机器心脏报告
编辑:陈平和周晓
AI会是未来的“创造者”吗?
最近,视觉合成的任务引起了广泛关注。前几天Nvidia的GauGAN刚刚更新了2.0版本,现在也流行一种新的视觉合成模型Nüwa(女娲)。
与GauGAN相比,“女娲”的生成方式更加多样,不仅包括文字涂鸦生成图像,还包括从文字生成视频。

随着VQ-VAE(一种离散的VAE方案)的出现,高效大规模的预训练逐渐应用于视觉合成任务,如DALL-E(图像)和GODIVA(视频)。尽管这些模型取得了巨大的成功,但仍然存在一些局限性——它们分别处理图像和视频,并专注于生成其中的一个,这限制了模型从图像和视频中受益。相比之下,“女娲”是一个统一的多模态预训练模型,在包括图像、视频处理在内的8个下游视觉任务上具有出色的合成效果。

地址:https://arxiv.org/pdf/2111.12417.pdf
GitHub地址:https://github.com/microsoft/NUWA
车型概述
这项研究提出了一个通用的3D transformer-encoder-decoder框架(如下图所示),该框架同时涵盖了语言、图像和视频,可用于多种视觉合成任务。该框架由一个以文本或视觉草图作为输入的自适应编码器和一个由八个视觉合成任务共享的解码器组成。
《女娲》整体结构图。
该框架还包括3D附近注意(3DNA)机制,以考虑空和时间之间的局部特征。3DNA不仅降低了计算复杂度,还提高了生成结果的视觉质量。与几个强大的基线相比,“女娲”在文本到图像生成、文本到视频生成、视频预测等方面取得了SOTA成果。此外,“女娲”还表现出了惊人的零样本学习能力。
“女娲”的八种跨模态合成模式是:
文本到图像:

图像涂鸦:

图像完成:

基于文本编辑图像:

文本到视频:

视频预测:

涂鸦转视频:


根据文本编辑视频:

实验结果
通过几个实验对合成结果进行了评价。
首先,研究人员在三个数据集上对“女娲”进行了预训练:用于文本-图像(T2I)生成的概念标题,包括29m文本-图像对;视频预测的时间瞬间(V2V),包括727K视频;用于文本-视频(T2V)生成的VATEX数据集,包括241K文本-视频对。
与SOTA方法相比
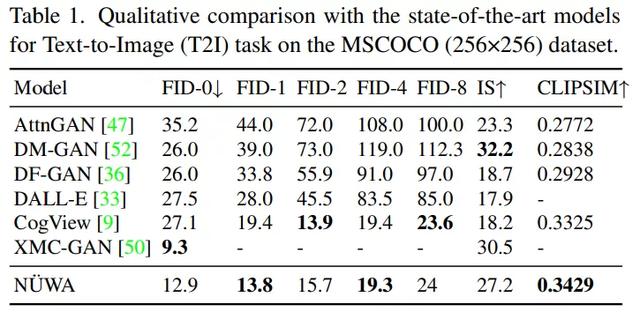
文本-图像(T2I)微调:本研究比较了“女娲”在MSCOCO数据集上的性能,如表1和图3所示:在表1中,“女娲”明显优于CogView,FID-0为12.9,CLIPSIM为0.3429。虽然XMC-甘的FID-0是9.3,比女娲好,但女娲可以生成更逼真的图像,如图3所示。尤其是最后一个例子,“女娲”生成的男孩脸更清晰,男孩旁边的气球也很逼真。

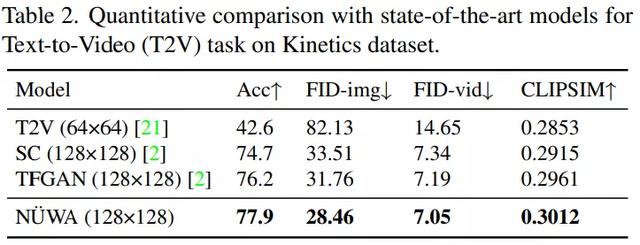
文本-视频(T2V)微调:本研究在动力学数据集上对“女娲”进行了评估,结果见表2和图4。在表2中,“女娲”在各项指标中都取得了最好的表现。
在图4中,研究还表明女娲拥有强大的零样本生成能力,可以生成前所未见的图像,比如在游泳池打高尔夫,在海里跑步:

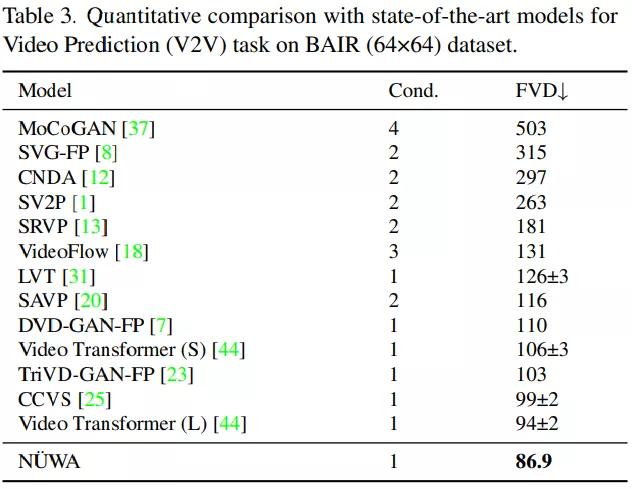
视频预测(V2V)微调:在这项研究中,女娲与BAIR机器人推送数据集上的其他模型进行了比较,结果如表3所示:为了进行公平的比较,所有模型都使用64×64分辨率。虽然只给出一帧作为条件(Cond。),女娲还是把SOTA·FVD的分数从94 2降到了86.9。
Sketch-image (S2I)微调:这项研究是在MSCOCO stuff上进行的,如图5所示。与驯服-变形金刚和铁锹相比,女娲制作了种类繁多的逼真汽车,连公交车车窗的倒影都清晰可见。

图像补全(I2I)零样本评价:给定塔的上部,相比驯服变形金刚模型,女娲可以对塔的下部产生更丰富的想象,包括周围的建筑、湖泊、花草树木、山峦等等。
文本引导图像处理(TI2I)零样本评测:“女娲”展现了其强大的处理能力,能够在不改变图像其他部分的情况下生成高质量的文本一致性结果。
消融实验
图5示出了文本到视频(T2V)生成任务中多任务预训练的有效性。该研究是在具有挑战性的数据集MSR-VTT(带有自然描述和真实视频)上进行的。女娲的FID-vid是47.68,CLIPSIM是0.2439。
图9示出了文本引导视频处理(TV2V)。第一行显示原始视频帧,潜水员正在潜水;潜水员的第二个行为是游向水面;第三行显示潜水员可以游到海底。如果我们要生成一张潜水员飞上天的图片空?“女娲”可以实现。从图中可以看出,潜水员像火箭空一样飞向天空。