
在数据查询业务中,有时会遇到数据量很大的列表报表。因为用户输入的查询条件可能非常宽泛,会从数据库中找到上亿甚至上亿行的记录,包括银行流水记录、物流明细等等。如果等检索完这些记录再生成报告,时间会很长,用户体验自然会很差。而且报表一般都是使用内存操作机制,大多数情况下内存是没有空间容纳这么多数据的。所以我们通常会使用分页呈现的方式,以最快的速度呈现第一页,然后用户可以随意翻页,一次只显示一页,不会造成内存溢出。
传统分页呈现的实现通常使用数据库的分页机制,使用数据库提供的语法返回指定行号范围内的记录。界面根据当前页码(每页显示固定行数)计算行数范围作为参数拼写成SQL,数据库只会返回当前页面的记录,从而达到分页呈现的效果。
然而,这样做有两个问题:
1。翻页时效率低
这样呈现第一页一般会快一些,但是回头的时候会再次执行使用过的检索SQL,跳过上一页涉及的记录。对于一些没有OFFSET关键字的数据库,接口只能自己跳过数据(取出后丢弃),而比如ORACLE在用序列号过滤之前,还是需要一个子查询来生成序列号。这些行为会降低效率,浪费时间。前几页不明显,但如果页数大,翻页时会有等待感。
2。可能存在数据不一致
这样翻页的时候,每次按页取数都需要独立发出SQL。这样,如果数据检索的两个页面之间存在插入和删除动作,那么检索到的数据反映的是最新的数据情况,可能与原页码不符。例如,每页有20行。在取出第一页之后,但在用户翻到第二页之前,包含在第一页中的20行中的一行被删除。那么用户翻页时取出的第二页第一行实际上是删除前的第22行记录,原来的第21行实际上落到了第一页。如果你想看,你必须翻回第一页才能看到。如果要根据提取的数据做汇总统计,会有误差,结果不一致。
为了克服这两个问题,有时我们使用另一种方法,使用SQL游标从数据库中提取数据。在取出一页进行展示后,我们并不停止这个光标,在翻到下一页时继续取数据。该方法能有效克服上述两个问题,翻页效率高,无不一致现象。但是绝大多数数据库游标只能单向从前到后取数据,也就是说只能在界面上翻页,很难向业务用户解释,所以很少使用这种方法。
当然,我们也可以将这两种方法结合起来,在翻页时使用光标,一旦需要翻页就再次执行检索SQL。这将比每次分页都重新检索数据的体验要好,但它并没有从根本上解决问题。
