编辑:Q好困。

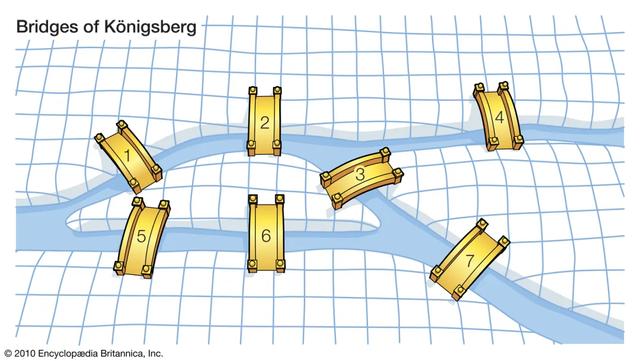
18世纪,欧拉提出了著名的柯尼斯堡七桥:
河中心的岛屿通过七座桥与河岸相连。在所有的桥只能走一次的前提下,怎么才能走完这个地方所有的桥?
在后来发表的论文中,欧拉证明了合格行走法不存在,这篇论文成为图论史上第一篇重要文献。
图是一种抽象的数据结构,用于表示对象之间的关系。顶点和边用于描述:顶点表示对象,边表示对象之间的关系。
图计算是用图作为数据模型来表达问题和解决问题的过程。旨在高效解决图形计算问题的系统软件称为图形计算系统。
对图计算技术的研究可以追溯到20世纪四五十年代。
然而,图计算逐渐进入人们的视野,是由Google在2010年发表的论文《Pregel:大规模图计算系统》引起的。

https://kowshik.github.io/JPregel/pregel_paper.pdf
《蚂蚁森林》大家都很熟悉。大家会不会一起床就“偷”朋友的能量?
你想象不到的是,这一切都是有图计算支撑的!

你消费或做其他低碳行为后,会获得一些能量,被自己和朋友实时看到,这就需要超大图像的高效计算能力。
当朋友偷能量时,每个打开蚂蚁森林的人都会实时看到。
别人不会偷10克,用户这里还有10克。我不会偷10克,因为还有其他朋友。我本来只有10克,最后还是被偷了20克。
如果用户规模变得非常大,那么“偷能”这个动作就需要很高的时效性和数据一致性。
在这样的“游戏”场景中,蚂蚁发展出了在超大规模地图上计算高数据量、低吞吐量和延迟的能力。
近年来,随着数据的多样化、数据量的大幅增长和计算能力的突破,超大规模图计算正在大数据公司中发挥越来越重要的作用,尤其是以深度学习和图计算相结合的大规模图表示为代表的一系列算法。
与传统的基于二维表结构的数据库或大数据模型相比,图数据结构非常适合实时高效地分析事物之间的深层次关系。
图计算的发展和应用有井喷之势,各大公司也纷纷推出图计算平台,如Google Pregel、脸书graph等。
随着新技术和新服务的推广,图计算技术已经进入了爆发的前夜。
根据DB-Engines的排名,2013-2020年,graph database的受欢迎程度增长了10倍,位列关注增长第一。
“图形数据库、图形计算引擎、知识图谱”三大热门技术方向也在全球范围内加速产业化。国内大型云厂商如阿里、华为、腾讯、百度以及一些初创企业都布局了这一技术领域。
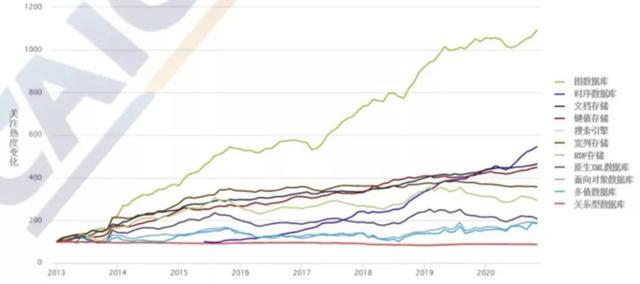
资料来源:中国信通院大数据白皮书(2020)
对于传统的“大数据”,一般以表格的形式存储。这种关系数据的特点是数据往往是“同质”的。
图形数据是一种高维数据,可以覆盖那些“非同质”的数据。
换句话说,图是现有数据模型的升级,可以让很多技术做得更好更快。

举个例子,在推荐系统中,如果根据好友的兴趣来推导某个用户的兴趣,或者根据用户购买的产品来推荐用户想要的产品,那么深度就比较浅,如果你想查它邻居的邻居(下钻3度)。
当然,以上所有的计算都是基于对个人隐私的保护。
在传统的关系数据中,这个过程中访问的数据量是指数级增长的,性能也是指数级下降的。当数据在3度以上时,很有可能关系数据库查不出来。
