有为什么没有f1,或者为什么f不设为72,因为如果recall 90,precision60,那么在这种情况下,f1就是72。
回答以上问题,要从业务说起。记住,连背三遍。
为什么在做指标的时候,一定要从业务入手?
我们举一个非常极端的例子。如果一个模型能做到recall90 precision90,是不是可以说这个指标很好?
我相信这个模型在大多数场景下都是很优秀的。请注意,我说的是绝大多数,那么哪些场景不是呢?
比如癌症检测。
假设您目前正在密切关注一个“癌症检测”项目。对于每个检测到的对象,有以下两种结果之一:
你的同事告诉你一个好消息。你的模型在测试集上的准确率是99%。听起来很棒,但你是一个严肃的AI PM,所以你决定自己审查测试集。
你的测试装置已经被医学专家贴上标签。你的实际情况测试设置如下
有了上面的数据,也就是我们模型验证的GroundTruth,接下来,我们来看看这个模型的预测结果。现在我们已经学习了上面的冲突矩阵,让我们回顾一下冲突矩阵的两个特征。行代表预测的类别,列代表实际的类别。让我们来看看:
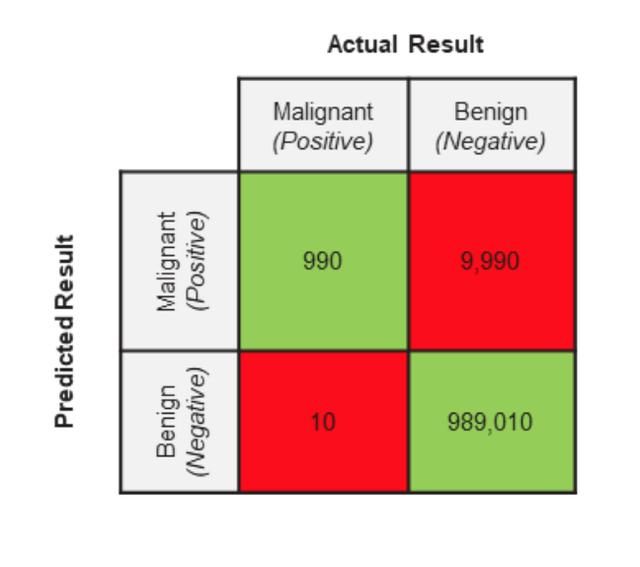
根据所学,在实践中应用:
我可能觉得有点头晕。没关系。我马上给你总结一下:模型的正确判断是1和3,不正确判断是2和4。
我们希望这个模型能够区分医学图像是否是恶性肿瘤。好的区分是指1和3。除此之外,其余都是错误的区分。
在这里,我们来看看模型的性能。
当我的同事告诉我们模型的准确率是99%的时候,她是什么意思?大家仔细分析一下吧~
她说精确了吗?
Precision回答了我们的模型预测的样本数与实际样本数的比例问题1。用公式表示

在真实的应用场景下,我们的准确率是990/(990+9990)= 0.09 = 9%。
她说回忆了吗?

在上面的场景中,我们的召回率是recall = 990/(990+10)= 990/1000 = 0.99 = 99%。
她说准确了吗?
在上面的场景中,我们的准确度是准确度= (990+989,010)/1,000,000 = 0.99 = 99%。
从以上指标可以看出,我们的算法模型具有较高的召回率和准确率,但准确率较低。
我们算法模型的精度只有9%。这意味着大多数被预测为恶性肿瘤的医学图像是良性的。能说我们的算法模型是垃圾吗?
不完全是。实际上,在我们的算法模型中,召回比精确更重要。所以虽然我们的准确率只有9%,但是召回率是99%,这其实是一个比较理想的模型表现。因为,患者得了癌症,却在检查时被漏诊,这是谁都不愿意发生的事情。
也许这个时候,你会有一个疑问,如何确定召回率和准确率的重要性?好吧,让我们仔细看看。首先,我们来了解一下指标的设定原则:指标的设定取决于我们的经营目标和误报、漏报造成的损失。
什么时候回忆比精确更重要?