润乾报告计划
下面介绍的润乾报表方案提供了大报表功能,支持海量列表报表的二级查询。在这个方案中,两个异步线程用于获取和渲染。发送SQL后,取数线程保持取数并缓存在本地,渲染线程从本地缓存中取数显示。这样,已经取出并缓存的数据可以快速呈现,无需等待。但是数据检索线程中涉及的SQL在数据库中保持相同的事务,不会出现不一致的情况。上面提到的两个问题都完美解决了。
同时,借助于设置的文件存储格式,报表还可以按行号随机访问记录,而不是每次都通过遍历来查找数据。也就是说,这种存储格式支持跳转到任意页面访问,从而大大提升了用户体验。但是由于异步机制,页面端显示的总页数和记录数会随着检索过程而变化。
大列表报表的操作原理:
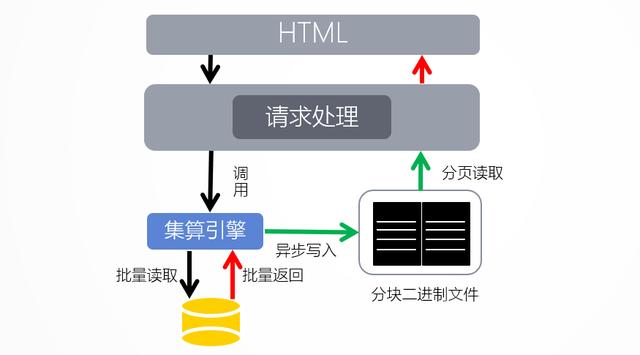
需要注意的是,大规模列表报表中使用的异步机制和集合文件存储都是在集合收集器的基础上实现的,因此该功能需要“集成集合收集器”功能的支持,而润乾报表基础版中并不包含该功能。
下面举例说明润乾海量大名单报表(以下简称“大报表”)的开发和使用过程。
SQL源报告
首先我们来看一个基本的大型报表,即报表数据来自数据库。在示例中,我们需要根据日期范围查询订单表的交易信息。由于数据规模庞大,我们需要使用大型列表报告来呈现它。
制作报告模板
就像正常的报表开发一样,设置参数,准备数据集,绘制报表模板。
报告参数是查询日期的开始和结束日期:

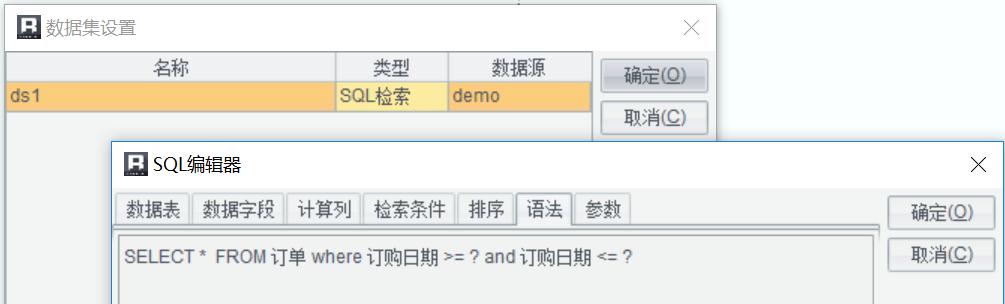
根据数据集参数查询订单表SQL:
报告模板:

设置大型数据集
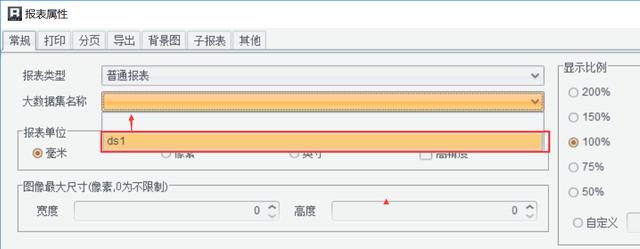
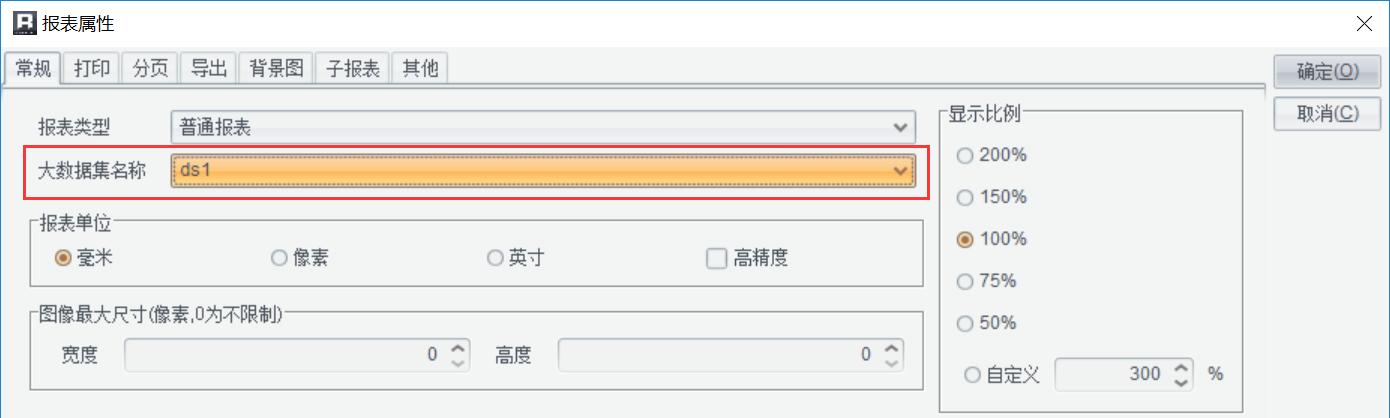
与普通报表不同,需要在润乾的报表属性(报表-报表属性)中设置“大数据集名称”,指向数据集ds1,直接使用SQL完成异步检索。
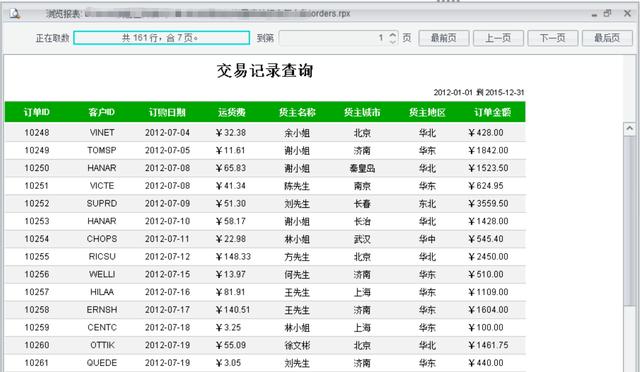
设置完成后,您可以在报表设计器IDE中浏览报表:
发布到WEB
与普通的报表发布类似,大列表报表也是通过JSP以tag-lib的形式发布的。
