项目背景
闲鱼是一个闲散共享的交易社区。为了增加交易的乐趣,闲鱼在产品设计上有意识地通过买卖双方的互动来促进商品的交易。无论是我们下单商品前需要进行一次聊天,还是通过群组互动分享交流商品,比如鱼塘话题,都是这种设计思路的体现。
但闲鱼买卖双方的互动仍存在以下问题,影响交易和体验:
针对上述业务中存在的问题,闲鱼技术团队与达摩院机器智能技术团队合作,在闲鱼用户私聊场景中引入自动问答,帮助卖家及时准确回复,合理协商,提升互动体验,促进交易。
技术框架
针对以上问题,仙宇推出了聊天机器人,希望在卖家离线的情况下,自动识别买家意图,帮助卖家回答相关问题(问答模块)。为此,我们应该首先帮助用户自动建立一个知识库,这个知识库由与商品或交易相关的问题和答案的键值对组成。为了构建问答知识库,一方面从用户信息和产品信息(图片/文字)中提取相关属性,生成相关答案(属性初始化模块);另一方面,在买卖双方对话的过程中,提取卖家的真实答案,生成相应的答案(用户对话提取模块)。
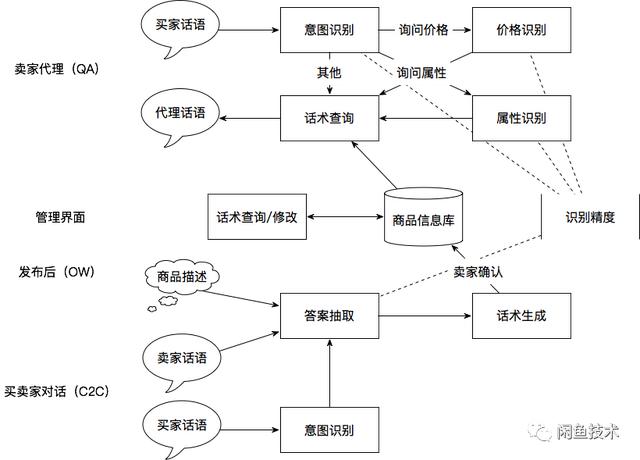
图1闲鱼自动回收总体技术框架

相应地,闲鱼聊天机器人模块可以分为三个部分:
属性初始化模块
用户开启自动回复功能后,会根据用户的基本信息,如离线自动回复、是否打包、发货地址等,提取生成一个基于用户的常见的问题/答案的键值对。这种配置可以支持用户没有单独设置自动回复的所有产品。
用户发布或编辑商品后,根据商品属性信息提取热点问答的键/值键-值对,推荐给用户回复。用户确认后,会存储在配置服务中生效。比如针对买家不同出价的谈判策略,或者通用配置中的对应数据,都被宝宝型回复语音覆盖。
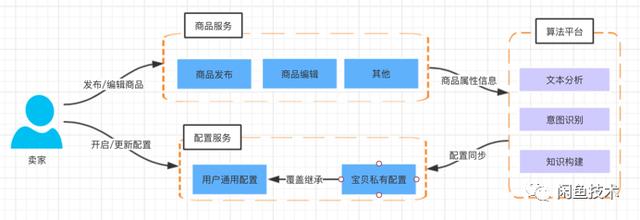
图2属性初始化
问答模块
在卖家不在线的情况下,帮助卖家自动回答买家的问题。该模块识别买家提问的意图,并返回卖家在商品信息数据库中预设的答案。一方面减少了买家等待回复的时间,提升了交互体验;另一方面节省了卖家的回复时间,提高了效率。
用户问答知识提取模块
用卖家和买家互动中的问答来补充商品信息库。对于发布时缺失的产品信息,可以通过用户在对话过程中形成的问答对进行答案抽取和语音生成。此外,用户在聊天过程中对已有的问题产生新的答案,他们会通过这个模块及时更新答案。