而在图形数据库中,不需要表的交集、并集等很多操作就可以完成。
第一列的“深度”表示社交朋友之间的关系,深度为1,表示是直接朋友;深度为2表示两个人是朋友的朋友,依此类推。
从图表中可以看出,当深度达到5时,关系数据库无法完成任务,而图形数据库的响应时间为2.132秒,在可接受的范围内。
但是,优势在一定情况下往往会转化为劣势。图形计算和处理的最大困难还在于数据处理的不规则性,这使得数据处理非常困难,尤其是在处理数十亿甚至更多的海量数据时。
当你要下钻到6度的时候,就相当于访问了整个图的所有数据,这也是很多图学习算法的局限性。
蚂蚁计算存储事业群首席架构师何昌华表示,目前几乎所有的图深度学习探索基本都是2度,能够探索到3度深度的非常少见。
蚂蚁在一些典型的图算法中已经可以探索10度以上,但是现在正在做的系统希望能够在不强制采样的情况下,不限制探索深度的进行探索。
当图形大规模甚至超大规模分布时,如何存储图形数据,如何实现高效的计算和通信成为一个非常困难的问题,这也是所有图形计算相关工作面临的共同问题。
一个非常大规模的图往往被分割成许多子图,然后放在多台计算机上进行处理,而这些子图之间需要相互通信,这样通过通信就可以知道图的所有信息,计算可以不断迭代和交互。
比如在一个图中,有人增加了一个事务,这个事务会影响到图中的很多边。如何实现一致的数据变更是一个非常困难的问题。
另外,很多传统的图计算基本上需要将所有的图加载到内存中才能高效,但实际上这样的高速是以高昂的成本为代价的。
现在很多探索会尝试把内存中的数据放到硬盘上,成本会大大降低。同时问题变成了如何高效的访问硬盘上的数据,能否以牺牲部分吞吐量为代价,将更多的数据放到外存上,从而提高外存的效率,支持更大的图像。
作为中国乃至全球正在蓬勃发展的热门领域,制定相应的技术标准的重要性不言而喻,不仅可以促进技术的全面发展,也有助于掌握相应的话语权。中国一直希望建立一些“绘图”标准,很多科技公司也一直积极参与其中。
去年9月,国家标准化管理委员会通过国家标准信息公共服务平台宣布《信息技术技术要求-地图数据库系统》国家标准正式立项,这是我国首个地图数据库国家标准项目。
《信息技术地图数据库系统技术要求》国家标准项目公示地图
公开资料显示,这一国家标准由TC28(全国信息技术标准化技术委员会)归口,蚂蚁集团牵头,多家公司共同制定。基于蚂蚁集团对标准的贡献,在国家信息标准委大数据标准工作组会议上,蚂蚁集团还被选为优秀成员单位。
除了已经建立的图形数据库国家标准,基于自身在图形智能领域的行业实践经验,蚂蚁集团还参与了一系列标准的制定:
作为图形数据库国家标准的牵头人和发起者,何昌华表示:“在图形智能领域,蚂蚁拥有图形存储、图形计算、图形分析推理、图形研发平台的技术栈GeaGraph。我们希望通过与各行业组织的标准共建,推动图形智能技术的应用和数字经济的发展。」
2015年初,蚂蚁开始组建图形数据库团队,并于2016年发布了第一个版本的图形数据库Geabase。
上线后,新版支付宝是GeaBase迎来的第一个流量。接下来,从支付宝更大规模的改版到春节红包再到双11,GeaBase进入的商家越来越多。
到了2019年,双11迎来了里程碑式的事件:单簇规模突破万亿边!