& lt报告:big name = " report 1 " report filename = " & lt;% =报告% >
needScroll = " & lt%=scroll% >
params = " & lt% = param . tostring()% & gt;"

exception page = "/report JSP/my error 2 . JSP "
scrollWidth="100% "
scrollHeight="100% "
rowNumPerPage="20 "
fetchSize="1000 "
needImportEasyui= "否"
/& gt;
& lt报告:big name = " report 1 " report filename = " & lt;% =报告% >
needScroll = " & lt%=scroll% >
params = " & lt% = param . tostring()% & gt;"
exception page = "/report JSP/my error 2 . JSP "
scrollWidth="100% "
scrollHeight="100% "
rowNumPerPage="20 "
fetchSize="1000 "
needImportEasyui= "否"
/& gt;
RowNumPerPage属性是每页显示的记录数;FetchSize是一次从数据源读取的数据量。发布的JSP可以参考报表安装目录下的示例文件:[reportwebappdemoreport JSP showbigreport . JSP]。
WEB渲染效果:
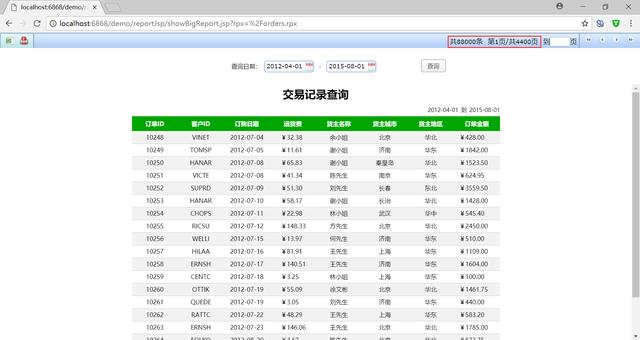
可以注意到,右上角的页码和记录总数是随着异步线程读取数据而不断变化的。
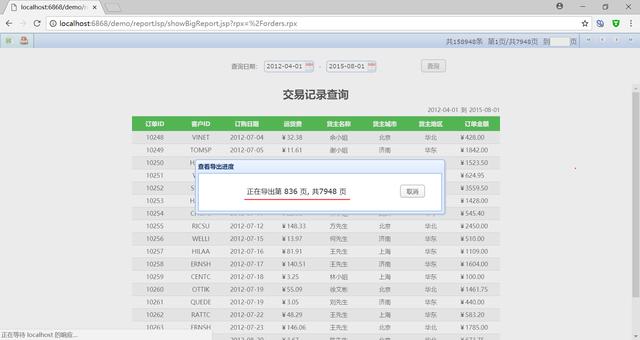
除了显示,润乾报告还支持导出Excel和打印大型列表报告。
导出
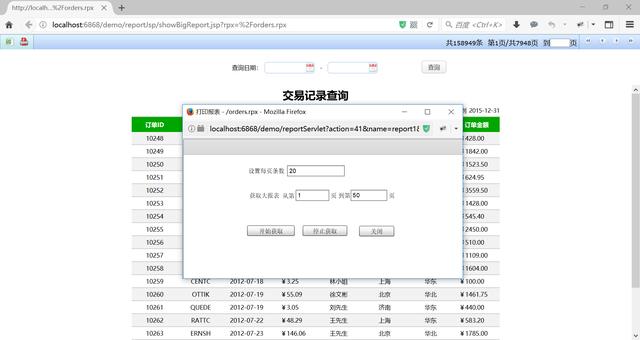
打印
非SQL源大型报表
