
在多维分类(MDC)中,输出空间中包含多个类别变量,每个类别变量对应一个异构的类别空间。由于类别空间的异构性,在从MDC样例中学习预测模型时,考虑类别变量之间的依赖关系非常具有挑战性。本文提出了一种新的名为SLEM的多维分类方法,它在编码的标记空间而非原始的异构标记空间中学习预测模型。具体来说,SLEM方法工作流程可以分为编码-训练-解码三个阶段。编码阶段通过成对分组、独热转换和稀疏线性编码三种级联操作,将每个类别向量映射为实值向量。训练阶段则在编码所得标记空间内学习了一个多输出回归模型。解码阶段通过改进正交匹配追踪算法对多输出回归模型的预测输出进行稀疏重构,得到未见示例的预测类别向量。实验结果清楚地显示了SLEM方法相对于已有MDC方法的优越性。
本期AI TIME PhD直播间,我们邀请到东南大学博士生——贾彬彬,为我们带来分享《基于稀疏标记编码的多维分类方法》。
贾彬彬:从2017年9月开始在东南大学计算机科学与工程学院攻读博士学位,主要研究方向为多维分类(Multi-Dimensional Classification),目前发表CCF A类期刊1篇、会议3篇,CCF B类期刊3篇,CCFC类会议1篇。
01
背 景
在本文中,我们主要关注多维分类(Multi-Dimensional Classification,MDC)问题。为了更好地理解多维分类的定义,我们首先将多类分类(Multi-Class Classification,MCC)与多维分类进行对比。如下图所示,在多类分类中每个示例仅对应一个类别变量,而在多维分类中,每个示例对应多个类别变量。

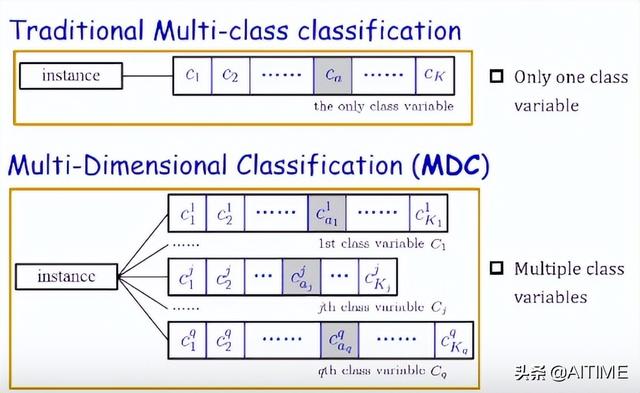
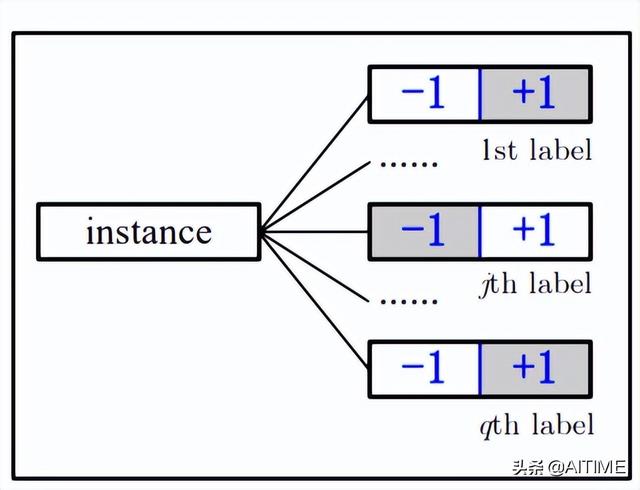
对于学术界研究较多的多标记分类(Multi-Label Classification, MLC), 它输出空间中的标记可以看作是多个类似于MDC的二进制类别变量,如下图所示。但从概念上讲,MLC中的所有标记都属于同一个类别空间。也就是说,MDC与MLC主要的不同之处在于:MDC通常假设语义空间是异构的,而MLC通常假设语义空间是同构的。
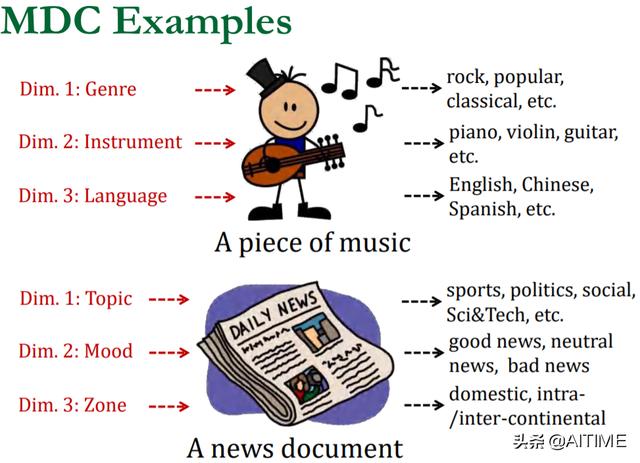
下面举两个关于MDC的例子来帮助我们进一步理解多维分类的概念。在对一段音乐进行分类时,可以根据流派、乐器、语言等多个角度进行分类;在对一篇新闻文本进行分类时,亦可以根据主题、情感、区域等多个角度进行分类;两个例子中提到的分类的“角度”就是多维分类中我们所说的维度:
下面是MDC的已有工作,这些工作都是在原始输出空间学习预测模型,而我们提出的SLEM方法则是关注在变换的标记空间中学习预测模型。