在FN会带来巨大损失的情况下,召回会很重要。举个例子,如果恶心的肿瘤被预测为良性,这就是一个非常严重的后果。这种预测会让患者无法得到适当的治疗,从而导致患者失去生命,而且这个过程是不可逆的!高召回率是我们要尽量减少假阴性,虽然这样会带来更多的假阳性。但是通过一些后续的检查,可以排除这个FP。
什么时候精确比回忆更重要?
在FP会带来很大损失的情况下,精度很重要。例如在邮件检测中。垃圾邮件为1,普通邮件为0。如果有很多的FPs,就会有大量的正常邮件存储在垃圾邮件中。后果很严重。
讲到这里,我们来来回回看一下我们业务的召回90精密60。为什么我们要把它做成这样?这还是得从业务背景说起。当我和团队分享如何评估客户的AI需求时,很重要的一步是首先了解他们在没有机器的情况下是如何做到的。他们这样做的标准是什么?以及具体的操作步骤。
只有当我们知道这一点,我们才能根据这些领域知识设计AI解决方案。提取个人简历信息的工作是客户的运营同学负责的,那么客户的运营同学之前是做什么的呢?他们会看一篇文章,然后找出符合简历标准的信息,提取出来,进行二次加工。
哦,他们的观点是需要二次加工。这里的二次加工是什么意思?就是整合人物的一些简历信息。所以,其实对于他们来说,回忆并不是最重要的,因为不断有新的语料(文章)发表,他们总能获得相关人物的信息。但是从一篇几千字甚至上万字的文章中,准确定位人物简历的信息是非常重要的,可以提高效率。
是的,效率是我们制定自己算法指标的标准。提高回忆能力可以提高操作学生的效率。
下一个问题?为什么不把f1设为72?因为如果召回90,但是精度60,最后f1也是72,但是这不符合业务场景的需求。
2.2.2绩效指标
以API的形式交付。对于长度为1000个单词的文本,每秒查询率(QPS)为10,当一次调用为95时,响应时间(RT)为3秒。接口调用成功率99%。
先把这个性能指标拆解一下,先说交付形式。
目前AI项目交付主要有两种类型,API和Docker,分别适用于不同的业务场景。
QPS(每秒查询数)查询速率是特定查询服务器在指定时间内可以处理的流量的度量。在互联网上,一台机器作为域名系统服务器的性能往往是以每秒的查询速率来衡量的。相应的每秒读取数,即响应请求的奇妙数量,也是最大吞吐量。
RT响应时间是指系统响应请求的时间。直观上,这个指标非常符合人们主管对软件性能的感受,因为它完整地记录了整个计算机系统处理请求的时间。
2.3项目实施
项目的实施分为两个阶段。在第一阶段,我们尝试使用规则。在第二阶段,我们将策略从规则切换到模型。影响从规则到模型转化的因素有很多,有项目组随着项目的进展对项目难度认识越来越深的因素,也有数据集更加丰富的原因。
2.3.1第一阶段:规则
在项目的第一阶段,我们的尝试主要在于规则。首先,我们来介绍一下机器学习中有哪些规则。
那么,在第一阶段,我们到底对使用规则做了什么?
第一阶段,我们整理了白名单、黑名单、分词三个文本。
先说一下我们规则中使用这三个文本的逻辑,然后我再解释为什么要这样设计。
白名单:白名单是一个包含许多单词的列表。当属于白名单词典的单词出现在句子中时,我们提取句子。
黑名单:当这个词出现在一个句子中时,我们就把它扔掉。
分词:当分词列表中的一个词出现在一个句子中,我们会给这个句子加1分。(因为单词权重不同,权重不全是1)
那么,为什么要这样设计呢?