当海量数据的来源不是RDB时,由于无法使用数据库分页,无法通过SQL实现异步大报表。为了解决这个问题,在润乾报表的大报表方案中,采用了两级异步线程,由集中器定义的数据取数线程负责从非RDB数据源取数并缓存数据,然后由渲染线程负责读取缓存并分页显示。
下面以文件数据为例,介绍非RDB数据源的大型报表的开发过程。示例中的卫星数据存储为文件(CSV ),这是一个典型的大规模非RDB数据源。现在,我们需要根据日期查询某一天的风速、温度等详细信息。
报告数据准备
首先,我们在润乾报告的集中器数据集的帮助下读取文件数据,并返回报告的光标。集中器SPL脚本如下:
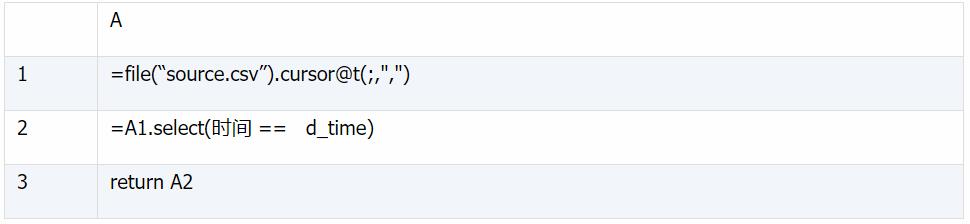
A1。创建文件光标;
A2执行光标时过滤数据(此时光标尚未执行,数据尚未取出);
A3返回光标过滤结果,为报表提供数据。
将SPL脚本保存为bigReport-file.dfx,并将其作为数据集引入报表:
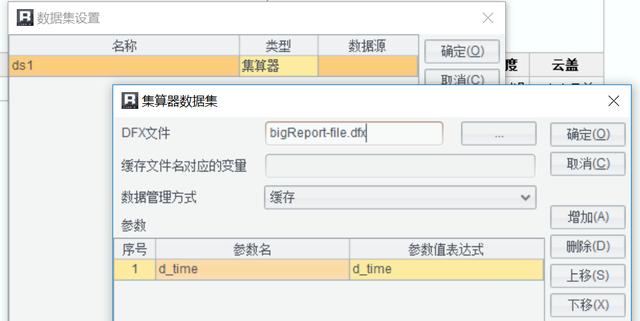
设计报告模板
接下来,我们根据准备好的数据制作一个报表模板:

同时设置大型数据集:
发布到WEB
然后,将完成的报告发布到网站上:
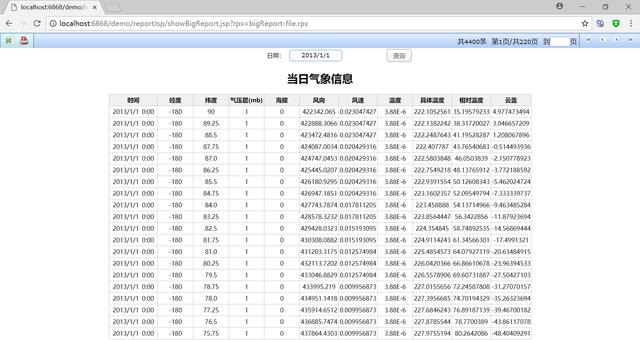
这不是很简单吗?这个例子说明,如果报表开发涉及到大量的非RDB数据,润乾报表可以在集中器对各种数据源类型的支持下,实现大型报表的开发和展现。
使用大型报表时的注意事项
以上介绍了开发大报表的正确姿势,但任何功能都不是万能的,使用大报表有几点需要注意:
1。没有排序
大型报表的数据集相对较大。如果你在乎响应时间(谁在乎),就尽量不要把数据集全表排序(注意我指的是全表排序)。毕竟,排序后要过很长时间才能给他们看...
2。不适合高并发情况
大报表采用异步机制,将数据批量加载到内存中再呈现到前端,减少了内存占用,但同时增加了CPU和磁盘的I/O负载。当并发度高时,CPU和硬盘可能会成为瓶颈,影响呈现效果,所以大报表不适合高并发场景。
本文主要介绍了RDB和非RDB数据源下大列表报表的开发方法。在下一章“百万分组大报表的开发与展现”中,我们将进一步介绍带汇总值的大报表和分组大报表的实现过程。







