
编辑:LRS
【新智元简介】传统的帧内插通常在两幅非常相似的图像之间生成图像。最近Google提出的FLIM模型可以通过对两张运动变化较大的照片进行帧内插生成视频:首次引入了克损失,不仅提高了清晰度,还丰富了细节!
帧内插是计算机视觉领域的一项关键任务。模型需要根据给定的两帧预测合成一个平滑的中间图像,在现实世界中也有很大的应用价值。


帧插值常见的应用场景是改善一些帧率不足的视频。有些设备配有专门的硬件对输入视频的帧率进行采样,使低帧率的视频可以在高帧率的显示器上流畅播放,不需要“闪烁填帧”。
随着深度学习模型越来越强大,帧插值技术可以从正常帧率的视频合成慢动作视频,即合成更多的中间图像。
随着智能手机的日益普及,数码摄影对帧插值技术也有了新的需求。
正常情况下,我们在拍照的时候,一般会在几秒钟内连续拍几张照片,然后从这些照片中选择一个比较好的“拍照秘籍”。
这类画面有一个特点:场景基本重复,主要人物只有很少的动作和表情。
如果在这类图片下进行帧内插,会产生一个神奇的效果:照片动了,变成了视频!通常视频比照片更有代入感和瞬间感。
感觉像“现场照”吗?

但是帧内插的一个主要问题是它不能有效地处理大场景的运动。
传统的帧内插是对帧速率进行上采样,基本上就是对近乎重复的照片进行内插。如果两个画面之间的时间间隔超过1秒甚至更多,就需要帧内插模型能够理解物体的运动规律,这也是当前帧内插模型的主要研究内容。

最近,谷歌研究团队提出了一种新的帧内插模型FLIM,可以在运动差异较大的两幅图片之间进行帧内插。

以前的帧内插模型通常很复杂,需要多个网络来估计光流或深度,以及单个网络专用于帧合成。FLIM只需要一个统一的网络,使用多尺度特征提取器,在所有尺度上共享可训练的权重,并且可以只通过帧来训练,而不需要光流或深度数据。
FLIM的实验结果也证明了其优于前人的研究成果,能够合成高质量的图像,生成更加连贯的视频。和代码预训练模型都是开源的。

