本文转载自微信公众号“硅星人”(ID:guixingren123),文|谱。
关于神经机器翻译,给个科普教育。
为了微信的一个bug,坤的粉丝几乎和腾讯势不两立。
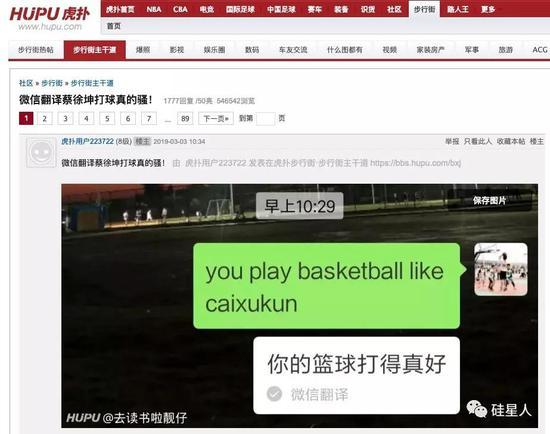
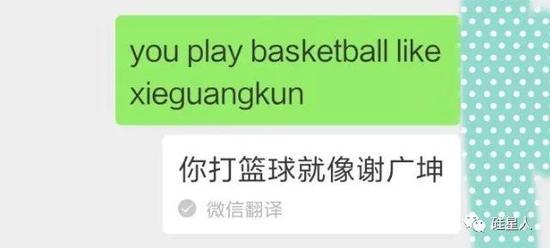
上周末,微博、知乎、豆瓣、虎扑等社交网络上发布了一组“神翻译”在微信上的截图。有人输入“你打篮球像蔡徐坤”这样的句子,使用了微信的翻译功能,但是得到了一个完全错误的翻译:
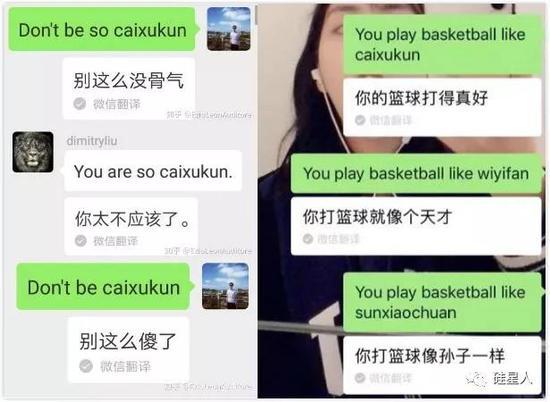
其他遭受微信翻译调戏的男明星包括吴亦凡和谢广坤。
坤是目前中国娱乐圈的头号明星,他的粉丝绝对不是好惹的。
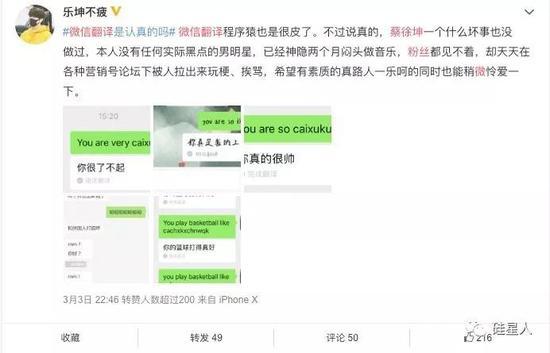
目前微信团队已经部分下线了翻译功能。根据四行人的实际测量,像“you are so”这样的句子和涉及“蔡徐坤”这样的词的句子已经不能翻译成中文了。
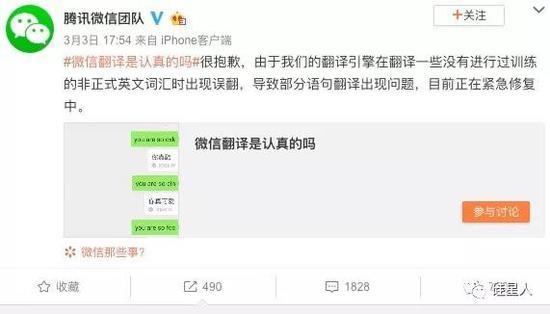
与此同时,官方账号@腾讯微信团队也在微博上宣布,正在紧急修复翻译功能。截至记者发稿时,相关声明仍无法通过微信正常翻译。
注意,微信官方提供了简短说明:
翻译引擎正在翻译一些没有经过训练的 非正式英语单词
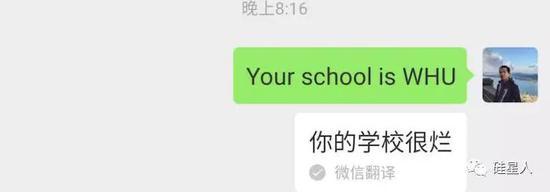
在“蔡徐坤”之后,一些网民发现了更多会引发bug的词。比如微信翻译在大学英语缩写上的表现似乎很差。键入“你的学校是WHU”,但你不能翻译武汉大学,但你给出的结果是“你的学校很烂”。
没多久,学校的句型就翻译不出来了。
硅星认为,微信应该更详细的告诉我们:为什么会出现这个bug,是什么因素造成的?