点查询,点、边或关系的查询,突破了800万的TPS,平均延迟不到10毫秒。
现在蚂蚁存储海量、超大规模地图数据的能力,已经能够做到万亿点边以上的规模,在行业内已经是非常领先的水平。
在TB的数据规模级别,大概5-6度就可以实现毫秒级结果的反馈。同时也能达到每秒百万的高吞吐量。
在LDBC的这次性能测试中,性能是第二名的7.6倍,在斯坦福的图形深度学习推理评测中也获得了第一名。
此外,蚂蚁在延迟的对比上也遥遥领先,包括六跳查询、迭代算法甚至高尾延迟,在生产环境下不到20ms,这也是业界很多其他图数据库望尘莫及的。
这些优秀的能力依赖于蚂蚁开发的GeaGraph系统:
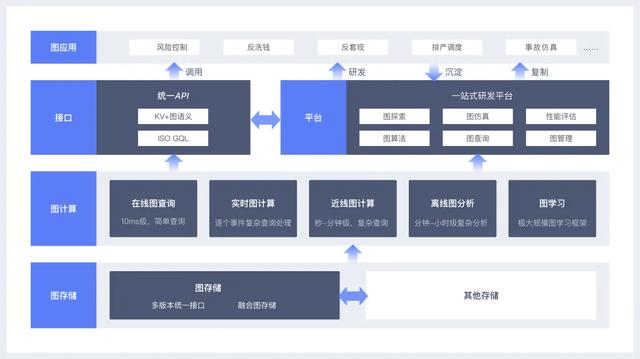
今年世界互联网大会期间,大规模图计算系统GeaGraph获得世界互联网领先科技成就奖。
GeaGraph系统包括以下部分:
1.PhStore:蚂蚁自研存储引擎,基于完美哈希技术,读图性能可达到O(1)复杂度,是业内首个基于完美哈希的KV图存储。
2.GeaBase:蚂蚁集团自主研发的金融级分布式图形数据库。GeaBase单集群可以支持万亿边的图数据,写入和查询吞吐量超过每秒一百万次,99.9%的查询和写入延迟小于20 ms。
3.GeaBase Lite:支持事务处理和强隔离的单机图形数据库,可在单机中支持百亿边的图形数据,集成全图迭代分析能力,可同时满足用户对图形的复杂分析、快速查询和可视化需求。
4.GeaFlow:自主研发的流图计算引擎,提供图探索、图模拟、动态子图匹配、流增量图计算等多种近线图计算能力,支持千亿级图数据长周期(半年/年)模拟回溯验证、每秒6度以上流子图匹配、每秒整图顺序增量图计算等关键技术能力。
5.GeaComputing:在清华大学开发的双子座和申屠离线图形计算系统上进一步优化的分布式图形计算平台,支持万亿级图形数据,能够为用户提供高效的复杂图形分析能力。
6.GeaLearning:自主研发的以图为核心的超大规模分布式深度学习系统,支持多种灵活的图模型训练方法,如不限层数的制图神经网络和节点邻居数,以模型并行行为为核心的混合并行执行模式等。
7.GeaMaker:蚂蚁自主研发的图计算一站式研发平台,整合了上述底层系统的能力,为用户提供探索、仿真、性能评估等功能。,并集成了在线查询、近线计算、离线分析和图形学习,让开发者使用起来更加方便。
在网络交易中,最让银行和第三方头疼的就是“套现”这种欺诈行为。
比如一些不良商家会通过银行卡、花坛或者熟人完成一个套现循环。