首先,我们来看白名单。白名单中的典型词有:毕业于、深造、晋升等。你可以发现这些词有很强的属性表达,显示一个人的履历。所以,当这些词出现时,我们会默认提取这句话。
黑名单中的典型词汇有:死、死、出勤等。这些话显然与简历无关。
最后,我们来看看这个分词。在评分的设计逻辑上,我们用的是TF-IDF。同时,为了减少我们样本量小带来的负面影响,我们爬取了百度百科人物库,通过TF-IDF筛选出数百个与人物简历描述相关的词,并对这些词进行人工评分。我们通过匹配句子中出现的分词来给句子打分。而且我们可以通过调整句子分值的阈值来调整我们命中人物简历的句子。
通过这些规则,我们发现该模型的效果在精度上是好的,但是召回率不够好。通过对不良案例的分析,发现该模型的泛化性能较差。
分析不良案例的思考:
顺带一提,我们在分析不良情况时,除了分析模型预测的误差,还会发现一些标注数据的问题。在训练集中,有些人标注错误的样本是正常的,因为没有人能保证他们100%正确。应当注意,这种标记误差分为两类:
对于随机标注错误,只要整体训练样本足够大,留着也没问题。必须纠正系统性的标记错误,因为分类器会学习错误的分类。
解释一下,吴恩达的课程都是关于坏案例分析的。如果你想了解更多这方面的知识,可以自学。
第一阶段遇到的困难通过对bad case的分析,我们发现passing rules最大的问题是模型不能区分动名词。所以精度很低。
举两个例子:
答:西兰花,小红投资的一家运动服饰公司。
b:小红投资了运动服装公司西兰花。
第一句表达的主要思想是运动服装公司,而第二句表达的主要思想是小红的投资,所以一开始就要从需要提取的句子定义中提取第二句。但因为评分机制的原因,两句AB都打中了“投资”,所以都被提取出来了。
从这里我们发现我们的规则之路基本走到了尽头,评分的方式是AB永远无法区分,于是我们开始了接下来的探索之旅。
2.3.2第二阶段:模型
第一阶段我们讲了规则的一个缺点,就是规则不能区分词性。
经过评估,我们还是打算用模型来做,根据前一阶段的发现做相应的优化。这里,我们来介绍一下“词性标注”
词性标注也叫词性标注。
词性标注非常有用,因为它们揭示了一个单词及其相邻单词的大量信息。
让我们看看具体的用例。

根据POS,我们发现“狗”是名词,“然”是动词。你认为这种方法正好可以弥补模型不能区分动名词的困难吗?
所以,我们把POS加到所有的数据上,然后把Bert放进去。这里还有一个小提示。因为我们的数据量其实很小,Bert只训练了一轮。
既然谈到了Bert,那我就和大家再复习一下Bert(我不是专业的,也不是专门研究NLP的,所以我自己的知识积累有限。如果你有更好的想法,欢迎交流讨论90度鞠躬)
首先,我们理解一个概念“预训练模式”。
预训练模型是一些人用大数据集训练出来的模型。这个模型中有一些初始化参数,这些参数不是随机的,而是从其他类似数据中学习来的。
Bert是Google开源模型。非常牛逼。多棒啊。这是从伯特的试场和模特表演效果,两个维度。
适用领域,Bert可用于各种NLP任务,只需在核心模型中增加一层即可,如:
在词性和Bert的加持下,我们模型的性能达到了召回率90,准确率90。
先停在这里一会儿吧~
三、Lesson Learned其实从项目推广、数据集管理、策略分析等方面来说,我觉得还有很多要讲的,要写的,我觉得太多了。之后,我们再分开写。
参考资料:
1.语言本能
2.数学之美
3.智能时代
4.2018年NLP的研究和应用进展如何?
5.https://en . Wikipedia . org/wiki/Confusion _ matrix # cite _ note-powers 2011-2
6.https://lawtomated . com/accuracy-precision-recall-and-f1-scores-for-lawyers/
7.【吞吐量(TPS)、、并发和响应时间(RT)的概念】——胡·——博客园】(https://www.cnblogs.com/data2value/p/6220859.html)
8.【不良案例分析】(http://git Linux . net/2019-03-11-Bad-Case-Analysis/)
9.【结构化机器学习项目】第二课——机器学习策略2_人工智能_【人工智能】王的博客——博客】(33761963/article/details/80559099)
10.【5分钟介绍谷歌最强NLP模型:Bert——简书】(https://www.jianshu.com/p/d110d 0c 13063)
11.https://arxiv.org/pdf/1810.04805.pdf《伯特:语言理解双向转换器的预训练》
本文由@一朵西兰花原创发布。每个人都是产品经理。未经许可,禁止转载。
图片来自Unsplash,基于CC0协议。