02
方 法
我们提出了Sparse Label Encoding for MDC(SLEM)方法,该方法在变换的输出空间中学习MDC模型。
首先我们给出MDC问题的正式定义,如下图所示。

SLEM方法包含三个阶段:编码-训练-解码。

在编码阶段,将符号型类别向量转换为实值的类别向量。编码阶段总共有三个步骤:Pairwise grouping(成对分组)、One-hot conversion(独热转换)、稀疏线性编码。第一步成对分组是将输出空间转换到输出空间,如下图所示,目的是让独热转换的结果更加稀疏。
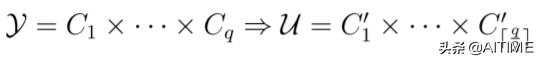
第二步独热转换将类别空间转换到二进制空间,以方便后面的数值计算操作。
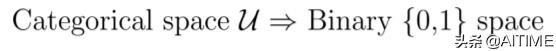
第三步稀疏线性编码将二进制空间转换为实数值空间,将独热转换得到的相互独立的标记表示转换为整体的表示。
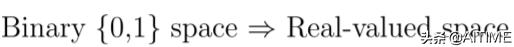
在训练阶段,我们在编码所得标记空间内学习了一个多输出回归模型。在解码阶段,基于多输出回归模型的预测输出通过执行编码阶段的逆运算来确定未见示例的预测类别向量。
03
实 验
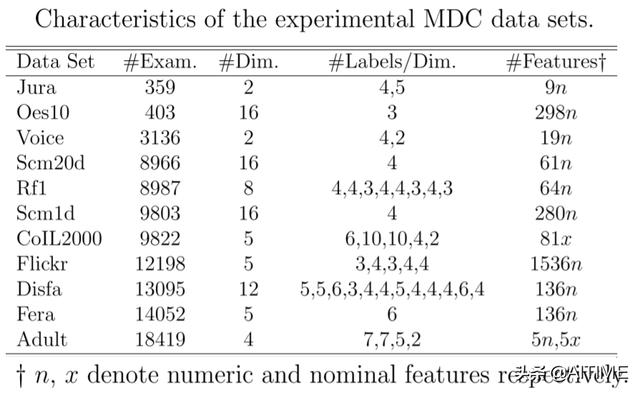
数据集:数据集总共11个,样本个数从300+到18000+,如下图所示。
评价指标:采用了Hamming Score、Exact Match、Sub-Exact Match三个评价指标。

对比算法:

实验结果:
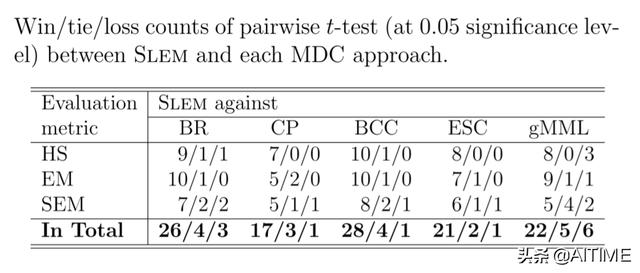
下面给出的实验结果是一个win/tie/loss的实验结果,详细实验结果参见论文;可以看到,相比于五种对比方法,SLEM方法在总共144个配置中的132个配置上取得了更优或者至少相当的结果。
提
醒
论文链接:
https://dl.acm.org/doi/abs/10.1145/3447548.3467397
https://aclanthology.org/2021.naacl-main.242/