一方面,微信翻译背后的技术真的很复杂。解释一下有助于用户理解它的工作原理,明白这个翻译结果背后可能有非常复杂的技术原因。
另一方面,你把“你就是这样”这句话关掉,学校的缩写就会出现;关闭学校缩写后,会发现更多能触发bug的词。找到就关一次?这样会伤害正常使用翻译功能的用户的体验,长远来看也不是解决之道。
可惜微信表示不会在微博上多做评论(可能是不想再惹恼坤迷了)。)同时,中国互联网上对此事也没有可靠的技术答案。甚至在知乎上,用户也在相关话题下分享自己发现的bug截图,没有人解释原因。
既然这样,为什么不让四星人试试呢?
我们采访了多位机器学习专家,在接下来的几页中,我们1)解释了微信翻译中使用了什么技术;2)再试着回答一遍“你打篮球像蔡徐坤”这句话,为什么在微信翻译中会翻译错?

微信翻译用的是什么技术?
经过多方了解,司星人确信微信的英汉翻译系统是基于机器学习领域流行的“神经机器翻译”(简称NMT)技术,由微信AI团队自主研发。
从外行人的角度来看,NMT在翻译一个句子时做了这些事情:
第一步:NMT在一定程度上模仿人脑的思维方式,根据一个词在整句(可以是长句)中的上下文,为其建立神经网络模型,形成语义表征。
例如,英语中的单词“dog”可以理解为NMT在其“大脑”中形成了狗的印象。
第二步:根据句子甚至段落中的上下文,将模型重新翻译成另一种语言。
比如dog翻译成法语就是“Le Chien”;但如果语境是“一只狗生了一只小狗”,那么这只狗就会被翻译成否定的“la chienne”。
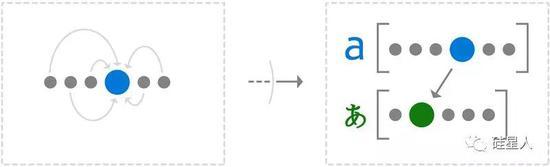
(NMT并没有真正在大脑中形成狗的视觉印象。事实上,整个过程与图像完全无关。这种所谓的“印象”是由一系列矢量表达的。狗的例子来自微软翻译器[1])
NMT的主要优势是对长句(甚至是段落)有很好的翻译能力,阅读时上下文连贯程度接近人工翻译。NMT问世后,逐渐被微软、谷歌、百度、腾讯等大公司的翻译产品采用。
“机器翻转技术一直在不断迭代更新。以前是基于规则,过去十年主要是基于统计。现在我们开始使用神经网络。神经机器翻译是目前机器翻译领域的一个热点技术。我们大部分大型语言的翻译都是基于这种技术,”美国一家顶级科技公司研究部门的高级研究员王夏*告诉《硅星》。
“在倒装技术发展的每个阶段,研究人员都会遇到一些问题。NMT也有一些问题,例如,整个过程的可解释性很低,”他说。
在具体案例层面,为什么一个NMT系统会把一句abcde翻译成ABCDE?目前,研究者很难解释清楚翻译过程。

这句话为什么会转错?