在过去,挖掘的关系的数量或关系的深度在计算上往往是有限的、困难的和低效的。现在我们可以把这个行为建模成一个图,在图上我们可以发现它形成了一个欺诈的闭环。
当数据量很小时,传统的单图计算机器可以解决这个问题。现在在海量数据的情况下,需要切割超大规模的图,高效存储,需要低时延。
蚂蚁希望在每一笔交易发生时,都能实时检测并阻止这种行为。

另外,现在的诈骗形式也有了新的变化:以前的诈骗非常集中,就在一个人或者一个账号上,通过简单的技术就可以看到特征,通过个体挖掘发现诈骗。
现在是对抗性的,甚至升级为团伙,会租用一些正常交易的合法账号,混入海量交易数据。也许只有中间的交易是欺诈性的,这使得欺诈行为非常隐蔽,很难被发现。
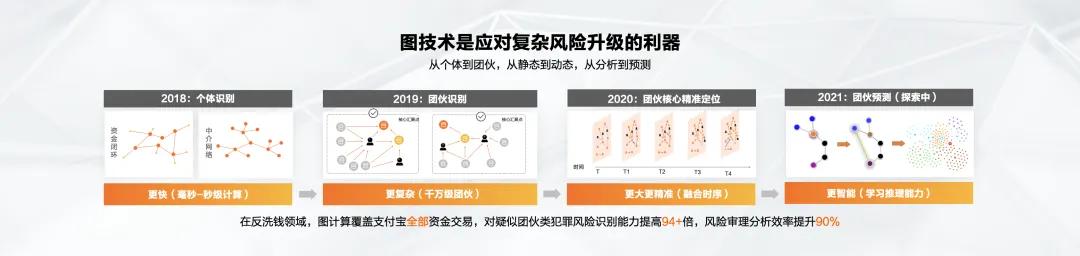
2020年,诈骗手段不仅变成了团伙,而且其团伙还在不断进化,成员也在不断变化。
在观察其按时间演化的过程中,我们可以识别出这些帮派中的一些关键角色,从而更快速准确地定位帮派的核心成员,这就是时序图计算。
这也对蚂蚁底图的计算提出了新的挑战。现在能做的就是被动识别诈骗。未来,蚂蚁希望更进一步,主动预测风险。
反洗钱与许多反欺诈技术非常相似。反洗钱对时效性要求非常高,判断逻辑也越来越复杂。
在洗钱行为中,常见的方法是通过在大宗交易中混合洗钱和拍卖部分艺术品来掩盖洗钱行为。
作案人可能有多个身份和大量账户,且交易频率不高,交易路径非常复杂。可能是正常交易中夹杂了一些可疑交易。
要发现这种欺诈行为并加以制止,需要深入的图分析和图计算能力。
2018年以来,基于一些典型的资金网络、中介网络等欺诈,蚂蚁已经可以实现对应毫秒级的百万分之一吞吐量级别的响应。
传统的在地图上做的方法,但是增加了它的吞吐量,缩短了它的响应时间,可以更快地捕捉到这些行为。然而,使用传统方法的人可能需要几个小时或一天才能完成这些工作,但蚂蚁已经使其像在线一样高效。
2021年,GeaStack应用于蚂蚁集团反洗钱分析,覆盖支付宝所有资金交易,对涉嫌团伙犯罪的风险识别能力提升94倍以上,风险审判分析效率提升90%。
除了金融领域,蚂蚁集团还进行了大量的对外合作。
人工智能时代,NLP、CV、RL等领域已经百家争鸣。作为最前沿的技术高地之一,图计算可以站在未来世界通用人工智能的最前沿。
目前,包括蚂蚁集团在内的国内很多公司在图计算方面的探索已经走在了世界的前列。
人们对技术的探索一直只有一个目标,那就是造福人类。
何昌华表示,“蚂蚁的初心一直是不断探索革命性的技术,同时在一定层面上支持蚂蚁事业,向社会开放成熟的技术,希望它在更多的场景中发挥社会作用。」