作为一名编辑,除了写作这一主要工作之外,你往往还需要考虑一个非常重要的问题:插图。
全文字的文章当然不会以图文的形式抓住人们的眼球,更何况是这个视频当道的年代。所以我每次写文章都要在无版权图片网站上精挑细选,让图片与文章主旨相吻合,最好使用高分辨率的图片。
但是,总有意外。有时候,遇到分辨率不够却是最合适的图像,是很苦恼的。如果把低分辨率的图像直接插入文章中,会明显感觉到视觉上的不适。虽然现在PS甚至Windows自带的画图工具可以修改图像分辨率,但是强行拉伸的结果只会是图像很粘。
可以看到,拉伸图片后,图片边缘已经有明显的毛刺感。
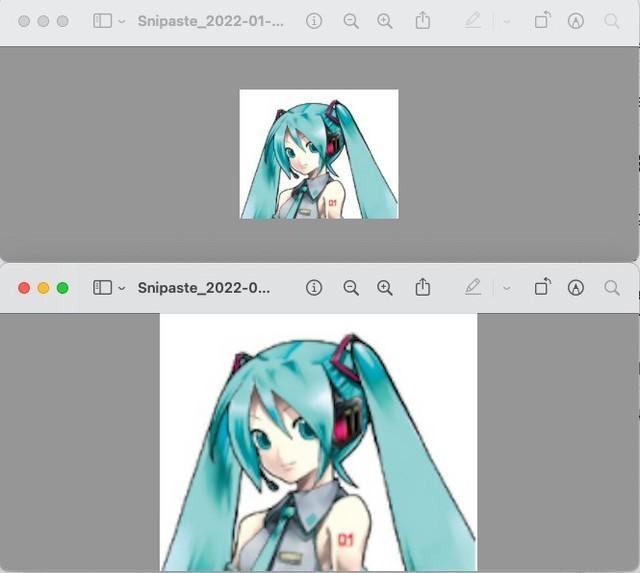
有什么办法可以无损放大图片?
不说了,有。GitHub的这个项目“waifu2x”可以做到。
项目地址是https://github.com/nagadomi/waifu2x,,有兴趣的朋友可以研究一下。网页地址是http://wAIfu2x.udp.jp/.
闲话少说,下面是使用waifu2x和普通拉伸图片的对比(左边是拉伸,右边是使用waifu2x的效果)。
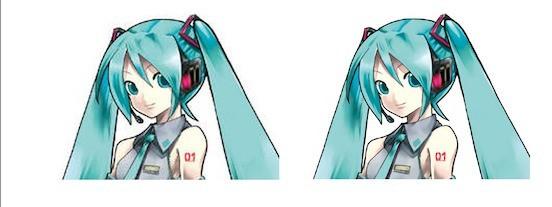
大家可以看到,用waifu2x放大图片后,“5G”边缘的毛刺不再明显。虽然有些区域还是有噪点问题,但总体来说,效果比直接拉伸要好得多。
那为什么waifu2x可以无损放大画面?这是因为waifu2x使用了名为SRCNN的卷积算法。传统上,图像超分辨率问题研究的是如何在输入一幅低分辨率图像的情况下得到一幅高分辨率图像。传统的图像插值算法可以在一定程度上达到这种效果,如最近邻插值、双线性插值、双三次插值等,但是这些算法得到的高分辨率图像并不理想。
SRCNN是第一个采用CNN结构(即基于深度学习)的端到端超分辨率算法。它通过深度学习实现整个算法流程,效果优于传统的多模块集成方法。SRCNN流程如下:首先,输入预处理。输入的低分辨率LR图像通过双三次算法放大到目标尺寸。然后,下一步算法的目标是通过卷积网络处理,从输入的模糊LR图像中得到超分辨率的SR图像,并使其尽可能与原图像的高分辨率HR图像相似。
与双三次、SC、NE+LLE、KK、ANR、A+相比,SRCNN在大部分指标上表现最好,恢复速度也位居前列,RGB通道的联合训练效果最好,也就是说相比照片,waifu2x在放大插图(自己喜欢的二次元图片)上更有优势。
对于SRCNN卷积算法,可以去https://arxiv.org/abs/1501.00092了解更多细节。
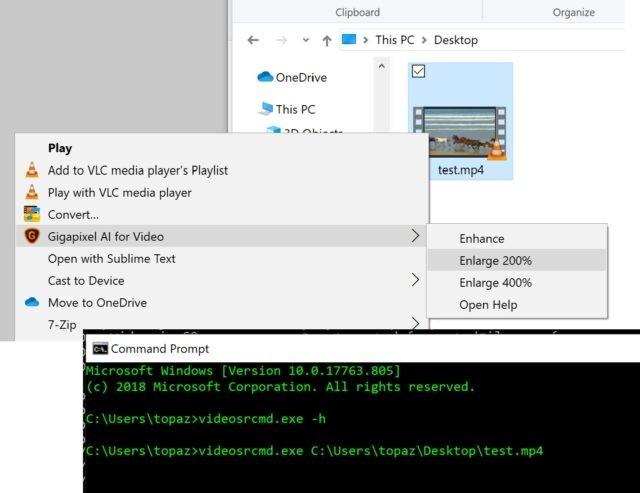
既然图片可以无损放大,那视频呢?
当然,结果是可行的,但是这次使用的工具叫做Topaz Gigapixel AI for Video。这款软件由数千个视频训练而成,结合多个输入视频帧的信息,通过真实细节和动作一致性,将视频放大到8K分辨率。
作为一个AI软件,它需要一台速度很快的电脑。推荐的系统配置是32 GB RAM加NVIDIA显卡,显存6GB以上。虽然在旧电脑上勉强可以运行,但是会很慢。

那么Topaz Gigapixel AI for Video是如何放大视频的呢?其实在安装的时候,你会发现这个软件会安装TensorFlow库和cuDNN库,所以很明显,这个软件是用基于深度学习的卷积神经网络来处理每一帧,全程运行CUDA单元(不然不会这么慢)。
熟悉显卡的老朋友都知道,显卡作为主机的重要组成部分,是计算机进行数模信号转换的设备,承担着输出和显示图形的任务。显卡连接在电脑的主板上,将电脑的数字信号转换成模拟信号,由显示器显示。同时显卡还是有图像处理的能力,可以帮助CPU工作,提高整体运行速度。显卡对于从事专业平面设计的人来说非常重要。民用和军用显卡的图形芯片供应商主要有AMD和NVIDIA(英特尔今年也会加入混乱)。
GPU结构相对简单,计算单元数量多,流水线极长,特别适合处理大量统一类型的数据,比如矩阵乘法和加法。所以显卡在AI领域的应用已经非常广泛。CUDA是NVIDIA推出的只能用于自家GPU的并行计算框架。只有安装了这个框架,才能进行复杂的并行计算。主流的深度学习框架都是基于CUDA的GPU并行加速,Tensorflow也不例外。
可惜的是,视频用的Topaz Gigapixel AI价格还是比较贵的。接近200美元的价格可以让很多人望而却步,但是对于一些老影视作品的恢复或者修复还是挺有用的。现在在哔哩哔哩能搜到的相当一部分【4K修复】视频都是基于这个软件制作的。

现在想想,AI的出现确实解决了很多生活中的实际问题。没有卷积神经网络的快速发展,看到高清重印的古代影视作品可能只存在于想象中。
(7855060)