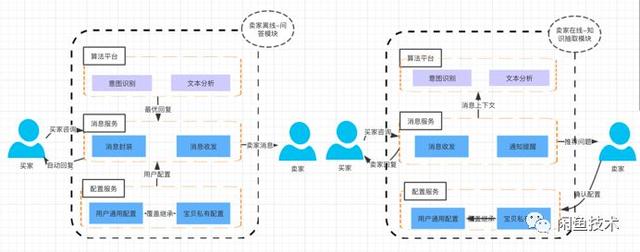
图3问题回答和知识提取
在实际落地中,我们使用问答回复结构存储用户问题/答案的键值对,以便用户使用回复配置个性化回复语音:当算法规则命中问题和答案的键值对时,闲鱼会使用回复中指定的信息构造消息文本发送给买卖双方,并将此消息标识为卖家配置的自动回复。
核心算法
闲鱼自动回复算法平台基于AliNLP提供的底层NLP算法能力,构建了意图识别模块和语音生成模块两大核心算法。
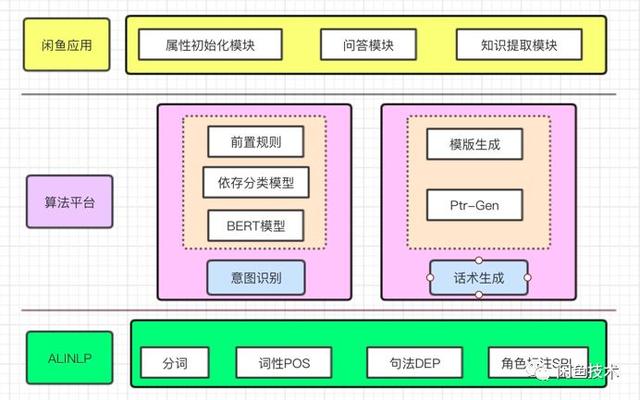
图4算法架构
意图识别
意图识别的最大困难在于语言表达的模糊性或歧义性。比如用户搜索苹果,潜在意图可能是水果或者手机。其次,汉字组合千变万化,语言表达非常丰富。比如“1500元怎么样”“便宜100元我就买”“真心想要,128包邮”等等都表达了“砍价”的意图。因此,意图识别和分类应运而生。
经过分析,有20%左右的用户对话是闲鱼聊天场景中的常见问题,可分为四类:价格、砍价(关注度最高);商品的属性(如颜色、规格等。);二手市场的转售属性(如新旧);信息(如邮资)。由于属性之间的巨大差异,我们结合不同的分类模型来识别用户的查询意图。
针对不同的属性,采取针对性的方案,构建了24个不同属性的模型,基本涵盖了购房者的常见问题,大部分属性的准确率达到了90%:
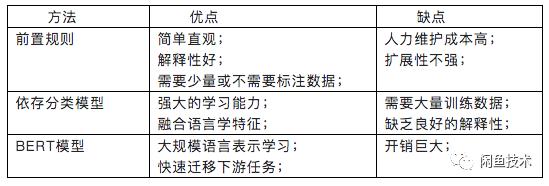
表1意图识别的主要方法比较
Pre-rule 通过关键词匹配获取查询意图,比如包含“颜色”来识别用户询问的是颜色属性。当然这样会造成很多错误的判断,比如“这件红色的衣服多少钱?”以及“这件衣服是红色的吗?”。因此,我们额外引入了句法结构信息,并使用依赖模型来分析句法信息,从而将颜色意图识别的准确率从70%提高到84%。在之前的基于规则的方法中,我们人工收集和标注了大量的数据,用于机器学习和深度学习方法的后期训练。