如果NMT错了,会发生什么?
事实上,错误是否严重是由人决定的。在机器眼里没有对错,选出的答案是机器认为概率最高或者可能性最大的答案,因为一切都是按照模型和算法运行的。
只有接受了这一点,你才能明白这句话为什么是错的。
接下来,进入正题。
可能的原因1:训练集噪音
《硅星》采访的大部分机器学习专家都投了这个理由。
形象地说,噪音就是训练翻译系统的数据集中“不正确”和“脏”的数据。
训练一个优秀的NMT系统需要大量高质量的 平行语料库数据——“高质量”指的是准确翻译,“平行语料库”指的是英汉句子,“我爱你=我爱你”等等。
我们去哪里找这些数据?英汉词典是一个来源。另外,最流行的方式是从全网的大量数据中抓取高质量的平行语料库。
“你打篮球像蔡徐坤”已经被翻译成“你打篮球打得真好”。噪音是从哪里来的?硅人的发现有两种可能性:
例如,互联网上已经存在大量“蔡徐坤=好”的语料库。这些语料库在爬取中被微信翻译用作平行语料库。但实际上属于“噪音”,因为在翻译的语境中,关联无法建立,准确性无法保证。微信未来可能会在类似领域加强去噪。
创办了一家机器学习公司的陈晗*指出,在训练过程中,微信翻译团队成员可能会使用生成攻击性攻击的方法,手动添加类似的噪音,并在训练过程中主动纠正类似的翻译结果,最终干扰了翻译结果——这是一种可能的情况,动机我们不做推测。

一个用噪声干扰计算机视觉图像识别的例子:人类无法识别的图片,被深度神经网络识别为不同的物体。例子与本文主题无关,仅供参考。
在存在噪声等异常情况下,系统仍能正常训练和工作并给出高质量的翻译结果——这种能力在计算机科学中被称为“鲁棒性”。
王夏指出,鲁棒性应该得到NMT和未来机器翻译技术的提高和重视。
可能的原因2:多余的单词
一种可能的情况是“蔡徐坤”这个词从未出现在微信用于翻译训练的数据集中。
当NMT遇到集合之外的单词时,它可以分解来寻找集合之内的单词。这个拆卸过程也是随机的。比如可能被拆解成caix ukun,得到的依然是多余设置的单词。
外来词翻译不好很正常。没看过就不翻,有偏差也在情理之中。
可能的原因3:域不匹配
“另一种可能的情况是域名不匹配,”王夏说,并指出这不一定是一个具体的情况。
在这个具体案例中,篮球出现在句子中,而微信翻译的训练数据集可能不在篮球领域,或者很少与篮球相关。一个不匹配的字段,再加上句子中一个额外设置的单词,共同导致翻译结果难以正确。
这个解释行得通。比如,商业是大部分微信用户使用翻译的原因,所以微信在训练NMT时可能会使用贸易领域的数据集;篮球不是微信翻译用户的主要场景,所以可能训练中没有篮球数据集。
出了问题不能怪它,因为集合外的词和域不匹配。怎么可能是你没学过的东西?