地址:https://arxiv.org/pdf/2202.04901
地址:https://github.com/google-research/frame-interpolation
模型架构
FLIM模式的框架有三个主要阶段。
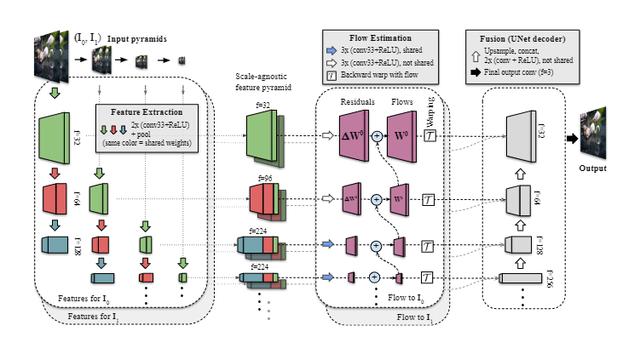
1。与比例无关的特征提取
FLIM特征提取器的主要特点是流量预测阶段的权重共享,可以在粗粒度和细粒度分辨率下得到权重。
首先为两幅输入图像创建一个图像金字塔,然后在图像金字塔的每一层使用共享的UNet编码器构建一个特征金字塔,卷积层用于提取四个尺度的特征。
应当注意,在相同深度的金字塔等级,相同的卷积权重用于创建兼容的多尺度特征。
在特征提取器的最后一步,通过在空之间连接深度不同但维度相同的特征图,构建与尺度无关的特征金字塔。对于最细粒度的特性,只能聚合一个特性图,对于第二细粒度的特性,可以聚合两个特性图,对于其余的特性,可以聚合三个共享特性图。
2。运动/流量估计)/S2/]
提取特征金字塔后,我们需要用它们来计算每个金字塔的双向运动。与先前的研究一样,运动估计从最粗糙的层开始。与其他方法不同,FLIM直接预测从中间框架到输入的面向任务的流程。
根据传统的训练方法,不可能通过使用地面真实光流来计算两个输入帧之间的光流,因为不可能从待计算的中间帧预测光流。但是,在端到端帧内插系统中,网络实际上可以基于输入帧和相应的特征金字塔进行很好的预测。
因此,在每个级别计算的面向任务的光流是从较粗粒度预测的残差和上采样流的总和。
最后,FLIM在中间时间t创建了特征金字塔
3。融合:输出结果图像(融合)
在影片的最后阶段,t时刻的尺度无关特征图和双向运动在每一个金字塔层次上连接起来,然后送到UNet-like解码器合成最终的中间帧。
在损失函数的设计中,FLIM只使用图像合成损失来监督训练的最终输出,在中间阶段不使用辅助损失项。
首先,使用L1重建损失来最小化插入帧和标准帧之间的像素级RGB差异。但是,如果只使用L1损失,生成的插入帧通常是模糊的,其他类似的损失函数训练也会产生类似的结果。
因此,FLIM增加了第二个损失函数,感知损失,以增加图像的细节,并使用VGG-19高级特征L1正则表示。由于每层的感受区域,感知损失在每个输出像素周围的小范围内加强了结构相似性。实验还证明感知损失有助于减少各种图像合成任务中的模糊伪像。
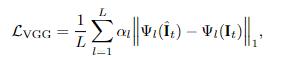
第三种损失是风格损失,也称为克矩阵损失,可以进一步扩大VGG损失的优势。
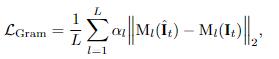
FLIM也是第一个将格拉姆矩阵损失应用于帧内插的人。研究人员发现,这种损失可以有效地解决图像的清晰度,在不透明的情况下保留图像的细节,并消除大运动量序列中的干扰。
为了实现高基准分数和高质量的中间帧合成,最终损失同时使用三个损失加权和,每个损失的权重由研究人员根据经验设定。前150万次迭代的权重为(1,1,0),后150万次迭代的权重为(1,0.25,40)。超参数通过网格搜索自动调整。
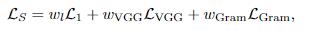
研究者从指标量化和生成质量两个方面评价FLIM网络。
使用的数据集包括Vimeo-90K、UCF101和Middle- bury,以及最近提出的大运动数据集Xiph。研究人员使用Vimeo-90K作为训练数据集。
量化指标包括峰值信噪比(PSNR)和结构相似图像(SSIM)。分数越高,效果越好。
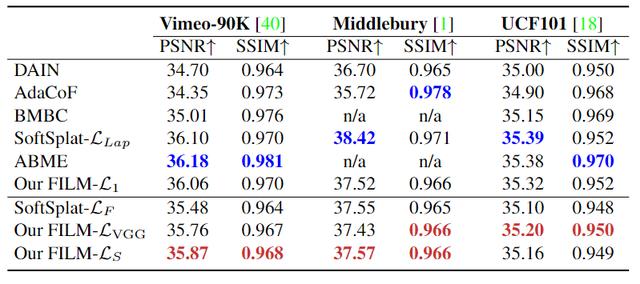
感知失真权衡表明,只有最小化失真指标,如PSNR或SSIM,才会对感知质量产生不利影响。帧内插研究的多目标是获得低失真、高感知质量和时间相干的视频。因此,研究人员使用本文提出的基于Gram矩阵的损失LS来优化模型,这对失真和感官质量都有好处。
当包括感知灵敏度的损失时,Vimeo-90K上的胶片性能优于最先进的SoftSplat。我在米德尔伯里和UCF101上也拿到了最高分。
在质量对比方面,首先从清晰度的角度,为了评价基于Gram矩阵的损失函数在保持图像清晰度方面的有效性,将FLIM生成的结果与其他方法呈现的图像进行了直观的对比。与其他方法相比,FLIM合成的效果很好,面部图像细节清晰,保留了手指的关节。

在帧插值中,大多数被遮挡的像素应该在输入帧中可见。根据运动的复杂程度,有些像素可能无法从输入中获得。因此,为了有效地掩盖像素,模型必须学习适当的运动或生成新的像素。结果表明,与其他方法相比,该影片在保持清晰度的同时正确地绘制了像素。它还保留了物体的结构,比如红色的玩具车。另一方面,软板是变形的,ABME在画面中产生模糊的画面。

大运动是帧内插中最困难的部分之一。为了扩大运动搜索的范围,模型通常采用多尺度方法或密集特征图来增加模型的神经能力。其他方法是通过训练大规模运动数据集实现的。实验结果表明,SoftSplat和ABME可以捕捉到狗鼻子附近的运动,但在地面上会产生很大的伪影。胶片的优点是可以很好地捕捉运动,保留背景细节。

参考资料:
https://film-net.github.io/