依存分类模型深度学习得益于单词的分布式表示(word2vec等。)和强大的学习能力(CNN/LSTM/Transformer),可以自动获取整个句子的语义表示,然后从大规模、高质量的训练数据中自动学习其中包含的抽象复杂关系。依存分类模型额外引入了词性和句法信息。首先,找出词汇表中每个词和词性的向量表示。然后,通过注意机制获得上下文敏感的句子表征,注意模型允许额外注意句子中的重要信息。通过在注意模型中加入依赖核心词的信息,进一步强化重要的句法成分,如“这件衣服是红色的吗?”会关注“衣服”、“是”、“红色”这些关键词,从而获得句法增强的句子表征。通过依存分类模型,属性识别的召回率从44%提高到74%,丰富了多样化表达语义的识别。BERT模型BERT模型开启NLP新时代。通过预训练语言模型,有助于进行超大规模的表征学习。通过微调,训练好的模型可以用上下文理解语义,实现更准确的文本分类。在基本模型上,我们引入额外的对话角色进行训练,整体准确率提高了4分,预训练模型也提高了其他相关任务的性能。
语音生成
为了帮助用户建立和维护知识库,我们从买卖双方的聊天中收集常见的问答对来生成答案。整个过程分为三步:

图5语音生成算法流程
答案生成模块的主要瓶颈是属性抽取的召回率低。未来,我们将结合依存信息和语义信息等语言特征来提高属性抽取的性能。
应用和效果
场景示例
在对话的例子1中,买方试图与卖方沟通并讨价还价。卖家在买家询问12.5小时后才在线回复用户,回复的内容页面比较生硬,所以最终没有卖出产品。
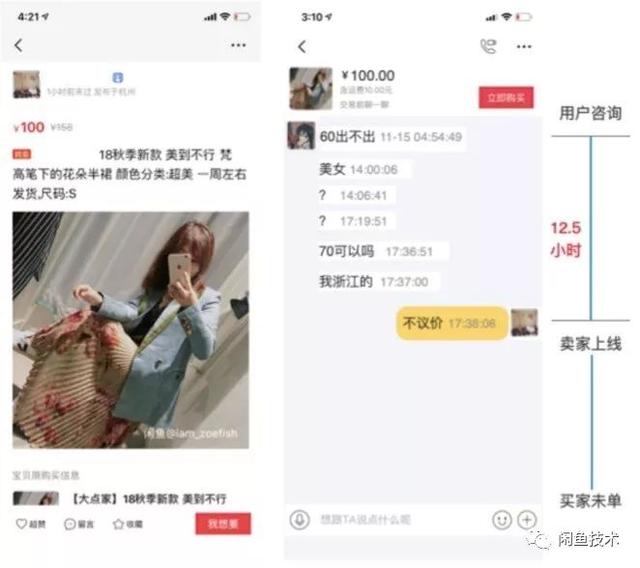
图6对话框示例1-没有设置聊天机器人。
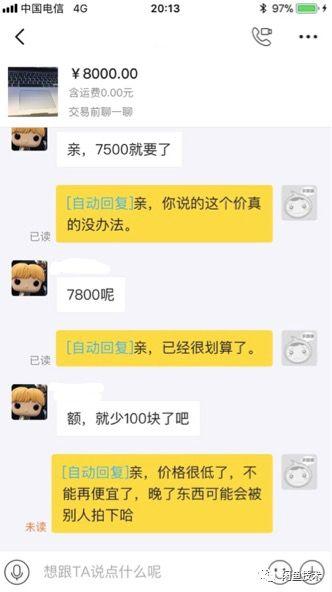
图7对话示例2-打开聊天机器人
对话例2中,用户咨询先启动聊天机器人的砍价周宣逻辑,及时与买家沟通。并引导买家有更多的互动和咨询,增加购买意愿。沟通中的话包括砍价和邮费,提供宝贝价格信息,管理买家预期,促进交易。在具体的言语表达中,使用了卖家预设的配置信息,使得交互更加亲切友好。所以卖家简单在线沟通后,卖家很快就下单了。
业务影响
经过几个月的上线测试和算法迭代,通过对比用户有聊天机器人和没有聊天机器人的相关数据,我们在商业上也得到了一个相对稳定的结论。
*给小鲜鱼投简历→guicai . gxy @ Alibaba-Inc.com
更多文章、开源项目、关键见解、深度解读
请找闲鱼科技