微信AI官方网站
可能原因四:陌生词语+无法引入常识

这个原因也是NMT的工作原理造成的。
NMT非常擅长翻译长句、段落甚至整篇文章。由于它的机制,一个词的翻译可以符合语境的上下文。
但在短句中,不一定管用——尤其是当句子一点都不通顺的时候。
可能因为在“你打篮球像蔡徐坤”这句话里,蔡徐坤是一个很奇怪的词。它不出现在任何一本英语词典中,而且似乎与句子的上下文无关。
微信翻译的培训可能发生在坤成为NBA中国新年大使之前。
人类在翻译时,可以参考已有的常识和知识,不会翻译也可以查资料。NMT不能这么做。当它工作时,它没有一个共同的知识库可以参考。
而且,也不是说微信做不好——现在我们用同一句话测试Google Translate,结果并不完全令人满意。
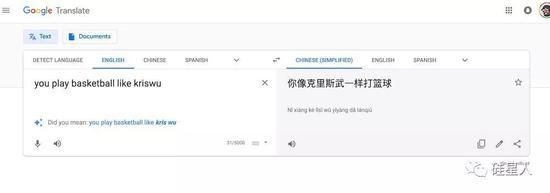
“这个问题(不能引入常识)不仅体现在翻译任务上,还包括阅读理解、问答等任务。如何改善这一点是一个非常有趣的方向,每个人都还在探索,”王夏说。
那么,微信做错了吗?[/s2/]
如果出现上述情况,就不可避免地会导致翻译错误,因为这就是NMT的作品。即使这不会发生在微信上,也会发生在谷歌翻译或任何其他基于NMT的翻译产品上。从这个角度来说,微信这个产品本身没有任何问题。
但是微信团队也不是完全无辜的。因为除了技术,bug也可能是流程控制上的问题。
在一个9亿用户的国民App中,任何功能的开发都要经过认真的论证,上线前都要有严格的测试,尽量保证万无一失。但微信前工程师曾透露,至少微信翻译上线时不是这样。
这时候,智湖的工程师这样回答:
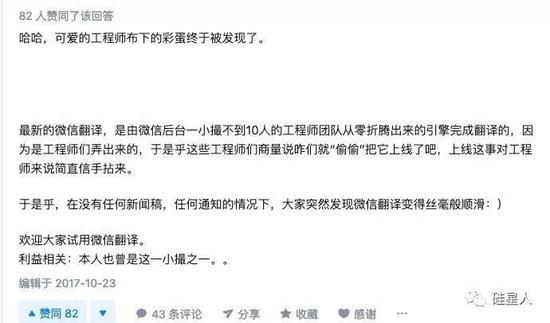
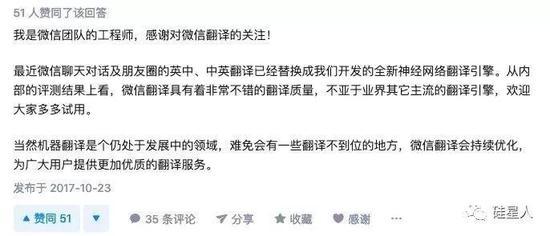
腾讯/微信已经不是第一次出现这个问题了。
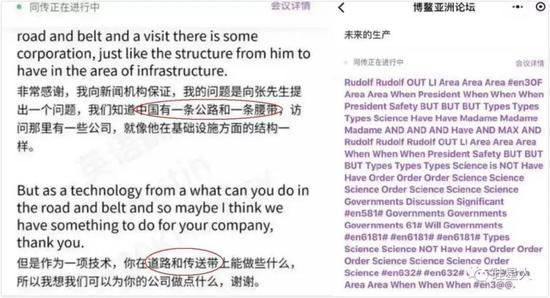
去年腾讯AI负责博鳌亚洲论坛同声传译,直接带来了基于seq2seq的机器翻译系统。先是把“一带一路”翻译成“一路一带”和“道路和传送带”,然后就干脆罢工了。
“数据量大,活的糙,敢做。”
这是陈晗对这个微信翻译bug的评价。
一位不愿透露姓名的范昆在接受四星人采访时表示,不希望看到有人通过技术手段纵容针对艺人的网络暴力。
“艺人是无辜的,这样的翻译本身就会对艺人产生负面影响。但网友的群体嘲讽可能会给艺人带来二次心理伤害,”她说。“这次微信官方的回应很快,也很好。我希望微信是无害的,希望所有的国民app和社交媒体都有一个基本的道德底线。”
所以,

*王夏和陈晗是化名。